描述
最近在python中开发一个人工智能调度平台,因为计算侧使用python+tensorflow,调度侧为了语言的异构安全性,也选择了python,就涉及到了一个调度并发性能问题,因为业务需要,需要能达到1000+个qps的业务量需求,对python调度服务的性能有很大挑战。
具体的架构如下面所示: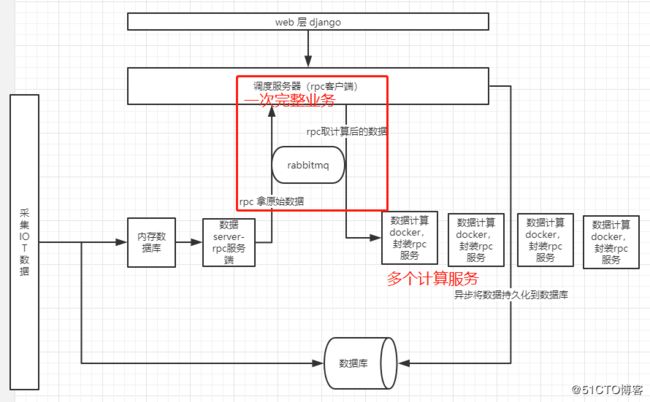
补充:
架构中使用的python为cpython,解释执行的语言,并非jpython或者pypython,cpython的社区环境比较活跃,很多开发包都是现在cpython下实现的,比如项目中计算模块用到的tensorflow,numpy等等。
下文讨论的均为cpython语言。
问题
目前数据计算服务每个服务负责一类数据的解析,暂时还没有问题,并且docker计算可以调度到其他机器上,暂时不构成性能瓶颈
在调度服务器rpc客户端上需要每秒需要完成1000+次业务,一次业务包括rpc调度一次原始数据,再rpc调度给计算服务进行计算拿返回结果再异步入库,此时在使用python调度rpc io的时候使用不同的方法会有不同的性能表现。
如下几种方案进行项目执行和改造
顺序执行
将1000多业务顺序执行,假如python程序只有这么一个进程,并且机器上其他进程不会跟他抢占cpu资源(任何语言一个进程在不开线程的情况下最多只能同时使用一个cpu核心,python语言一个进程就算开了线程,也只能最多同时用一个cpu核心,或者用0个,处于阻塞状态),所有业务的代码块均顺序循环执行,内行代码只能用cpu一个核心依此进行顺序执行,显然不可取,任何io需要等待的地方cpu就都在那里等待执行,执行完一次任务再循环执行下一次,性能低下,每次业务都是串行的。
多线程执行
with concurrent.futures.ThreadPoolExecutor(max_workers=MAX_WOKERS) as executor:
for (classify, sensorLists) in classifySensors.items():
print(f'\ncurrent classify: {classify}, current sensors list: {sensorLists}')
try:
executor.submit(worker,classify,sensorLists)
except Exception as e:
print(e)首先简单说一下操作系统cpu内核是如何对多线程/多进程进行调度的,多线程/多进程的作业调度都是在操作系统内核层进行调度的,操作系统根据线程/进程的优先级或者是时间片是否用完或者是否阻塞来判断是否要将cpu时间片切换到其他进程/线程,某些进程/线程还可以根据锁机制进行抢占cpu资源等等,如果cpu比较空闲,那么当前线程/进程或可以一直占用着一个cpu核心,再讨论一下当前python进程中的线程是如何被系统调度到cpu运行的,如果当前机器有多个核心,并且没有其他任务占用,当前调度服务进程通过多线程/线程池调度一个多线程的业务作业,由于python解释型语言,在当前这个python进程中的各个线程执行方式如下:
1.获取GIL锁
2.获取cpu时间片
3.执行代码,等待阻塞(sleep或io阻塞或耗时操作)或其他线程抢占了cpu时间片
4.释放GIL锁,切换到其他线程执行,重复从步骤1开始。
可见,python中某个线程想要执行,必须先拿到GIL锁,在一个python进程中只有一个GIL锁。
所以python多线程情况下因为其解释下语言的特征,多了一个GIL锁,一个进程的多线程之间也只能同时最多占用一个cpu资源,但是一个线程io等待的时候可以切换到另一个线程进行运行,不用串行等前一个线程io完成之后再进行下一个线程,所以此时多线程就可以有并发的效果,但是不能同时占用多个cpu核心,线程不能并行执行,只能在一个等待的时候另一个并发执行,达到一个并发效果,qps比串行执行情况要好。
协程执行
对于 进程、线程,都是有内核进行调度,有 CPU 时间片的概念,进行 抢占式调度(有多种调度算法),对于 协程(用户级线程),这是对内核透明的,也就是系统并不知道有协程的存在,是完全由用户自己的程序进行调度的,因为是由用户程序自己控制,那么就很难像抢占式调度那样做到强制的 CPU 控制权切换到其他进程/线程,通常只能进行协作式调度,需要协程自己主动把控制权转让出去之后,其他协程才能被执行到。
python中使用aysnc定义协程方法,方法中耗时操作定义await 关键字(这个由用户自己定义),当执行到await的时候,就可以切换到其他协程去运行,这样在这个python进程中的这个cpu核心中该协程方法如果需要多次调用,就会通过用户自定义的aysnc+await携程方法在需要的时候将cpu时间片让给其他协程,同样达到了并发的效果,由于协程的切换开销比较小,并且不涉及系统内核维护维护线程,保存现场等操作,所以在python中协程用的好的话,并发效果会比多线程好。可以参考tornado的底层协程实现gen.coroutine装饰器的实现源码来理解协程的底层实现:
参考资料:
https://note.youdao.com/ynoteshare1/index.html?id=e78ce975a872b2bdd37c7bae116790b8&type=note
python的协程底层是靠迭代器和生成器的next来切换协程的,事件是靠操作系统提供的select pool实现的。不过python的协程实现还是只能在当前进程或当前线程中切换,同一时间只能用一个cpu核心,并不能实现并行,只能实现并发,用的好的话并发效果比python的多线程好。
多进程执行
首先操作前面讲的操作系统对线程/进程的调度方法,python中某个线程想要执行,必须先拿到GIL锁,在一个python进程中只有一个GIL锁。那么在解释执行语言python中,可以进行多进程的模式设计,进程运行的时候能单独申请一部分内存空间和独立的cpu核心,进程空间有一定的独立性,所以每个进程单独拥有独立的GIL锁,python多进程就可以实现并行的效果,在qps的运行效果上比协程和多线程效果好多了。
多进程+协程
多进程能充分利用cpu核心数,协程又能挖掘单个核心的使用率,多进程+协程方式调试得到或许会有不一样的效果。一般在io密集型的应用中用协程方式,在计算密集型的场景中用多进程方式,在IO密集和计算密集型的场景中用多进程+协程方式。在我的该项目中,每一次任务需要两次io,一次计算,虽然计算已经在单独的docker中的python进程中,但是对于每一次任务中计算的时间还是串行在一起的,也会影响整体的qps的效果,所以此时用多进程+协程效果最好,一类IOT设备的业务放到独立进程,多类IOT设备的业务就可以并行执行,该类iot设备中的多个设备可以通过协程并发,整体的qps效果就会比价不错。
go大法goroutine
本质上,goroutine 就是协程。 不同的是,Golang 在 runtime、系统调用等多方面对 goroutine 调度进行了封装和处理,当遇到长时间执行或者进行系统调用时,会主动把当前 goroutine 的CPU (P) 转让出去,让其他 goroutine 能被调度并执行,也就是 Golang 从语言层面支持了协程。Golang 的一大特色就是从语言层面原生支持协程,在函数或者方法前面加 go关键字就可创建一个协程。
go的写成定义更复杂,比python协程多的是能让协程在操作系统的不同线程中调度。
所以如果要追求性能,将调度服务器用golang重构。
go参考资料:
《golang学习笔记二》电子书
Golang GMP调度模型 https://blog.csdn.net/qq_37858332/article/details/100689667
Golang 之协程详解 https://blog.csdn.net/weixin_30416497/article/details/96665770
分布式改造
如上的各种方法都是从调度服务器单节点的并发能力上进行改造,但是如果无论如何改造并且提高单台服务器资源性能的情况下都不能满足性能要求的话,那就必须进行分布式改造,docker计算节点的分布式改造比较简单,直接上k8s进行调度到同的机器上,难点在于调度服务器上,调度服务器类似于客户端进行rpc io的请求和分发,目前模式是:调度服务client 从client的内存数结构里面拿服务节点信息->直连节点进行服务请求,要进行分布式改造的话,就必须进行业务拆分,拆分成多个调度服务client进行负载承担rpc io的请求和分发,要么按照业务维度进行拆分,将部分类别的iot设备通过一个调度服务client,其他部分类别的iot设备通过其他调度服务client进行调度;要么将调度服务client 精简出来做成无状态的的请求分发器,可以部署多个,只要在网关处先定义好路由分发规则,将rpc io请求到正确的服务端。这两种区别是:
一种是: 多个调度服务client(业务分发路由逻辑在本client里面)--> 多个计算服务
另一种: 多个无状态的请求分发器(无状态,无任何业务分发路由逻辑) --> 业务路由网关 -->多个计算服务
第一种可能调度服务client加载的配置不一样,也即是加载的业务分发路由配置逻辑不一样,第二种是无状态请求分发器是一样的,但是需要维护一个路由网关(取决于用的什么rpc,像grpc就有官方的网关,以及Nginx配套的网关可选,可以动态向网关增加路由配置,然后自动重写网关配置,reload)
如上即可完成分布式的改造,改造成多个调度服务client或者多个无状态的请求分发器+一个业务路由网关,当然两种模式均需要一个zk或etcd进行服务注册和服务发现,多个client或分发器就直接从zk或etcd里拿对应计算服务器资源信息,具体改造模式如下:
第一种: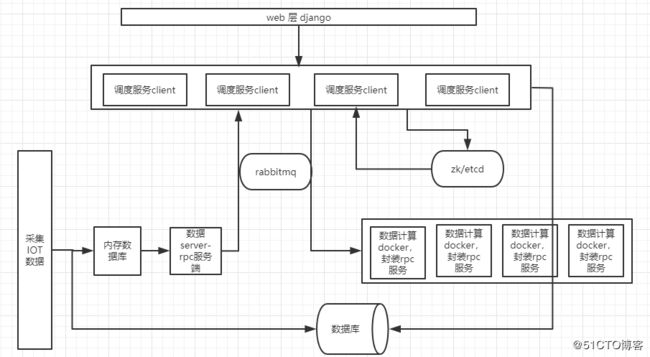
第二种:
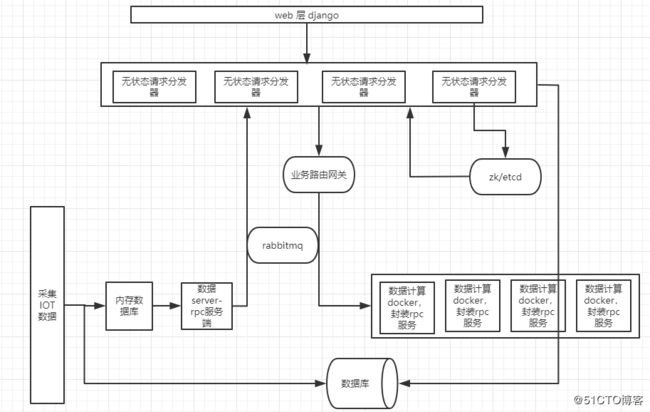
总结
1.python里面一个进程开了多个线程也最多也只能用同时用一个核心,用了协程也最多也只能用同时用一个核心
2.python多进程才能使用多个cpu核心,一个pythonf服务系统里面不同的业务最好开processing进程去跑,要不然无法利用多核cpu性能,本身服务系统的并发能力就上不来。
3.其他语言如java,go 一个进程在开多个线程或多个协程的情况下可以同时用多个核心,go语言天生自带协程属性,并且时可以在操作系统的不同线程中调度的协程。
4.服务系统性能改造主要有两种方法,要么提高单节点并发性能,提高性能时要进行各阶段压力测试,找出性能瓶颈的地方,在针对性的进行性能提升;要么进行系统分布式系统改造,用多个服务器部署多个节点去负载承担业务以提高并发,哪个环节有性能瓶颈就拆分哪里,拆分成多个节点去分担业务并发需求,分布式往往会增加一些组件,造成一些组件单点故障,或者服务一致性,数据一致性等等问题需要考虑。