参考资料:廖雪峰的Python教程,崔庆才的博客
urllib是Python内建的一个http请求库,主要分为urllib.request / urllib.error / urllib.parse / urllib.robotparser四个模块。
下面来分别做简单的介绍。
1.urllib.request
用来模拟浏览器发送请求。
1.1 urlopen
语法:
urllib.request.urlopen(url, data=None, [timeout,]*, cafile=None, capath=None, cadefault=False, context=None)
用这个方法来访问百度,并打印返回:
import urllib.request
response = urllib.request.urlopen('http://www.baidu.com')
print(response.read().decode('utf-8')) #这里的read方法获取了response的内容,并转换格式
在编辑器或者IDE(推荐pycharm)中执行代码,就会看到返回结果:
返回结果的一部分截图.png
接下来试着发送一个POST请求:
from urllib import request, parse
data = bytes(urllib.parse.urlencode({'world': 'hi'}),encoding='utf-8')
response = urllib.request.urlopen('http://httpbin.org/post',data=data)
print(response.read().decode('utf-8'))
返回结果如下,从图片中可以看到我们设置的数据data已经成功传递。
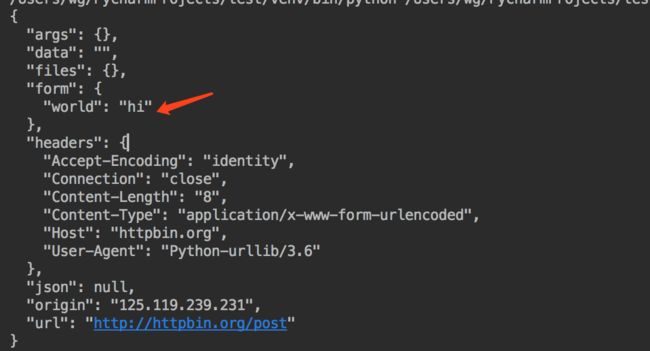
数据已经传输成功.png
第三个参数timeout可以设置请求的时长:
import socket
import urllib.request
import urllib.error
try:
response = urllib.request.urlopen('http://httpbin.org/get', timeout=0.1) # 这里设置超时时间为0.1,如果时间超过0.1,则抛出错误
except urllib.error.URLError as e:
if isinstance(e.reason, socket.timeout): # 对错误类型进行判断,如果是socket.timeout,则打印 TIME OUT
print('TIME OUT') # TIME OUT
1.1.1 关于response
打印一下response:
import urllib.request
import urllib.error
response = urllib.request.urlopen('http://httpbin.org/get')
print(type(response))
print(response.status) # 获取状态码
print(response.getheaders()) # 获取响应头,是一个数组
print(response.getheader('Server')) #注意这里是 getheader 不是 getheaders;获取响应头中的某个值,如获取Server

response截图.png
1.1.2 设置request
手动设置request的请求头等参数:
from urllib import request, parse
url = 'http://httpbin.org/post'
headers = { # 请求头
'User-Agent': 'Mozilla/4.0(compatible;MSIE 5.5;Windows NT)',
'Host': 'httpbin.org'
}
dict = {
'name': 'wg'
}
data = bytes(parse.urlencode(dict), encoding='utf8')
req = request.Request(url=url, data=data, headers=headers, method='POST') # 这样结构很鲜明
response = request.urlopen(req)
print(response.read().decode('utf-8'))
可以看到返回的数据和之前是一致的:
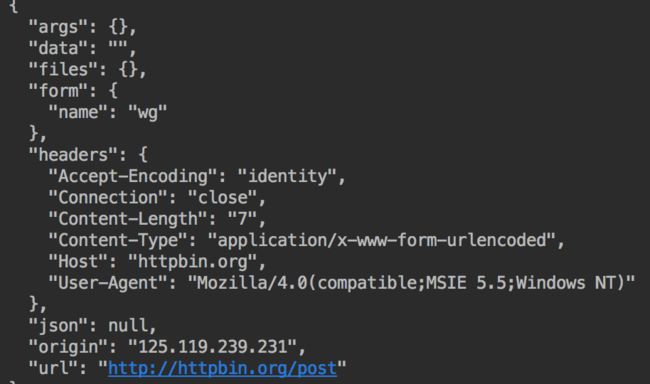
返回的数据和之前是一致的.png
2. urllib.error
用来处理程序运行中的异常。大致分为HTTPError / URLError:
# 异常处理模块
from urllib import request, error
try:
response = request.urlopen('http://www.onebookman.com/index.html') # 请求一个并不存在的地址
except error.HTTPError as e:
print(e.reason, e.headers, e.code, 'wrong', sep='\n')
except error.URLError as e:
print(e.reason)
except error.ContentTooShortError as e:
print(e.content)
else:
print('request suc')
3. urllib.urlparse
解析URL。
看一段代码就能明白它的用途:
from urllib.parse import urlparse
result = urlparse('http://www.baidu.com/index.html;user?id=5#comment')
print(type(result), result)
输出结果为:
ParseResult(scheme='http', netloc='www.baidu.com', path='/index.html', params='user', query='id=5', fragment='comment')
3.1 urlunparse
这个方法是urlparse的反操作:
from urllib.parse import urlunparse
data = ['http', 'www.baidu.com', 'index.html', 'user', 'a=6', 'comment']
print(urlunparse(data))
输出结果:
http://www.baidu.com/index.html;user?a=6#comment
3.2 urlencode
把一个字典对象拼接为get请求的参数:
from urllib.parse import urlencode
params = {
'name': 'wg',
'age': 18
}
base_url = 'http://www.baidu.com'
url = base_url + urlencode(params)
print(url) # http://www.baidu.comname=wg&age=18
4. urllib.robotparser
robotparser为robots.txt文件实现了一个解释器,可以用来读取robots文本的格式和内容,用函数方法检查给定的User-Agent是否可以访问相应的网站资源。如果要编写一个网络蜘蛛,这个模块可以限制一些蜘蛛抓取无用的或者重复的信息,避免蜘蛛掉入动态asp/php网页程序的死循环中。
以上就是对urllib库的简单介绍。
完。