一.HBase2.0和阿里云的前世今生
ApsaraDB for HBase2.0于2018年6月6日即将正式发布上线啦!
ApsaraDB for HBase2.0是基于社区HBase2.0稳定版的升级,也是阿里HBase多年的实践经验和技术积累的持续延伸,全面解决了旧版本碰到的核心问题,并做了很多优化改进,附加HBase2.0 开源新特性,可以说是HBase生态里的一个里程碑。
HBase在2007年开始发布第一个“可用”版,2010年成为Apache的顶级项目,阿里巴巴集团也在2010当年就开始研究,于2011年就已经开始把HBase投入生产环境使用,并成为阿里集团主要的存储系统之一。那个时候HBase已经运行在上千台级别的大集群上,阿里巴巴可以说算是HBase当时得到最大规模应用的互联网公司之一。从最初的淘宝历史交易记录,到蚂蚁安全风控数据存储,HBase在几代阿里专家的不懈努力下,HBase已经表现得运行更稳定、性能更高效,是功能更丰富的集团核心存储产品之一。
阿里集团自2012年培养了第一位“东八区” HBase Committer,到今天,阿里巴巴已经拥有3个PMC,6个Committer,阿里巴巴是中国拥有最多HBase Committer的公司之一。他们贡献了许多bug fix以及性能改进feature等,很可能你在用的某个特性,正是出自他们之手。他们为HBase社区,也为HBase的成长贡献了一份宝贵的力量。当然,也孕育了一个更具有企业针对性的云上HBase企业版存储系统——ApsaraDB for HBase。
ApsaraDB for HBase2.0是基于开源HBase2.0基础之上,融入阿里HBase多年大规模实战检验和技术积累的新一代KV数据库产品,结合了广大企业云上生产环境的需求,提供许多商业化功能,比如 HBase on OSS、HBase云环境公网访问、HBase on 本地盘、HBase on 共享存储、冷热分离、备份恢复、HBase安全机制等等,是适合企业生产环境的企业级大规模云KV数据库。
ApsaraDB for HBase2.0,源于HBase,不仅仅是HBase!
二.深入解读云HBase架构
ApsaraDB for HBase2.0是建立在庞大的阿里云生态基础之上,重新定义了HBase云上的基础架构,对企业云上生产需求更有针对性,满足了许多重要的云上应用场景。其中最常见的有:存储计算分离、一写多读、冷热分离、SQL/二级索引、安全等。下面针对这些场景简单介绍一下ApsaraDB for HBase2.0的基础架构。
2.1 存储计算分离
早期存储和计算一般都是一起的,这样做带来的好处是数据本地化,不消耗网络资源。但是这会带来一个问题,给应用企业对集群起初的规划带来一定的难度,如果一开始使用过大的存储、过大的计算资源,就是一种浪费,但是如果开始规划存储、计算过小,后期运维升级扩展有变得非常复杂,甚至升级/扩展过程会出现故障等等问题,这些都不不企业业务发展规划不可忽略的问题。
随着网络技术的发展,现在已经进入25G甚至100G以上时代,网络带宽已经不再是瓶颈。ApsaraDB for HBase2.0建立在阿里云之上,利用阿里云强大基础技术,实现了云上HBase的高性能存储计算分离的架构。

如上图所示,分布式region如上图所示,分布式region计算层负责HBase相关的数据库逻辑运算操作; 通过分布式HDFS&API接口读写远端底层分布式文件存储系统;其中远端读写质量和安全隔离由QOS层保障,QOS层利用高性能硬件加速远端读写性能,保障了存储分离的性能、安全要求;最终读写落到分布式存储层,分布式存储层通过副本形式保障数据安全可靠,可以容忍单节点、单rack fail的数据可靠性。云上HBase计算存储分离架构的实现,使得用户集群规划则变得简单很多,存储容量动态扩展,计算资源动态升配。基本不需要估算未来业务的规模了,真正做到按需使用,帮助用户在业务运行之初就开始尽可能地降低成本,同时又可以随时满足业务发展导致资源的弹性扩展的需要。
2.2 冷热分离/分级存储
一般企业随着业务数据不断增长,数据量开始变大,这个时候就需要对数据进行冷热程度区分对待,以优化系统整体运行效率,并降低成本。举个例子,如:冷数据写入一次后,可能很久才被访问一次,但是因为和热数据存储在一个数据块上,可能读这个热数据的时候,冷数据也被顺带读到内存中,这可能是没有必要的,我们更多希望被顺带读出来的也是即将被访问的热数据。另外,因为热数据的频繁更新写入,可能会引起系统更多得split、compaction等动作,这个时候,冷数据也被顺带一起多次读写磁盘了,实际上冷数据可能不需要这么频繁地进行这种系统动作。再从成本考虑,业务上如果普遍可以接受陈年旧事——冷数据被访问延时相对高一点点,那么就可以考虑把这些数据存储在成本较低的介质中。
基于这种常见的企业场景需求,ApsaraDB for HBase2.0在阿里云基础体系之上,设计了云HBase冷热分离/分级存储架构,实现企业云上HBase应用的冷热分离场景需求,提高系统运行效率的同时,又降低存储成本。
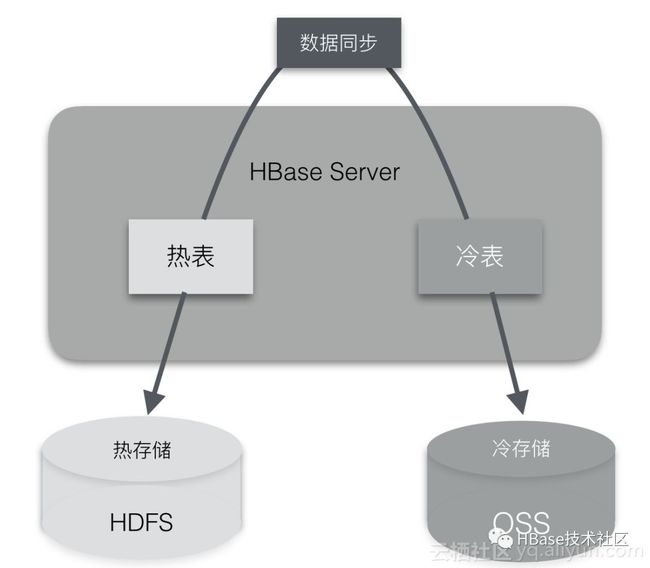
如图所示,架构分两阶段,第一阶段实现分级存储,用户可以清晰的按照不同访问频度将数据存储到不同冷热级别的表上,从表级别上区分冷热数据,实现分级存储。第二阶段是同表数据冷热数据自动分离,用户可以按照访问频率或者创建时间等条件,指定冷热数据判断标准依据,最终后端自动分离冷热数据分别存储。
2.3 一写多读/读高可用
在旧版HBase运行的时候,当一台机器宕机的时候,这个机器所负责的region主要需要经历3个的处理流程才能恢复读——发现宕机、重新分配此机器负责的region、上线region恢复。其中发现宕机可能就需要几十秒,依赖于zookeeper的session timeout时间。在这个恢复过程中,用户client是不可以读这些region数据的。也就是此架构的读不是高可用的,无法保证99.9%的延时都 <20ms。在某些应用业务里,可能更关心整体读高可用、99.9%读延时,且允许读到旧数据的情况下,这就无法满足。
ApsaraDB for HBase2.0是基于2.0最新稳定版,引入了region replicas功能,实现一写多读,扩充了高可用读的能力。

如上图,开启这个功能的表,region会被分配到多个RegionServer上,其中replicaId=0的为主region,其他的为从region,只有主region可以写入,主region负责 flush memstore成为hfile,从region一方面根据hfile列表类读到数据,另一方面对于刚写入主region但还没有flush到hdfs上的数据,通过replication同步到从region的memstore。如上图所示,client1分别时间间隔内写入x=1、x=2、x=3,在同步数据的时候时,client2进行读x的值,它是可以读任何一台server上的x值,这就保证了读的高可用性,即使有机器挂了也可以有 99.9%延时 <20ms保证。
可以看到这种架构读是高可用的,合适一写多读的场景,数据只保存一份。n台机器挂了(n小于一个region的副本数),还可以正常读数据。并且这里提供了两种读一致性模式,分别是strong和timeline-consistent模式。在strong模式下,只读取主region的数据返回结果;在timeline-consistent模式下,允许读任何一个region replica的数据返回,这对一些要求读高可用的场景来说,体验是比较友好的。
2.4 SQL/二级索引/全文检索
HBase原生的设计只有按照rowkey的才能快速查询检索,这对复杂的企业业务检索场景来说,是满足不了的。且随着业务的变化,开始设计的rowkey可能已经不能满足当下系统的某些业务检索需求了。这就要求对HBase的检索功能进行加强。
ApsaraDB for HBase2.0支持更完善的SQL接口、二级索引以及全文索引,用户可以使用熟悉的SQL语句操作HBase系统;并且支持二级索引的创建、全量重建索引,以及增量数据自动同步索引的功能;2.0版本还将支持全文索引检索功能,弥补了HBase不能模糊检索的缺陷,把全文检索的功能引入HBase系统当中。
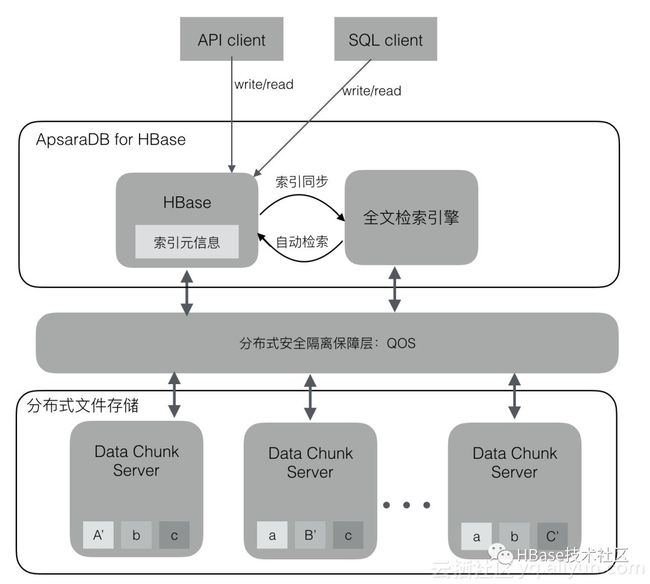
如上图,ApsaraDB for HBase2.0体系内置solr/phoenix内核引擎,进行了深度改造与优化,支持SQL/API方式操作数据库,二级索引支持:全局索引、本地索引、全文索引等。索引支持全量重建、增量数据自动同步更新。在检索查询的时候,索引对用户透明,HBase内部根据索引元信息自动探测用户查询是否需要利用索引功能,增强了HBase系统检索能力,有利于企业在云HBase业务上构建更复杂的检索场景。
2.5 安全体系
在用户使用数据库的时候,都习惯于传统的类型MySQL的账户密码体系,而大数据Hadoop/HBase生态当中,默认却没有一套完整且统一的认证授权体系,组件内置的身份认证仅支持Kerberos协议,而权限控制依赖于每个生态组件自身的控制。
ApsaraDB for HBase2.0基于Alibaba&Intel 合作项目Hadoop Authentication Service (HAS) 开发了一套属于云HBase的认证授权体系,兼容了Hadoop/HBase生态的Kerberos协议支持,并使用人们熟悉的账户密码管理方式,允许对用户访问HBase的权限进行管理,兼容默认ACL机制。
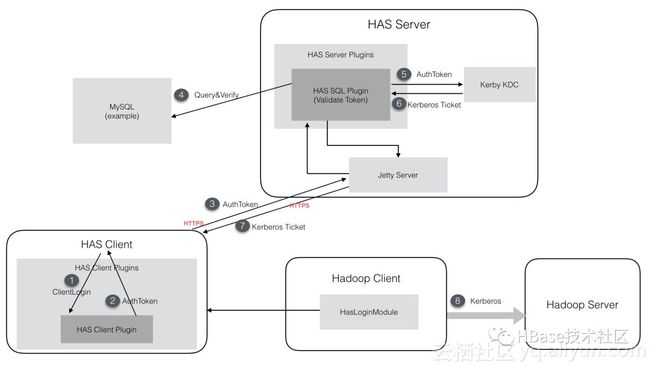
如上图,ApsaraDB for HBase2.0安全体系基于HAS开发,使用Kerby替代MIT Kerberos服务,利用HAS插件式验证方式建立一套人们习惯的账户密码体系,用户体验更友好。
2.6 备份恢复
大数据时代,重要的信息系统中数据就是财富,数据的丢失可能会造成不可估量的损失。对于这种数据重要级别较高的场景,应该要构建一套灾难备份和恢复系统架构,防止人为操作失误、自然灾害等不可避免的偶然因素造成的损失。ApsaraDB for HBase2.0构建在云体系下,支持全量、增量备份,同城/异地灾备功能。
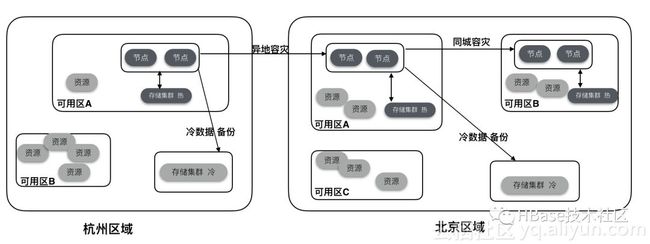
如上图,架构可以允许用户进行冷数据备份,备份数据保存在共享存储中,成本低,需要时可以对备份数据读取还原插入到系统中。同时也支持热备份,集群之间通过全量HFile和增量HLog进行跨集群备份,最终做到同城/异地灾备,业务client可以在访问当下集群不可用时,自动切换到备用集群进行数据访问业务。
三.2.0版本内核解读
开源HBase在2010年正式成为Apache顶级项目独立发展,而阿里巴巴同步早在2010年初已经开始步入HBase的发展、建设之路,是国内最早应用、研究、发展、回馈的团队,也诞生了HBase社区在国内的第一位Committer,成为HBase在中国发展的积极布道者。过去的8年时间,阿里累积向社区回馈了上百个patch, 结合内部的阿里巴巴集团“双十一”业务等的强大考验,在诸多核心模块的功能、稳定性、性能作出积极重大的改进和突破,孕育了一个云上HBase企业版KV数据库ApsaraDB for HBase。
ApsaraDB for HBase发展至今,已经开始进入了2.0 时代。ApsaraDB for HBase是基于开源HBase2.0版本,结合阿里HBase技术和经验的演进过来,其完全兼容HBase2.0,拥有HBase2.0的所有新特性的同时,更享受阿里专家&HBase Committer们在源码级别上的保驾护航。2.0相比1.x之前版本在内核上有了许多改进,内核功能更稳定、高效、延时更低,功能更丰富。下面我们来介绍一下这些重要的功能特性。
3.1 新版Region分配器AMv2——稳定性提高
在早期版本,HBase Server端很多执行业务过程都是使用handler线程实现的,而一个业务线程需要执行的逻辑可能要经历几个步骤。使用handler线程实现的这套机制最大的问题在于不支持异常回滚,没有灾难恢复机制,执行过程中出现异常,那么HBase可能会处在任务的中间状态,引起常见的Region-In-Transition,可能就需要人为去清理。如:客户端调用一个createTable RPC请求,服务端需要创建HDFS目录,写入meta表,分配region,等待region上线,标记region上线完成等等系列步骤,如果handler处理线程中间被中断了,就导致系统残留一下中间状态的数据。
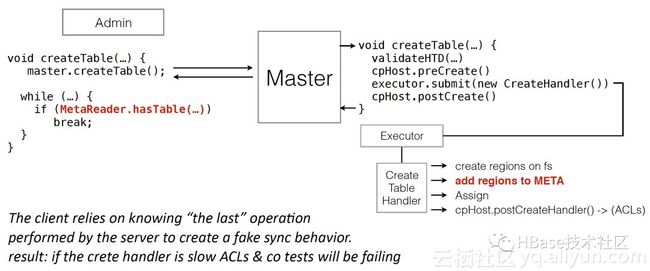
如上图,region信息写入meta表后进程被中断了,而client认为任务已经完成了,实际上整个任务是失败的。在进程恢复后,没有很好的处理这个灾难问题回滚或者继续恢复执行剩下的步骤。
针对这类问题,ApsaraDB for HBase2.0内核做了两个核心的改动,一个是引入ProcedureV2,解决诸如上述分布式多步骤流程处理的状态最终一致性问题;二个是基于ProcedureV2基础上,改造了AssignmentManager,使其在region上线过程被异常或灾难中断后,进程恢复时可以自动回滚中间残留状态信息,重试中断步骤并继续执行。最终避免了类似RIT的问题,实现“NO more HBCK, NO more RIT”,提供稳定性,降低运维成本。
首先我们来看看ProcedureV2的原理,如下图:
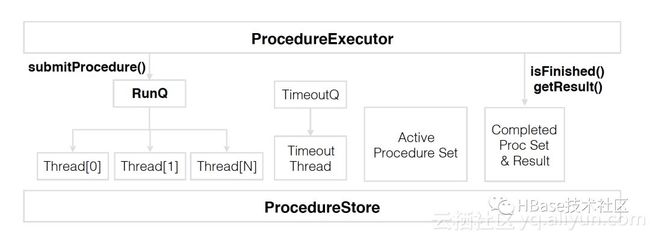
它使用ProcedureExecutor调用执行用户提交的procedure队列,并在执行procedure状态变化的时候,使用ProcedureStore记录procedure的状态持久化到WAL中,如此反复。当procedure执行过程当中进程被中断了,在下一次进程恢复时,就可以根据之前持久化的procedure状态恢复到指定步骤,并做必要的rollback步骤,再重试中断的步骤继续下去。
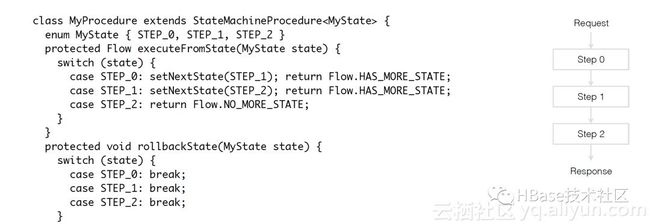
如上图,最常见的就是状态机Procedure,定制每次状态在继续向下执行的时候,应该做哪些操作,以及在中断恢复后,应该处理的rollback工作。回想上面创建表的例子,如果我们同样在"add regions to META"的时候失败了,那么我们在恢复之后,就可以根据这个状态信息,继续执行剩下的步骤,只有当这个procedure 完成的时候,这个create table的procedure 才算完成。当然,client判断是否创建表成功也不再是使用 “MetaReader.hasTable”来利用中间状态得到结果,而是直接根据createTable的procedure Id来查询是否任务完整执行结束。可以看出,在使用ProcedureV2和之前的线程处理有了很大的改进,更灵活的处理业务进程被中断时的各种异常情况。
再来看看AMv2的改进特性,正如上面所述,AssignmentManager V2(简称AMv2)是基于ProcedureV2实现的新版region分配管理器。得益于ProcedureV2的设计实现,AMv2在进行region分配上下线时,可以在被各种情况中断的情况下,自动恢复回滚执行,使得region的状态最终是自动恢复一致性的。除此之外,AMv2还重新设计了region信息保存和更新的逻辑。
在旧版的AssignmentManager实现,是借助Zookeeper协同功能,Master与RegionServer共同完成的region状态维护,代码逻辑相对复杂、效率低。region状态保存在3个地方:Zookeeper、meta表、Master内存,当一个分配流程过程中一端被异常中断时,就容易出现集群状态不一致的现象。如client 访问时报的NotServingRegionException一种能就是region状态不一致,Master认为是分配到这个server上,而实际在这个server并没有上线,此时client rpc请求访问,就会收到这个异常。
下图为旧版AssignmentManager的region assign复杂流程:

如上图流程显示,第1、2、3条线是Master进程的不同线程,第4条是zk,第5、6条是RegionServer上的线程,第7条线是META表。Master和RegionServer都可以更新Zookeeper中region的状态,RegionSever又可以更新 meta表中的 assignment 信息。Master 在将 region assign 给 RegionServer 之前也会更新region 状态信息,Master也可以从 Zookeeper和meta 表中获取 region状态更新。这导致很难维持region处于一个正常的状态,特别是一端处于异常灾难中断的时候。
为了维持region处于一个正常的状态,再加上各种异常中断的情况考虑,HBase内部使用了很多复杂的逻辑,这就大大增加了维护难度,对开发新功能、提升性能的优化工作增加了复杂性。
新版AssignmentManager V2,不仅基于ProcedureV2之上以支持各种中断回滚重试,还重新设计了region分配逻辑,不再使用Zookeeper来保存region的状态信息,region只持久化在meta表,以及Master的内存中,并且只有Master去维护更新,这就简化了状态更新的一致性问题。而且,代码逻辑较之前也清晰简洁了,稳定性提高了,维护的复杂性降低,性能也提高了。
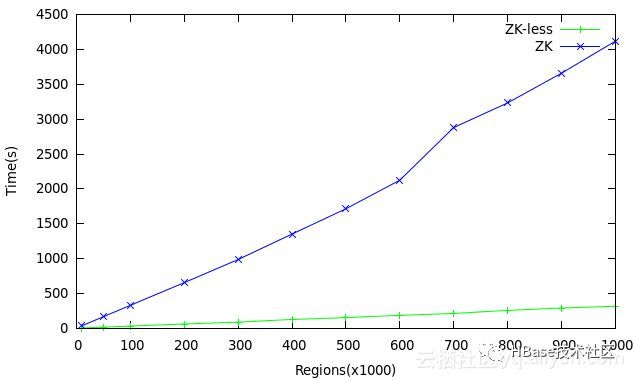
如上图,从测试结果来看,2.0中的 region assign 速度比V1提高非常快。综合看,这个AMv2是个非常有重要的改进。
3.2 Netty Rpc Server和Client——增加吞吐,降低延时
在之前的版本中,HBase的RPC Server使用的是基于Java NIO实现的一套框架。在这套框架中有一个Listener线程负责accept来自Socket的连接请求,并将对应的Connection注册到NIO的Selector上。同时,有若干个Reader线程来负责监听这个selector上处于Readable状态的Connection,将请求从Connection中读出,放入对应的Callqueue中,让handler线程来执行这些请求。虽然HBase社区对这套RPC框架进行了诸多优化,包括去掉一些同步锁,减少复制等等,但由于其线程模型的限制,以及Java NIO本身的瓶颈,在大压力测试中,这套框架仍显得力不从心。
而Netty是一个高性能、异步事件驱动的NIO框架, 在业界有着非常广泛地应用,其稳定性和性能都得到了多方面地印证。抱着“把专业的事情交给专业的人去做”的思想,在HBase2.0中,引入了Netty做为其服务器的RPC框架。引入Netty的工作由来自阿里巴巴的committer binlijin完成,并做了相应的测试。完成后HBase的RPC框架如图所示:
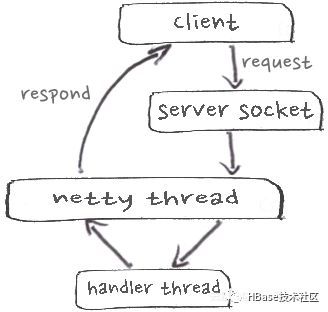
从网络上读取请求和写入response都由Netty来负责,由于HBase的绝大部分请求涉及了较多的IO和CPU操作,因此仍然需要一个Handler线程池来做请求的执行,而和网络相关的操作,完全交给了Netty。使用了Netty服务器后,HBase的吞吐增长了一倍,在高压力下的延迟从0.92ms降到了0.25ms。目前Netty服务器已经是HBase2.0的默认RPC选项。
3.3 读写链路offheap——降低毛刺率,QPS增加
GC一直是java应用中讨论的一个话题,尤其在像HBase这样的大型在线KV数据库系统中,GC停顿会对请求延迟产生非常大的影响。同时,内存碎片不断恶化从而导致Full GC的发生,成为了HBase使用者们的一大痛点。
在HBase的读和写链路中,均会产生大量的内存垃圾和碎片。比如说写请求时需要从Connection的ByteBuffer中拷贝数据到KeyValue结构中,在把这些KeyValue结构写入memstore时,又需要将其拷贝到MSLAB中,WAL Edit的构建,Memstore的flush等等,都会产生大量的临时对象,和生命周期结束的对象。随着写压力的上升,GC的压力也会越大。读链路也同样存在这样的问题,cache的置换,block数据的decoding,写网络中的拷贝等等过程,都会无形中加重GC的负担。而HBase2.0中引入的全链路offheap功能,正是为了解决这些GC问题。大家知道Java的内存分为onheap和offheap,而GC只会整理onheap的堆。全链路Offheap,就意味着HBase在读写过程中,KeyValue的整个生命周期都会在offheap中进行,HBase自行管理offheap的内存,减少GC压力和GC停顿。全链路offheap分为写链路的offheap和读链路的offheap。其中写链路的offheap功能在HBase2.0中默认开启,读链路的offheap功能仍然在完善中,即将在后续的小版本中开启。
写链路的offheap包括以下几个优化:
- 在RPC层直接把网络流上的KeyValue读入offheap的bytebuffer中
- 使用offheap的MSLAB pool
- 使用支持offheap的Protobuf版本(3.0+)
- 更准确的Memstore size计算和更好的flush策略
读链路的offheap主要包括以下几个优化:- 对BucketCache引用计数,避免读取时的拷贝
- 使用ByteBuffer做为服务端KeyValue的实现,从而使KeyValue可以存储在offheap的内存中
- 对BucketCache进行了一系列性能优化
来自阿里巴巴的HBase社区PMC Yu Li将读链路offheap化运用在了阿里巴巴内部使用的HBase集群中,使用读链路offheap后,相应集群的读QPS增长了30%以上,同时毛刺率更加低,请求曲线更加平滑,成功应对了2016年天猫双十一的峰值。
3.4 In-Memory Compaction——减轻GC压力,减少写放大
回顾HBase的LSM结构,HBase为每个region的每个store在内存中创建一个memstore,一旦内存达到一定阈值后,就会flush到HDFS上生成HFile。不断的运行写入,HFile个数就会变多,这个时候读性能就会变差,因为它查询一个数据可能需要打开所有存在这个行的HFile。解决这个问题就需要定期后台运行Compaction操作,将多个HFile合并。但是这样做会使得同一份数据,因多次compaction而会被写入多次hdfs,引起了写入放大的问题。可以看到,要想减少这个compaction的频率的话,可以通过降低HFile的产生速度,同样的内存尽可能多的保存数据,并且在内存中预先进行compaction操作,提高后期hfile的compaction效率。In-Memory Compaction应运而生。
hbase2.0引入In-Memory compaction技术,核心有两点:一是使用 Segment 来替代 ConcurrentSkipListMap ,同样的 MemStore 可以存储更多的数据,减少flush 频繁,从而也减轻了写放大的问题。同时带来的好处是减少内存 GC 压力。二是在 MemStore 内存中实现compaction操作,尽量减少后期写放大。
先来说说其如何高效实用内存。在默认的MemStore中,对cell的索引使用ConcurrentSkipListMap,这种结构支持动态修改,但是其中会存在大量小对象,内存碎片增加,内存浪费比较严重。而在CompactingMemStore中,由于pipeline里面的segment数据是只读的,就可以使用更紧凑的数据结构来存储索引,这带来两方面好处:一方面只读数据块可以降低内存碎片率,另一方面更紧凑的数据结构减少内存使用。代码中使用CellArrayMap结构来存储cell索引,其内部实现是一个数组,如下图:

再来说说其如何降低写放大。旧版Default MemStore是flush时,将active的store 进行打快照snapshot,然后把snapshot flush到磁盘。新版的CompactingMemStore是以segment为单位组织,一个memstore中包含多个segment。数据写入时写到active segment中,active segment到一定阈值后触发in-memory flush 生成不可修改的segment放到pipeline中。pipeline最后会对这些多个segment进行in-memory compaction合并为一个更紧凑的大segment,在一定程度上延长数据在内存的生命周期可以减少总的I/O,减少后期写放大。

内存compaction目前支持Basic,Eager,Adaptive 三种策略。Basic compaction策略和Eager compaction策略的区别在于如何处理cell数据。Basic compaction不会清理多余的数据版本,这样就不需要对cell的内存进行拷贝。而Eager compaction会过滤重复的数据,并清理多余的版本,这意味着会有额外的开销。Adaptive策略则是根据数据的重复情况来决定是否使用Eager策略。在Adaptive策略中,首先会对待合并的segment进行评估,方法是在已经统计过不重复key个数的segment中,找出cell个数最多的一个,然后用这个segment的numUniqueKeys / getCellsCount得到一个比例如果比例小于设定的阈值,则使用Eager策略,否则使用Basic策略。
3.5 支持高效对象存储
ApsaraDB for HBase2.0支持Medium-Sized Object (MOB) 主要目的是在HBase中,能高效地存储那些100k~10M 中等大小的对象。这使得用户可以把文档、图片以及适中的对象保存到HBase系统中。在MOB之前,常见有两个设计方案,第一种是直接保存中等对象到HBase中,另一种是使用HBase中只保存对象数据在HDFS的路径,中等对象以file形式存在HDFS中。这两个现有方案业务方案都有弊端。
通常人们直接存储在HBase中时,分两个列簇存储,一个保存普通信息,另一个用来保存中等对象数据。而通常中等对象一般都是几百KB到几MB大小的KV,这些数据直接插入memstore,会使得flush更频繁,可能几百条几千条数据就引起一次flush,产生更多的hfile后,compaction也会被触发得更频繁,I/O 也会随之变的很大,影响到整个系统的运行。
为了降低MOB中等对象直接存储导致的split、compaction、flush问题,人们开始使用另一种方案,把MOB对象数据存储到HDFS文件上,只在HBase保存MOB对象数据的文件路径。如下图:

这样可以减少split/compaction的影响,但是一致性时由客户端来保证的。另一方面,MOB对象一般是100k~10M的数据,此方案就是每个MOB对象在HDFS上保存一个文件,会产生非常多的小物件,很可能系统很快就使用完了文件句柄打开数。如果优化一下,把许多MOB写到HDFS序列文件上,hbase记录保存着MOB对象的文件路径和数据offset,确实解决了小文件问题,但是有带来另一个问题,那就是很难维护这些MOB对象数据的一致性,并且很难维护删除操作。
HBase2.0 MOB功能类似上述的第二种功能,hbase+HDFS文件的方式实现。不同的是,这些都是在server端完成,不需要client去维护数据的一致性。并且保存的HDFS文件不是简单的hdfs序列文件,而是HFile。这样它就可以有效管理这些MOB数据,并且和普通hfile一样处理deleted数据。
MOB数据的读流程是:
- seek cell in HBase Table and find the MOB file path
- find the MOB file by path
- seek the cell by rowkey in the MOB file
读一个MOB的流程总是只open一个MOB file,所以不管有多少MOB file,是不会影响这个读性能的。所以split、compaction也并不是必要的。当然系统会设计compaction策略来定期删除掉那些deleted的数据,以腾出空间来。MOB的实现,使得用户在保存中等对象时,不必自己维护数据的一致性,更兼容了现在的HBase api操作MOB hfile。
3.6 异步client ——提高客户端并发/吞吐
HBase 2.0 前 HBase 的 Client 是同步调用的,HBase2.0后实现了异步的Client。异步客户端有两个好处:
1. 在单个线程中,异步客户端是非阻塞的,不需要等上一个请求的返回,就可以继续再发送多个请求,可提高客户端吞吐。
2. 可一定程度上解决故障放大问题,如因为某个业务的多个处理线程同时访问HBase 某个卡住的 RegionServer (GC原因,HDFS 访问慢,网络原因等)时,这部分的的业务的处理线程都会被卡住,此时业务的可用性要低于HBase 的可用性(HBase 其它的 RegionServer 可能是正常的)。
3.7 异步DFSClient——提高服务端性能
之前HBase 访问HDFS 都是同步的,经常发生因为HDFS 访问慢,而阻塞handler的情况。例如当前的处理HBase RPC的handler为100个,刚好这100个handler访问某个DataNode被阻塞。此时 RPC Server则无法处理前端请求,只能等访问HDFS数据返回或者超时才能释放hanlder 响应新的请求。而异步DFS Client 则不需要等待。可大大提高系统性能以及可用性。
3.8 Region多副本——读高可用,降低延时
ApsaraDB for HBase2.0引入region多副本机制,当用户对某个表开启此功能时,表的每个region会被分配到多个RegionServer上,其中replicaId=0的为主region,其他的为从region,只有主region可以写入,从region只能读取数据。主region负责 flush memstore成为hfile;从region一方面根据hfile列表类读到数据,另一方面对于刚写入主region但还没有flush到hdfs上的数据,通过replication同步到从region的memstore。

如上图所示,client1分别时间间隔内写入x=1、x=2、x=3,在同步数据的时候时,client2进行读x的值,它是可以读任何一台server上的x值,这就保证了读的高可用性,即使有n台机器挂了(n小于一个region的副本数)也可以有 99.9%延时 <20ms保证。可以看到这种架构读是高可用的,合适一写多读的场景。
这里还提供了两种读一致性模式,分别是strong和timeline-consistent模式,strong模式下,只读取主region的数据返回结果;timeline-consistent模式下,允许读任何一个region replica的数据返回。
四.展望
ApsaraDB for HBase2.0 是基于开源HBase2.0之上,融入了阿里HBase多年大规模实战检验和技术积累的新一代KV数据库产品。结合了广大企业云上生产环境的特定需求,定制了许多商业化功能,比如:oss、公网、本地盘、共享存储、冷热分离、备份恢复、安全等等。
接下来,我们在不断完善ApsaraDB for HBase2.0架构基础功能上,会陆续开放与完善更统一高效的SQL平台,并加强云HBase的生态建设,开放图数据库、时空数据库、cube数据库-Kylin等。
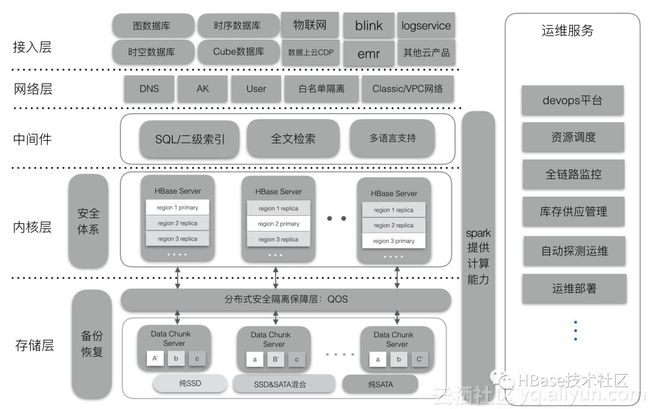
如上图所示,在接入层上,ApsaraDB for HBase2.0 陆续支持更多云产品链路直通访问,如:blink、CDP、LogService、emd、物联网套件等,开放HBase上生态组件,如:图数据库、时空、cube数据库等,让企业在云上完成数据库业务架构闭环。
网络层继续支持经典网/VPC专有网络选择,并支持弹性公网开关服务,方便了云上生产/云下开发调试用户需求。
中间件层继续支持并优化SQL 二级索引的创建与使用,支持多语言服务,thrift/rest服务化;ApsaraDB for HBase2.0陆续开放更强大的检索功能,包括全文检索、图检索、空间检索等,满足企业更复杂的业务检索需求。
在HBase内核层+存储层上,ApsaraDB for HBase2.0 采用的最新版的2.0内核,结合阿里HBase多年的技术积累经验,针对企业上云继续完善、优化更多商业化功能。例如:
- 本地盘:服务器直通本地盘读写,效率高,成本低,相比高效云盘降低5倍。20T起购买。
- 共享存储:实现HBase共享存储,动态添加容量包,使用灵活,成本低。
- 冷热分离:冷热数据分别存储不同介质
- 备份恢复:支持增量、全量备份恢复,支持跨集群跨机房容灾备份。
- 企业安全:基于Intel&alibaba合作Hadoop Authentication Service安全项目, 兼容hadoop/hbase生态kerberos认证。
- 离线弹性作业:为hbase批处理业务运行离线作业的弹性计算平台,使得hbase存储计算分离,把系统compaction、备份恢复、索引构建以及用户作业单独启动弹性计算资源进行离线处理,计算完后立刻释放,弹性伸缩。
- SQL二级索引:支持phoenix二级索引,优化索引构建与查询功能。
- 全文检索:支持solr全文索引,满足复杂的检索功能。
综合来说,ApsaraDB for HBase2.0是围绕企业HBase上云的使用环境,从内核功能到性能,从自动运维到专家坐诊,从开发效率到生产成本,完善的HBase生态体系,都为用户业务轻松上云稳定保驾护航。
更多技术交流,可关注微信交流群,微信公众号等:
或参考文章: HBase中文社区官网、交流群
1. 微信群

2. 钉钉群:

3. 微信公众号:
