一、简介
XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。XPath 是 W3C XSLT 标准的主要元素,并且 XQuery 和 XPointer 都构建于 XPath 表达之上。
参照
二、安装
pip install lxml
三、使用
- 1、导入
from lxml import etree
- 2、 基本使用
from lxml import etree
wb_data = """
"""
html = etree.HTML(wb_data)
#对HTML文本进行初始化,成功构造xpath解析对象,并自动修正HTML文本
print(html)
print(etree.tostring(html).decode("utf-8"))#输出修正后的html文本
从下面的结果来看,我们打印机html其实就是一个python对象,etree.tostring(html)则是不全里html的基本写法,补全了缺胳膊少腿的标签
D:\anaconda\python.exe D:/bilibili大学/代码/推导式.py
Process finished with exit code 0
- 3、获取某个标签的内容(基本使用)
注意:获取a标签的所有内容,a后面就不用再加正斜杠,否则报错。
写法一:
from lxml import etree
wb_data = """
"""
html = etree.HTML(wb_data)
html_data = html.xpath('//ul/li/a')
print(html)
for i in html_data:
print(i.text)
输出为:
D:\anaconda\python.exe D:/bilibili大学/代码/推导式.py
first item
second item
third item
fourth item
fifth item
Process finished with exit code 0
感觉写的很麻烦,代码量又多,还特么有循环,搞个鸡儿,看看就好了,法二才是我们常用的:
from lxml import etree
wb_data = """
"""
html = etree.HTML(wb_data)
html_data = html.xpath('//ul/li/a/text()')
print(html_data)
******************************************************************************************
D:\anaconda\python.exe D:/bilibili大学/代码/推导式.py
['first item', 'second item', 'third item', 'fourth item', 'fifth item']
Process finished with exit code 0
-
4、打开读取html文件
 桌面上新建的html文件
桌面上新建的html文件
from lxml import etree
html = etree.parse('C:\\Users\董贺贺\Desktop\新建 RTF 文档.html')
print(html)
result = etree.tostring(html).decode('utf-8')
print(result)
输出:
D:\anaconda\python.exe D:/bilibili大学/代码/推导式.py
Process finished with exit code 0
- 5、打印指定路径下a标签的属性(可以通过遍历拿到某个属性的值,查找标签的内容)
from lxml import etree
html = etree.parse('C:\\Users\董贺贺\Desktop\新建 RTF 文档.html')
data = html.xpath('//ul/li/a/@href')
print(data)
******************************************************************************
D:\anaconda\python.exe D:/bilibili大学/代码/推导式.py
['link1.html', 'link2.html', 'link3.html', 'link4.html', 'link5.html']
Process finished with exit code 0
- 6、我们知道我们使用xpath拿到得都是一个个的ElementTree对象,所以如果需要查找内容的话,还需要遍历拿到数据的列表。
查到绝对路径下a标签属性等于link2.html的内容。
from lxml import etree
wb_data = '''
'''
html = etree.HTML(wb_data)
html_data = html.xpath('//ul/li/a[@href="link2.html"]/text()')
print(html_data)
for i in html_data:
print(i)
********************************************************************************
D:\anaconda\python.exe D:/bilibili大学/代码/推导式.py
['second item']
second item
Process finished with exit code 0
- 7、上面我们找到全部都是绝对路径(每一个都是从根开始查找),下面我们查找相对路径,例如,查找所有li标签下的a标签内容。
from lxml import etree
wb_data = '''
'''
html = etree.HTML(wb_data)
html_data = html.xpath('//ul/li/a/text()')
print(html_data)
for i in html_data:
print(i)
***************************************************************************************
['first item', 'second item', 'third item', 'fourth item', 'fifth item']
first item
second item
third item
fourth item
fifth item
- 8、上面我们使用绝对路径,查找了所有a标签的属性等于href属性值,利用的是/---绝对路径,下面我们使用相对路径,查找一下相对路径下li标签下的a标签下的href属性的值。
from lxml import etree
wb_data = '''
'''
html = etree.HTML(wb_data)
html_data = html.xpath('//li/a/@href')
print(html_data)
for i in html_data:
print(i)
*************************************************************************************
D:\anaconda\python.exe D:/bilibili大学/代码/推导式.py
['link1.html', 'link2.html', 'link3.html', 'link4.html', 'link5.html']
link1.html
link2.html
link3.html
link4.html
link5.html
- 9、相对路径下跟绝对路径下查特定属性的方法类似,也可以说相同。
from lxml import etree
wb_data = '''
'''
html = etree.HTML(wb_data)
html_data = html.xpath('//li/a[@href="link2.html"]/text()')
print(html_data)
for i in html_data:
print(i)
***************************************************************************************
D:\anaconda\python.exe D:/bilibili大学/代码/推导式.py
['second item']
second item
Process finished with exit code 0
- 10、查找最后一个li标签里的a标签的href属性
from lxml import etree
wb_data = '''
'''
html = etree.HTML(wb_data)
html_data = html.xpath('//li[last()]/a/text()')
print(html_data)
for i in html_data:
print(i)
******************************************************************************************
D:\anaconda\python.exe D:/bilibili大学/代码/推导式.py
['fifth item']
fifth item
Process finished with exit code 0
- 11、查找倒数第二个li标签里的a标签的href属性
from lxml import etree
wb_data = '''
'''
html = etree.HTML(wb_data)
html_data = html.xpath('//li[last()-1]/a/text()')
print(html_data)
for i in html_data:
print(i)
************************************************************
D:\anaconda\python.exe D:/bilibili大学/代码/推导式.py
['fourth item']
fourth item
Process finished with exit code 0
-
12、如果在提取某个页面的某个标签的xpath路径的话,可以如下图:
//*[@id="kw"]
解释:使用相对路径查找所有的标签,属性id等于kw的标签。
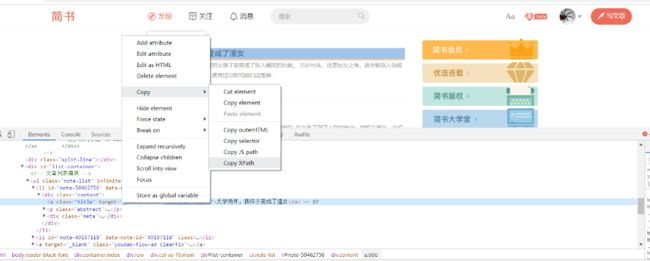
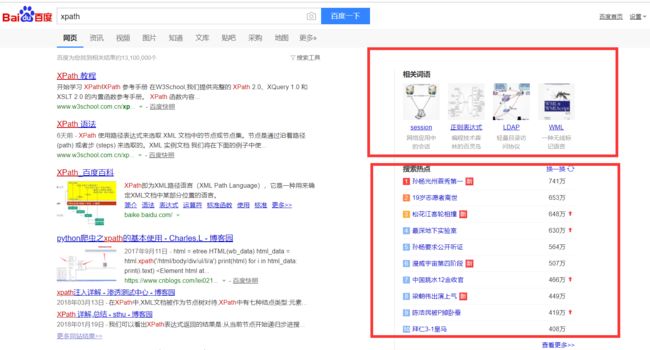
我们再加一个案例吧,我们就用百度搜索xpath,然后分析网页找出关键字和热点新闻:
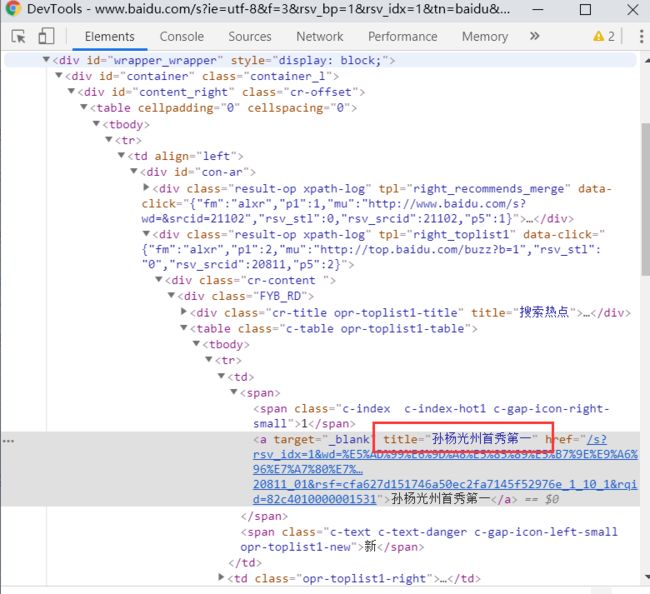
下面我贴出来代码主要就是settings和index.py改动,其他未变动:
settings.py:
# -*- coding: utf-8 -*-
# Scrapy settings for baidu project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'baidu'
SPIDER_MODULES = ['baidu.spiders']
NEWSPIDER_MODULE = 'baidu.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
LOG_LEVEL = 'WARN'
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
index.py(也就是解析模块):
# -*- coding: utf-8 -*-
import scrapy
class IndexSpider(scrapy.Spider):
name = 'index'
allowed_domains = ['baidu.com']
start_urls = ['https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=xpath&oq=xpath&rsv_pq=91e5544c00077502&rsv_t=06ddMHdjcYZEGdPFq5JO%2FwPG7GyaCcDEGeCPLltYHxpViFNHzIDlghemN1A&rqlang=cn&rsv_enter=0&rsv_dl=tb']
def parse(self, response):
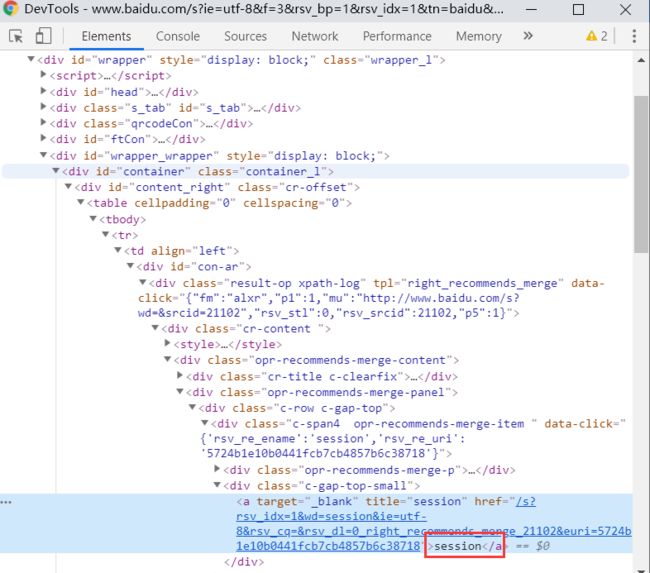
key_word = response.xpath('//*[@id="con-ar"]/div[1]/div/div/div[2]/div'
'//div[@class="c-gap-top-small"]/a/text()').extract()
hot_news = response.xpath('//*[@id="con-ar"]/div[2]/div/div/table/'
'tbody[1]/tr/td/span/a/text()').extract()
print(key_word , hot_news)
最后输出:
D:\bilibili大学\scrapy_pool\baidu>scrapy crawl index
['session', '正则表达式', 'LDAP', 'WML'] ['孙杨要求公开听证', '周杰伦超话第一', '李现为周杰伦打榜', '最深地下实验室', '孙杨光州首秀第
一', '19岁志愿者离世', '漫威宇宙第四阶段', '武磊替补登场造点', '复联4创影史冠军', '宋慧乔下半年停工']