我们学任何一门语言和框架,都要从hello world学起。cuda的hello world可以是:
#include
#include
#include
#include
__global__ void add(float *dx, float *dy)
{
int id = blockIdx.x * blockDim.x + threadIdx.x;
dy[id] += dx[id];
}
int main()
{
int N = 1 << 20;
float *hx, *hy, *dx, *dy;
hx = new float[N];
hy = new float[N];
cudaMalloc(&dx, N * sizeof(float));
cudaMalloc(&dy, N * sizeof(float));
for (int i = 0; i < N; i++)
{
hx[i] = 1.0f;
hy[i] = 2.0f;
}
cudaMemcpy(dx, hx, N * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(dy, hy, N * sizeof(float), cudaMemcpyHostToDevice);
int threadNums = 256;
int blockNums = (N + threadNums - 1) / threadNums;
add << > >(N, dx, dy);
cudaDeviceSynchronize();
cudaMemcpy(hy, dy, N * sizeof(float), cudaMemcpyDeviceToHost);
float maxError = 0.0f;
for (int i = 0; i < N; i++)
maxError = std::max(maxError, std::abs(hy[i] - 3.0f));
printf("Max error: %.6f", maxError);
delete[] hx;
delete[] hy;
cudaFree(dx);
cudaFree(dy);
return 0;
}
首先要注意,这段代码文件的后缀名是.cu。cuda有两种文件后缀名,.cu和.cuh,相当于c++中.cpp和.h的关系。
程序要做的就是两个向量x、y的相加:y += x。向量长度为2^20。下面我将逐行分析这段代码:
1.引入c++头文件
#include
#include
2.引入cuda头文件
#include
#include
3.向量相加核函数(kernel)
__global__ void add(float *dx, float *dy)
{
int idx = blockIdx.x * blockDim.x + threadIdx.x;
dy[idx] += dx[idx];
}
核函数是运行在gpu上的函数,能在很多线程上并行运行。
n是向量的长度,dx和dy分别是指向向量的指针。blockIdx和threadIdx分别是当前block和thread的下标,gridDim是block的数量,blockDim是一个block里thread的数量。blockIdx、threadIdx、gridDim、blockDim的关系如下图所示(gridDim没有画出,grid和block的关系其实就相当于block和thread的关系):

id定位到具体的thread下标,正好也等于数组的下标(每个线程对应一个数组的元素)。
4.main函数入口
int main()
5.初始化向量数据
int N = 1 << 20;
float *hx, *hy, *dx, *dy;
hx = new float[N];
hy = new float[N];
cudaMalloc(&dx, N * sizeof(float));
cudaMalloc(&dy, N * sizeof(float));
for (int i = 0; i < N; i++)
{
hx[i] = 1.0f;
hy[i] = 2.0f;
}
cudaMemcpy(dx, hx, N * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(dy, hy, N * sizeof(float), cudaMemcpyHostToDevice);
N为向量长度。hx、hy为host,即cpu端的数据;dx、dy为device,即gpu端的数据。host数据使用new分配,device数据使用cudaMalloc分配。device数据分配完毕之后,需要使用cudaMemcpy将host数据拷贝到device数据上。
int threadNums = 256;
int blockNums = (N + threadNums - 1) / threadNums;
add << > >(N, dx, dy);
threadNums指的是一个block中有多少thread,即上面add函数中的blockDim;blockNums指的是block的数量,对应gridDim。
add <<
gridDim和blockDim都是Dim类型,可以是Dim1、Dim2和Dim3,即可以是一维、二维和三维。gridDim每个维度最大可以是65535,blockDim的值最大可以是1024。所以理论上我们可以配置的最大线程数量为6553565535655351024 = 2.91017个。需要注意的是,这里的线程指的是软件的线程,硬件上真正能并行的线程数要远远小于这个天文数字,一般来说只有104的数量级。
6.同步gpu线程
cudaDeviceSynchronize();
其实没有必要,详见stackoverflow的解释。
7.计算并打印出最大的误差值
float maxError = 0.0f;
for (int i = 0; i < N; i++)
maxError = std::max(maxError, std::abs(hy[i] - 3.0f));
printf("Max error: %.6f", maxError);
8.释放资源
delete[] hx;
delete[] hy;
cudaFree(dx);
cudaFree(dy);
最后打印的结果当然不出所料,是0。
我们可以写一段对应的c++程序:
#include
#include
int main()
{
int N = 1 << 20;
float *x, *y;
x = new float[N];
y = new float[N];
for (int i = 0; i < N; i++)
{
x[i] = 1.0f;
y[i] = 2.0f;
}
for (int i = 0; i < N; i++)
{
y[i] += x[i];
}
float maxError = 0.0f;
for (int i = 0; i < N; i++)
maxError = std::max(maxError, std::abs(y[i] - 3.0f));
printf("Max error: %.6f", maxError);
delete[] x;
delete[] y;
return 0;
}
最后可以做一个简单的profile(使用c++11的chrono计时器):
**cuda:
std::chrono::time_point begin = std::chrono::system_clock::now();
add << > > (N, dx, dy);
std::chrono::time_point end = std::chrono::system_clock::now();
std::chrono::duration elapsedTime = end - begin;
printf("Time: %.6lfs\n", elapsedTime.count());
结果:
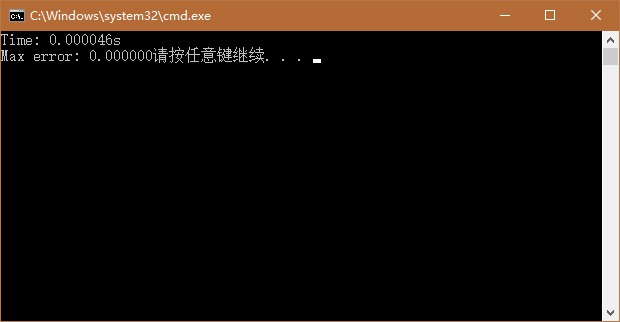
c++:
std::chrono::time_point begin = std::chrono::system_clock::now();
for (int i = 0; i < N; i++)
{
y[i] += x[i];
}
std::chrono::time_point end = std::chrono::system_clock::now();
std::chrono::duration elapsedTime = end - begin;
printf("Time: %.6lfs\n", elapsedTime.count());
结果:
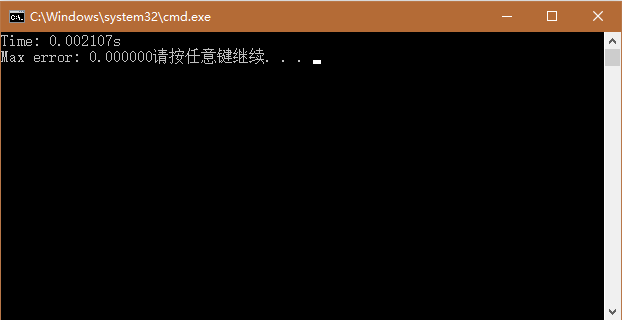
可以看到,在这个例子中,cuda比c++快了近 两个数量级!
feel the power of cuda!