一 : 简介
HttpServletResponse : 当创建Servlet时会覆盖service()方法,或doGet()与doPost这些方法中都会有request与response参数,分别代表请求和响应.
doGet()与doPost方法的response类型是HttpServletResponse而service方法的类型是ServletResponse,HttpServletResponse是ServletResponse的子接口,功能更加强大.
二 : HttpServletResponse过程
其中tomcat内核引擎会把请求信息封装成resquest对象,并且创建一个response对象,但是这个response对象是空的,没有东西,我们将写好后的内容暂时放入response缓冲区,再由tomcat去该缓冲区获取设置的内容,最后tomcat从response中获取设置内容组装一个http响应,由页面进行解析显示.
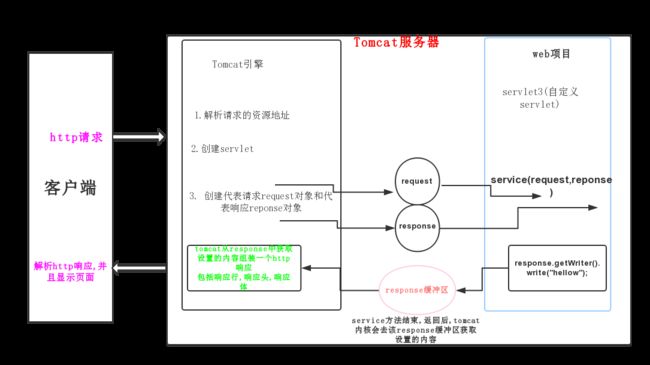
三 : HttpServletResponse方法
-
response设置响应行
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
//手动设置http响应行状态码
response.setStatus(302);
}
-
response设置响应头
`add`表示添加, `set`表示设置
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
// TODO Auto-generated method stub
//设置响应头
Date date = new Date(0);
response.setHeader("name", "xuefu");
response.addIntHeader("age", 18);
response.addDateHeader("birthday",date.getTime());
response.addHeader("name", "xueli");
response.setIntHeader("age", 20);
}
设置定时刷新的头
response.setHeader("refresh", "3;url=http://www.baidu.com");
重定向头
//没有响应,告知客户端重定向到servlet2
//1设置状态码
response.setStatus(302);
//2.设置响应头Location
response.setHeader("Location", "/WEBpro/servlet2");
封装成一个重定向的方法
response.sendRedirect("/WEBpro/servlet2");
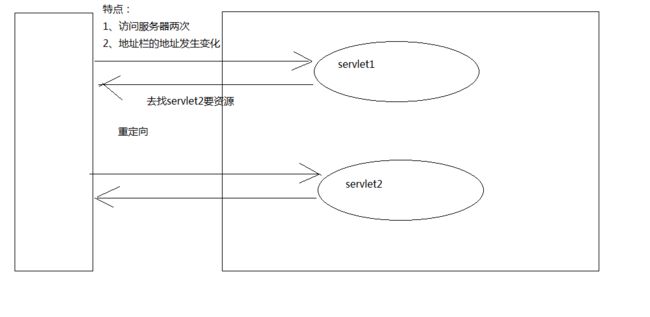
重定向是多次请求,且浏览器地址栏会发生变化
图解重定向
-
response设置响应体
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
PrintWriter writer = response.getWriter();
writer.write("你真美");
}
四 : 中文乱码的原因及解决
原因 :
response缓冲区的默认编码是iso8859-1,此码表中没有中文,需要通过response的setCharacterEncoding(String charset)设置response的编码.
此时页面还是不能显示成中文,因为浏览器的默认编码是本地系统的编码,有可能默认编码是GBK,需要手动修改浏览器的编码为UTF-8,当然还可以在代码中指定浏览器解析页面的方式,通过response的setContentType(String type)方法指定页面解析时编码是UTF-8.
setContentType(String type)不仅能指定浏览器解析页面时的编码,同时也内含setCharacterEncoding(String charset)功能,所以在实际开发中只写setContentType(String type)就好.
解决
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
// TODO Auto-generated method stub
//设置response查询码表
// response.setCharacterEncoding("UTF-8");
//通过头Content-Type告知客户端使用何种码表,写这个上面的可以不用写
response.setHeader("Content-type", "text/html;charset=UTF-8");
//封装的,等价于上面
// response.setContentType("text/html;charset=UTF-8");
PrintWriter writer = response.getWriter();
writer.write("百华真美");
}
五 : 文件下载
-
使用ServletOutputStream完成服务器到客户端的文件拷贝
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
//使用response获得字节输出流
ServletOutputStream out = response.getOutputStream();
//获得服务器上图片
ServletContext context = getServletContext();
String path = context.getRealPath("timg.jpeg");
InputStream in = new FileInputStream(path);
int len = 0;
byte[] buffer = new byte[1024];
while((len = in.read(buffer)) != -1) {
out.write(buffer,0,len);
}
in.close();
out.close();
}
在下载过程中,我们需要告知浏览器文件的类型可文件的打开方式比如,要告诉浏览器这就是一个附件,不需要解析显示.还有在下载中文文件会出现中文乱码或者不显示文件名的情况,原因是不同浏览器对下载文件的编码方式不同,还要解决浏览器兼容问题.
//获取要下载的文件名称
String filename = request.getParameter("filename");
//解决中文参数乱码
filename = new String(filename.getBytes("ISO8859-1"),"UTF-8");
//获得请求头
String agent = request.getHeader("User-Agent");
//根据不同浏览器进行不同的编码
String filenameEncoder = "";
if (agent.contains("MSIE")) {
// IE浏览器
filenameEncoder = URLEncoder.encode(filename, "utf-8");
filenameEncoder = filenameEncoder.replace("+", " ");
} else if (agent.contains("Firefox")) {
// 火狐浏览器
// base64Encoder base64Encoder = new base64Encoder();
// filenameEncoder = "=?utf-8?B?"
// + base64Encoder.encode(filename.getBytes("utf-8")) + "?=";
} else {
// 其它浏览器
filenameEncoder = URLEncoder.encode(filename, "utf-8");
}
//获取文件类型,客户端通过MIME类型区分
response.setContentType(getServletContext().getMimeType(filename));
//告诉客户端不是直接解析,而是以附件的形式打开(下载) filename="+filename 客户端默认对名字进行解码
response.setHeader("content-DisPosition", "attachement;filename="+filenameEncoder);
//获取绝对路径
String path = getServletContext().getRealPath("download/"+filename);
//获取文件的输入流
InputStream in = new FileInputStream(path);
//获得输出流
ServletOutputStream out = response.getOutputStream();
//文件拷贝
int len = 0;
byte[] buffer = new byte[1024];
while((len = in.read(buffer)) != -1) {
out.write(buffer, 0, len);
}
in.close();
out.close();//这个会其实会自动关闭,写不写都行
}
其中response获得的流不需要手动关闭,Tomcat容器会帮助我们关闭
getWriter与getOutPutStream不能同时调用