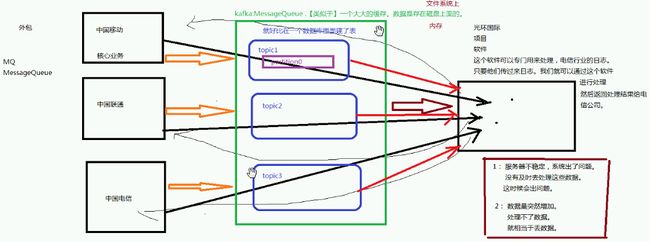
问题场景
kafka:MessageQueue:消息系统
topic:主题
分区的好处:并行查询
kafka集群 broker(代理。经纪人)
数据:message
生产者 消费者== 代码
生产者可以向不同的topic发送数据,消费者可以从不同的topic中获取需要的数据
kafka核心概念:topic partition broker
kafka简介:公司 linkedin 开源 分布式的消息系统
支持多种语言进行开发(c++ java python scala)
scala是一门语言:既能面向对象(其实面向对象调用的过程就是面向过程),又能面向函数。
wordcount的例子
java和Scala:
jdk1.8 Lamda表达式:函数式编程
java有非常成熟的产品:Hadoop hbase hive 成熟的三大框架:SSM SSH
由于java是一门有成熟产品的语言,目前来说还是难以代替的。
kafka是用java写的,spark大部分的核心代码是用Scala,一部分使用java写的,flink使用Scala写的。
Python:Python可以做的事情:企业级开发 ,网络爬虫(封装好了进行网络爬虫的工具),数据分析(机器学习的开发。深度学习的开发),运维
大数据的工具对Python非常的友好,几乎所有的工具都支持Python。Python缺点:Python2->Python3 可能会不兼容。
大数据首先要考虑数据的来源:
1)通过网络爬虫爬到(Python)
2)用Hadoop存储
3)用hive、hbase分析
面向对象+面向函数
Scala的作者是JVM的作者之一。所以Scala也运行在JVM之上,java和Scala的代码可以互相调用。
spark:java Scala
消息系统(不一定是kafka)的好处:1)解耦合 2)扩展性 3)可恢复性(处理数据的节点宕机不会造成数据的丢失)4)提高峰值的处理能力
消息队列的分类
一对多:这种模式叫订阅模式(public-subscribe)。
一对一:点对点的模式(point-to-point)。
两种模式的特点:
点对点模式:如果一个人消费了数据,其他人就消费不了了。
订阅模式:一组中只能一个人消费数据,但可以多个组消费。
kafka用的是订阅模式。
数据的处理方式:push(推) pull(拉)
pull:按需取数据,所以kafka设计的时候,用的是pull
push:微信群聊场景,信息都是推过来的,我们打开聊天界面就可以直接看到之前的聊天所有记录。
kafka的核心概念
producer:消息的生产者
consumer:消息的消费者
broker:代理,kafka集群当中的一台服务器。
topic:主题,类似于关系型数据库里面的一张表
partition:提升读写性能,解决磁盘瓶颈问题

message:消息(数据),通信最基本单位。
kafka集群的架构
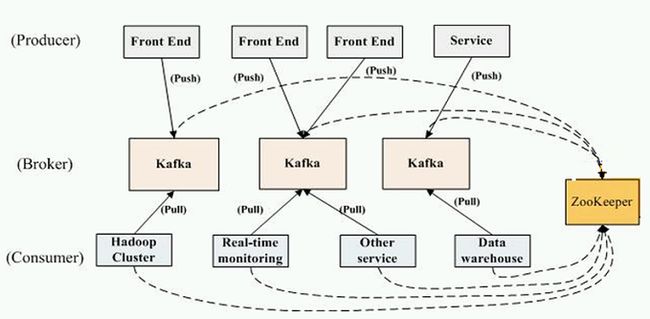
zookeeper:协调作用 保存了kafka的元数据信息
读数据的时候必须有zookeeper的地址。
每个kafka里面都有全量的元数据信息。
搭建集群
集群规划
两个角色:kafka和zookeeper
kafka zookeeper
Hadoop02 √ √
Hadoop03 √ √
Hadoop04 √ √
centos版本:6.7
Step 1: 下载软件包:版本:8.2.2
官网:https://www.apache.org/dyn/closer.cgi?path=/kafka/0.8.2.2/kafka_2.11-0.10.2.1.tgz
Step2:解压到apps
step3:修改配置文件/kafka/config
配置文件:server.properties producer.properties consumer.properties
1)server.properties
broker.id=1
host.name=hadoop02
port=9092
log.dirs=/home/hadoop/log/kflog
num.partitions=1
zookeeper.connect=hadoop02:2181,hadoop03:2181,hadoop04:2181
2)producer.properties
bootstrap.servers=hadoop02:9092,hadoop03:9092,hadoop04:9092
compression.codec=none(压缩类的指定)
serializer.class=kafka.serializer.DefaultEncoder
3)consumer.properties
zookeeper.connect=hadoop02:2181,hadoop03:2181,hadoop04:2181
一些参数的说明
1)端口号和主机名
broker的端口号:port=9092
host.name
2)指定存储路径在hdfs上:
log.dirs
3)默认分区partition
4)数据生命周期:默认168小时(即一周),可以修改
5)zookeeper的依赖集群
zookeeper.connect=hadoop02:2181,hadoop03:2181,hadoop04:2181
step4:发送安装包到Hadoop03,Hadoop04
for i in hadoop04 hadoop03
do scp -r kafka_2.11-0.8.2.2/ hadoop@$i:$PWD
done
需要修改 broker.id 和 host.name
配置环境变量.bashrc
Step 4: Start the server
Kafka uses ZooKeeper so you need to first start a ZooKeeper server if you don't already have one. You can use the convenience script packaged with kafka to get a quick-and-dirty single-node ZooKeeper instance.
首先选择使用自己安装的zookeeper,如果没有,可以使用软件自带。
软件自带的zookeeper的启动命令:
>bin/zookeeper-server-start.sh config/zookeeper.properties
Now start the Kafka server:
>bin/kafka-server-start.sh config/server.properties(参数文件)
bin/kafka-server-start.sh config/server.properties &
Step 5: Create a topic
Let's create a topic named "test" with a single partition and only one replica:
> bin/kafka-topics.sh --create --zookeeper hadoop02:2181 --replication-factor 1 --partitions 1 --topic test
解读:五个参数 create zookeeper replication-factor partitions topic
We can now see that topic if we run the list topic command:列出主题
>bin/kafka-topics.sh --list --zookeeper hadoop02:2181
--delete Delete a topic
Alternatively, instead of manually creating topics you can also configure your brokers to auto-create topics when a non-existent topic is published to.
Step : Send some messages 模拟生产者
Kafka comes with a command line client that will take input from a file or from standard input and send it out as messages to the Kafka cluster. By default each line will be sent as a separate message.
Run the producer and then type a few messages into the console to send to the server.
>bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test2
This is a message
This is another message
Step : Start a consumer 模拟消费者
Kafka also has a command line consumer that will dump out messages to standard output.
>bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test2 --from-beginning
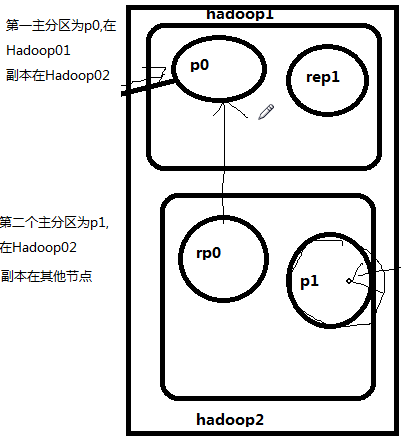
分区副本
主分区 数据进行读写都是针对主分区,备份分区时时刻刻与主分区同步数据
主分区压力很大,为了负载均衡,有以下设计
kafka的设计:kafka是架构在文件系统(磁盘)之上的。
要保证高性能(因为kafka是与storm ,sparkStreaming这些实时流打交道)
kafka写数据与HBase类似,都是顺序写进去;读数据也是顺序读出来。
kafka架构在磁盘上的优点:
1)没有容量的限制(磁盘便宜) 扩大容量的方式:横向扩展:加机器;垂直扩展:加大硬盘
2)顺序访问数据的,性能上没有多大影响
内存缺点:1)容易达到瓶颈 2)kafka重启 ,需要花的时间较多
kafka的javaAPI
producer consumer kafkaproperties
producer.java 的作用:run方法发送数据
consumer.java extends Thread作用:run方法消费数据
首先构造器初始化一个连接器,properties里面put属性名和值
kafkaStream
写数据不需要zookeeper,但消费数据需要zookeeper的地址
低端的API,偏移量是由自己来维护的,每消费一次数据,就更新一次偏移量。
保存上一次消费的偏移量:auto.commit.interval.ms ==1000 表示每1秒记录一次偏移量,由zookeeper记录的。