前言:
今天,来处理一个曾经遇到过的问题,即从pdf文档中读取内容,然后导入到excel中,这个也是我们经常遇到的,特别是一些经常出入货的公司,这种文件又多,手工输入又是很繁琐。用Uipath自动化来处理正好合适。
需求:
从PDF文档中提取指定字段,并存入excel中。如下图发票:

![]()
需要把红色圈起的部分提取出来,存入excel中,excel的格式和图中格式一样。本次只处理提取这部分,其它的大家可以下来后再尝试。
操作步骤:
1、打开uipath,新建流程GetPDF2Excel。
![]()
2、拖入构建数据表活动,然后点击活动上的“数据表”,可以看到如下的界面:

![]()
3、构造字段,此字段是最终输出Excel的内容:

![]()
4、从左侧活动中拖入“读取PDF文本”(若是没有PDF活动,需要安装,具体的安装过程,见后面对PDF Activities的安装)

![]()
5、设置PDF的相关内容:

![]()
此处主要设置这几项,若是pdf有多页,可以在范围中进行设置读取那一部分。
6、添加一个“写入行”活动,用来查看我们读取PDF的内容是否成功:

![]()
7、点击“运行”,查看执行的结果:

![]()
从此图中可以看到,发票上的文字都被提取了出来,需要导出的内容就是红色方框中的部分。后面就是怎么把这些内容转换成需要的内容了。
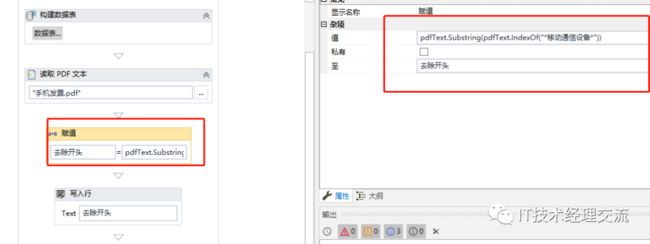
8、先把前面无关的部分去除掉,使用“赋值”活动,这里我家定位到“*移动通信设备*”,从这里开始截取。
![]()
9、运行看处理的结果:

![]()
开头无关的内容已经去除了。
10、去除后续无关的内容,从内容可以看到,我们要取的内容占了三行,而第四行又和第一行类似,因此,我们继续用“*移动通信设备*”分割,不过这次是从新字符串的头开始取。再使用一个“赋值”活动:

![]()
此处,indexof的第二个参数是开始查找的位置,可以根据长度来,写成
“去除开头.Substring(0, 去除开头.IndexOf("*移动通信设备*", "*移动通信设备*".Length))”
11、这次运行后的结果如下:

![]()
此时,已经非常接近我们所要的结果了。
12、把字符串用“回车换行”进行分割,再使用一个“赋值”活动:

![]()
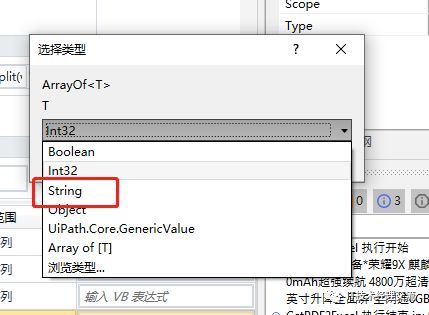
注意,此时有小感叹号,表示类型不对,split函数使用后,得到的结果是个数组类型,所以Lines的定义必须是数组类型,在参数中设置类型:

![]()
![]()
最终结果如下:

![]()
感叹号消失了。
13、使用遍历循环查看下得到的结果:

![]()
可以发现结果是正确的,但是多了几行的空行。
14、分割字符串时,加入StringSplitOptions.RemoveEmptyEntries选项就能达到去除空白行的结果,如下图:

![]()
到此处,剩下的数据已经不多了,不过第一行(显示中的0行)还需要再次分割才能得到结果。而把第二、三行拼接在第一行第一个字段下就可以了,下面我们就来做这个操作。
15、 分割第一行,

![]()
可以看到,分割后的结果是正确的,不过却多了好几项,原因是把名称字段内本身存在空格,这里为了方便,我们就采取简单的处理办法,把需要合并到一起的项合并起来.
16、合并第一列的数据:

![]()
然后与发票中的数据对照:

![]()
可以看到,第一行第一列的数据已经处理成功,然后把第二、三行的合并过来就可以了;
17、获得完整的名称,使用一个“赋值”活动,操作如下:

![]()
完整的名称到此就获取完成,
18、把获取到的数据插入到数据表中:

![]()
19、把结果写入excel中:

![]()
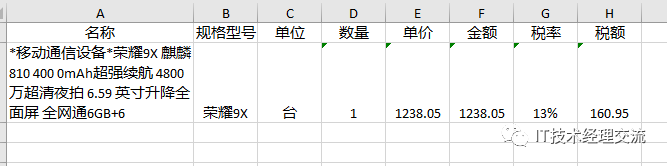
20、查看Exce的结果
![]()
对比发票上的相关数据:

![]()
数据是一致的,大功告成。
PS:
PDF Activities的安装
1、选择管理程序包:

![]()
2、在搜索框中输入PDF,按如下顺序操作:

![]()
3、接受“许可证接受”

![]()
4、可以在活动中,应用程序集成下面看到PDF控件,即表示安装成功,如下图:

![]()
=======================================
本篇内容有些多,大家可以参考使用,在阅读过程中若是有什么不明白的,可以在下方讨论区留言。
也可以关注我的微信公众号:IT人的成长
