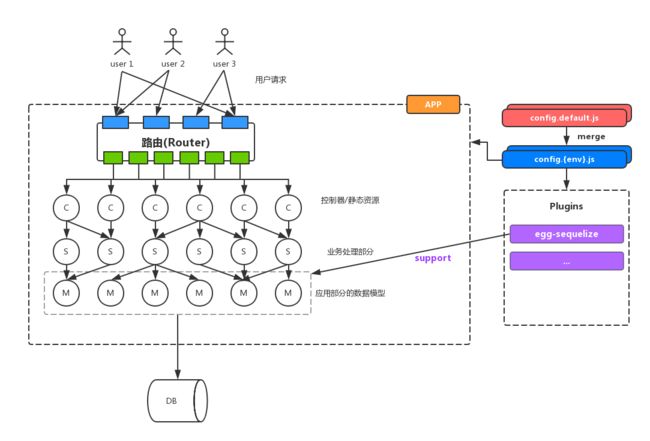
Egg 框架模型简述 (三)
- 简单的骨架认知
- 插件使用(Plugins)
- 持久层方案(egg-sequelize)
- Worker 和 高效负载均衡
- Agent 代理角色
- 定时任务
笔者的其他文章推荐: 《JS 函数式编程思维简述》
3. 持久层方案(egg-sequelize)
官方文档:https://eggjs.org
二维表是一种非常容易描述对象状态的结构,比如我们有一些宠物小精灵的数据需要操作:

他们在数据表中大概长这个样子:
| id | name | type | level | prob | createdAt |
|---|---|---|---|---|---|
| 001 | 妙蛙种子 | 草,毒 | 1 | 46.2% | 2018-12-12 10 : 23 : 55 |
| 006 | 喷火龙 | 火,飞行 | 3 | 12.6% | 2018-12-03 13 : 02 : 23 |
| 054 | 可达鸭 | 水,超能 | 1 | 21.7% | 2018-11-11 21 : 57 : 06 |
| ... | ... | ... | ... | ... | ... |
了解面向对象的同学都知道,类型(class)对实例(instance)而言起到了规范和约束的作用。对于二维表的设计结构,我们也可以将其类比做一种类型建模,每一条数据都可以当作是该类型约束下的一个实际的用例。对这样的用例数据,我们最常使用的操作便是 CRUD (数据新增、查询、修改和删除)。
应用中操作数据的方式
我们在应用中,通常通过两种方式对数据进行操作:直接使用结构化查询语言(SQL) 以及 使用数据对象模型。二者的差异是:
| 操作 | 优势 | 劣势 |
|---|---|---|
| SQL查询 | 操作灵活,利于优化执行过程 | 硬编码,不利于扩展,对开发人员要求高 |
| 对象操作 | 扩展性强,不关注持久层类型 | 学习成本提升,使用框架的数据操作优化方案,灵活性较弱 |
在项目实际应用过程中,普遍会采用后者,以操作数据对象模型的方式,对数据库进行操作。随着时间推移,也衍生出了一些综合平衡二者优劣势的折中型持久层数据操作方案(被称之为是半自动化):既可以通过SQL的方式编写操作命令,又能够由框架解析应用层的对象模型,进行操作处理。
Egg 的选择
Sequelize 中文API:https://itbilu.com/nodejs/npm/VkYIaRPz-.html#api-instance-models
在 Node.js 社区存在着许多 ORM (对象关系映射) 框架,其中 Sequelize 便是一个使用广泛,支持 MySQL、PostgreSQL、SQLite 和 MSSQL 等多个数据源的优秀框架。
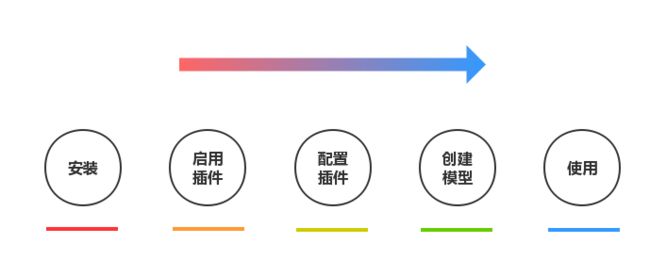
Sequelize 支持通过数据模型对象来操作持久层,亦支持原始的查询语句操作。对于 Egg 而言,Sequelize 是以插件的方式引入应用的,在引入之后,他会在创建一个基本数据模型对象 Model, 并挂载到 app 和 ctx 对象上,以便于使用。基本上我们需要遵循如下步骤:
注意,在真实的项目中我们需要考虑更多关于数据应用环境以及数据迁移、升降级。此时我们应在
配置插件之后,进行详细的 Migrations 配置,可参考:https://eggjs.org/zh-cn/tutorials/sequelize.html#初始化数据库和-migrations
使用步骤一:安装插件 ( 示例基于mysql数据库 )
安装 egg-sequelize 和 mysql2 插件,插件在提供 Sequelize 能力的同时,会将操作对象进行相应的挂载。
$ npm i --save egg-sequelize mysql2
使用步骤二:启用插件
在项目中的 ./config/plugin.ts 位置,启用相应的插件。
import { EggPlugin } from 'egg';
const plugin: EggPlugin = {
// 启用插件: sequelize
sequelize: {
enable: true,
package: 'egg-sequelize',
},
}
使用步骤三:配置插件
在配置文件 ./config/config.{env}.ts 中,对插件进行初始化。
import { EggAppConfig, EggAppInfo, PowerPartial } from 'egg';
export default (appInfo: EggAppInfo) => {
const config = {} as PowerPartial;
// 配置 sesquelize 连接项
config.sequelize = {
dialect: 'mysql',
host: '你的IP',
port: 你的端口号,
database: '你的数据库',
username: '你的名字',
password: '你的密码',
timezone: '+08:00', // 东8区设置
pool: { // 连接池
max: 10,
min: 1,
idle: 10000,
},
retry: { max: 3 },
};
return {
...config,
};
}
使用步骤四:创建模型
此时,我们需要根据数据库中的表模型,建立相应的应用对象模型。我们将对象模型置于 app/model/ 位置。例如我们上边的数据库表 pokemon 的对应模型 app/model/pokemon.ts:
const moment = require('moment');
export default (app) => {
const {
STRING, DATE, NOW, INTEGER,
} = app.Sequelize;
// 模型函数返回的对象,会挂载到 Model 对象上
const Pokemon = app.model.define('pokemon', {
id: {
type: INTEGER,
autoIncrement: true,
primaryKey: true,
},
name: STRING,
type: STRING, // 类别的部分实际上应该提取成另一个单独的表进行关系描述
level: INTEGER,
prob: STRING,
// 处理 sequelize 中的时区格式化
createdAt: {
type: DATE,
get createdAt() {
return moment(Pokemon.getDataValue('createdAt')).format('YYYY-MM-DD HH:mm:ss');
},
defaultValue: NOW,
},
}, {
tableName: 'pokemon',
timestamps: false,
});
return Pokemon;
};
使用步骤五:开始使用
此时,我们便可以在 Controller 或 Service 部分,进行数据库操作了!
// app/service/pokemon.ts
import { Service } from 'egg';
export default class PokemonService extends Service {
/**
* 获取相应ID的数据
* @param {*} param0
*/
public async queryById(id: number) {
const {ctx} = this;
return await ctx.model.pokemon.findById( id );
}
// ...
}
项目目录结构
自此,我们的项目目录结构也相应有所变化:
// 这是一个 egg 项目的目录结构
├─ app
│ ├─ controller
│ │ ├─ pokemon.ts
│ │ └─ home.ts
│ ├─ service
│ │ ├─ pokemon.ts
│ │ └─ home.ts
│ ├─ model
│ │ ├─ pokemon.ts
│ │ └─ user.ts
│ ├─ middleware
│ │ └─ xtoken.ts
│ └─ router.ts
├─ config
│ ├─ config.default.ts
│ ├─ config.prod.ts
│ ├─ config.local.ts
│ └─ plugin.ts
而项目应用结构也更加明晰了: