Visual Studio TFS Branching and Merging Guidance
Origin URL:https://msdn.microsoft.com/en-us/magazine/gg598921.aspx
Bill Heys and Willy-Peter Schaub
Since its inception in 2006, the Visual Studio ALM Rangers team has operated within the Microsoft developer division to promote collaboration between the Visual Studio product groups, Microsoft Services and the Microsoft Most Valuable Professional (MVP) community. The standard vision statement of the Rangers team is to “accelerate the adoption of Visual Studio with out-of-band solutions for missing features or guidance” by addressing missing functionality and removing adoption blockers. The collaboration among the variety of technology and business experts allows the Rangers to empower communities by sharing real-world experience. (You can learn more about the Rangers at msdn.microsoft.com/vstudio/ee358786.)
The Visual Studio Team Foundation Server (TFS) Branching Guide 2010 (tfsbranchingguideiii.codeplex.com) consolidates insightful and practical guidance around branching and merging with Visual Studio TFS 2010 by providing hands-on labs and lessons learned from the community. In this article, we’ll introduce you to some of the advanced branching scenarios that we’re working on for the next guidance version.
Branching: ‘Today’s State of the Nation’
The Rangers Branching Guidance started as a Rangers project after Visual Studio 2005 and TFS 2005 were released. This first release of the Rangers guidance was published on CodePlex in 2007.
In 2008, the Rangers kicked off the Branching Guidance II Project. For this second release, we reorganized the guidance into a set of related documents (Main, Scenarios, Q&A, Diagrams, Posters and so on). Each of the secondary documents was intended to build upon the primary guidance as presented in the Main branching document. Ranger Branching Guidance II was published on CodePlex in late 2008.
In 2009, the Rangers team once again kicked off a new Branching Guidance project: Branching Guidance 2010. This third release focused on showing many new branching features in Visual Studio 2010 and TFS 2010. A key new feature in 2010 is branch visualization.
In part because the latest version is titled Rangers Visual Studio TFS Branching Guide 2010, there has been some apparent confusion whether this guidance applies exclusively to Visual Studio 2010. We want to make it clear that the best practices and guidance presented in the 2010 guidance documents can continue to be applied to earlier versions of Visual Studio and TFS. In fact, the Rangers team has received positive feedback from people using other tools for Source Control Management (SCM).
For 2011, the Rangers team is once again planning an update to the Rangers Branching Guidance.
Feel free to post questions, candid feedback or concerns to the CodePlex site.
Branching Goals and Strategies
A key goal of branching is to provide isolation between parallel streams of work. In the current Rangers Branching Guidance 2010, we tended to focus more on release isolation than on isolation during a complex development initiative.
In many cases, all development activities for the next release of a product can be owned by a single development team. In this simple case, only one development branch is needed to isolate development from ongoing stabilization (Main branch) or sustained engineering (shipping production releases, along with ongoing hotfix and service pack support).
The Rangers often get asked about support for more complex development initiatives where a single development branch doesn’t provide enough flexibility or isolation for a larger product development effort. In the next release of the Rangers Branching Guidance, we’ll be adding more direction in addressing complex development scenarios such as feature team development.
We like to separate branching strategy discussions into two areas:
- How does my organization develop software? Do we have a smaller, simpler team structure or do we need to support more complex teams with parallel development efforts?
- How does my organization release software to its customers, either internal or external? Do we need to support multiple released versions? Do we need to provide hotfixes or service packs?
In some scenarios, an organization’s release strategy may influence the development process, particularly the structure of the development teams. Often, however, the complexity of the release process and branching strategy can be independent from the complexity of the development process and branching strategy.
In designing a branching strategy, consider not only the branching structure, but also the branching process. For example, in the basic branch plan described in Rangers Branching Guidance 2010, there are only three branches (Main, Development and Release). A good branching strategy will describe the branch relationships (for example, Main is a parent to both the Development branch and the Release branch).
In addition, a branching strategy should describe the process implied by the branching structure. For example, how often do you build code in the Main branch? How often do you merge code (forward integration) from the Main branch to the Development branches? What are the conditions for merging code (reverse integration) from a Development branch back to the Main branch and so on? Let’s discuss some typical branching scenarios.
The Feature Team Scenario
Organizations often need a branching strategy to support large, complex development efforts involving multiple development teams or feature teams working in parallel. Questions arise about how many separate development branches are needed. If I have multiple development branches, when and how do I integrate features developed by one team with features developed by other teams? Answers to these questions should be incorporated into a development-branching strategy.
Let’s start by describing a complex development initiative. Although there may be a common release schedule for the entire initiative, there may be several separate feature teams working on independent milestones. As these features are completed and tested, they’ll be integrated into the Main branch.
On a single team, individual developers use local workspaces to isolate their changes from others on their team. Feature Team branches are a good way to isolate changes made by one Feature Team from changes made by other Feature Teams working in parallel on the same product. Without Feature Team isolation, changes made by one team may introduce breaking changes that impact the velocity of other teams.
Creating the branching structure for Feature Team isolation is relatively straightforward. But first, we need to plan for how the Feature Team branches will be integrated later on. Do we add an “integration branch” in between the Main branch and the Feature Team branches, as shown in Figure 1?

Figure 1 Main and Integration Branches
Or do we eliminate the integration layer and integrate the Feature Team changes another way? What’s the best practice recommendation?
We recommend minimizing the number of levels in a branching hierarchy. Adding an integration layer between Main and the Feature Team branches effectively doubles the merges required to move changes between the Main branch and the Feature branches. Branching helps isolate changes, but the cost of branching is the resulting effort needed to merge code between branches and to resolve merge conflicts that always seem to present themselves. Adding an integration layer doubles the merges and likely doubles the effort to resolve merge conflicts.
If we eliminate the integration layer, we reduce the number of layers in our branch hierarchy. But where does the integration of Feature Team 1 and Feature Team 2 happen, and where is the integration tested? In order to keep the Main branch as stable as possible, avoid introducing untested integration changes into the Main branch. Without an integration layer, the merging of features and testing the integration must be done in a controlled fashion in the Feature Team branches themselves.
We recommend doing daily builds in the Main (stable) branch and, following a good daily build, doing a merge from Main to the Development (Feature) branches. Don’t merge code from a Feature branch back to Main until the code in the Feature branch is relatively stable. In other words, the Feature should pass quality assurance gates before it’s merged with Main.
Only when the code in a Feature branch is deemed “ready to release” or “ready to share with other teams” should we consider integrating this Feature branch with Main or with other Feature branches. Figure 2illustrates this process after each “ready to release” milestone.

Figure 2 Feature Branching
Following are the process steps:
- Before merging Feature Team 1 branch with Main, do one final merge (forward integration, or FI) from Main to the Feature Team 1 branch.
- Complete a final test of this integration of code from Main with code in the Feature Team 1 branch.
- Once the code in the Feature Team 1 branch is stable, merge this code (reverse integration, or RI) back to Main.
- At this point, the code in Main incorporates the code from Feature Team 1.
- Perform a build and test in Main, equivalent to the daily build. On the next successful build of Main, merge Main to each of the Feature Team branches. Initially, this will result in Feature Team 1 code being merged with the code in Feature Team 2.
- Test the integration of Feature Team 1 code with Feature Team 2 code in the Feature Team 2 branch.
- When Feature Team 2 code is ready for release or ready to share with other teams, merge Feature Team 2 code back to Main. But first do one final merge from Main to Feature Team 2 and test the final integration.
Note: A key requirement for omitting a separate integration layer is the ability to use automated testing for the integrations. Automated testing helps reduce the impact on code velocity (that is, feature team productivity) as the team works to identify and resolve bugs that arise from merging many changes into a branch.
If automated testing isn’t available for testing integration changes, the risk is that code velocity of the feature teams will be adversely affected as they undertake manual testing to identify and resolve bugs. In this scenario, an organization might consider adding an integration layer between Main and the Feature branches. As we previously noted, the integration layer may result in increased merging and merge conflict resolution. But the benefit could be that having this layer may allow for integration with less impact on code velocity of the feature teams.
A good branching strategy requires a sound branching structure coupled with a sound branching process to ensure maximum code velocity for the Feature Teams while at the same time maintaining the stability of the Main branch.
Common Code-Sharing Scenario
Sharing common code between projects is a challenge for many organizations. There are three main techniques for sharing code between projects or solutions in Visual Studio:
- File linking
- Binary (Assembly) sharing
- Source code sharing
As we discuss elsewhere in this article, there are also several techniques for code isolation:
- Team project isolation
- Branch isolation
- Workspace isolation
Choosing the correct code-sharing strategy for your organization likely involves a combination of code-sharing techniques and isolation techniques.
File Linking: This is a feature of Visual Studio (Add Existing Item) where multiple projects can share a reference to a single source file. File linking is better suited for small projects with a limited number of files being shared. (This resembles file sharing in Visual Source Safe.)
With file linking, there’s only one version of the linked source file to maintain. Changes made to the linked file are immediately received by all projects linking to the file. The disadvantage of file linking is that changes to the linked file should be coordinated with all dependent project teams. Even carefully coordinated changes might cause breaking changes in dependent projects.
Binary Sharing (Assembly References): With binary sharing, a Visual Studio solution references common shared code using assembly references. Here, building or compiling the dependent solution doesn’t also compile the common shared source code. Compiling dependent projects will be faster using assembly references rather than project references.
Teams that own the common code have full ownership and control, which in theory means that the control, versioning and quality of the product is probably better, and branching and merging complexities are avoided.
Because teams reusing the common code don’t have access to the common source code, they’re dependent on the owning team to add new features and resolve bugs in the common shared code.
The assemblies for the common code can be shared by copying them to a well-known file share that can be referenced by dependent projects. Signed assemblies may need to be added to the Global Assembly Cache. Alternatively, the assemblies can be copied from the common code Team Project to a bin folder under the dependent project’s Main branch.
Source Code Sharing: With source code sharing in Visual Studio, a dependent project uses a project reference for the common shared code. When the solution is built, all projects are built, including the common shared code projects. With complex projects, having many project references to shared code may significantly increase build time.
In this scenario, the common shared code is owned and managed by a team in its own TFS Team Project. To share this common code, first branch the code to a folder with the consuming (dependent) project’s Team Project like this:
- Create a folder within the dependent project’s Team Project called “Share” (for example, $\Product1\Share).
- Branch the Main branch of the Common Library (for example, EnterpriseLibrary) to the Share folder of the dependent Project, for example branch $\Enterprise Library\Main to $\Product1\Share\EnterpriseLibrary.
- Add the appropriate common code projects to the dependent project’s solution.
- Create project references from the dependent project to the existing common code projects in the solution.
Note: Nested branches aren’t supported in TFS 2010. A nested branch error might arise when you try to perform a branch operation that would cause a new branch to be created (either above or below) an existing branch in the folder structure (see Figure 3 ).
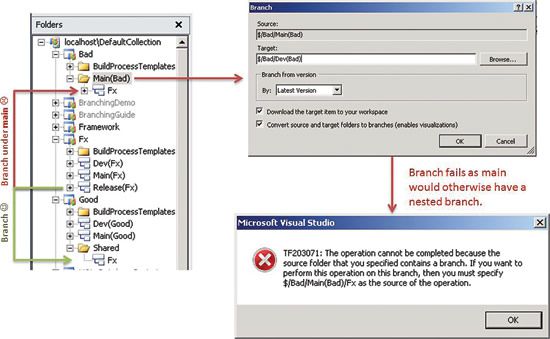
Figure 3 Example of a Nested Branch Causing an Error in Team Foundation Server 2010
Your organization needs to decide whether changes to the common shared source code should be allowed within each dependent project. To prevent changes, after branching from the Common Library the new branch can be made read-only. All changes to the common code source must then be made in the Common Library Team Project and merged into the dependent projects’ Team Projects.
Alternatively, changes can be made to the shared code source within a dependent Team Project. These changes can be merged (through reverse integration) back to the Common Library Team Project. Your organization needs to carefully manage these changes to avoid incompatibilities that make merging these changes back to the Common Library difficult or impossible, perhaps resulting in multiple copies of the shared code.
Architecture Tooling and Modeling Scenario
In Visual Studio Ultimate, you can create UML and Layer models that exist in their own separate Visual Studio projects and can contain many packages, dealing with different parts of the solution (see the Architecture Tooling Guidance at vsarchitectureguide.codeplex.com and Modeling the Application atmsdn.microsoft.com/library/57b85fsc.aspx).
To explore whether branching and merging is possible with models, we can create a simple test environment with three scenarios, as shown in Figure 4.

Figure 4 Evaluation Scenarios in a Test Environment to Test Possibility of Branching and Merging
We can create a Main branch, with a solution that contains a model project with an empty UML class diagram as a hypothetical stable project. We can then branch Main to Scenario1, Scenario2 and Scenario3, then branch each Scenario to a Dev1 and Dev2 branch representing development teams, as shown in Figure 5.

Figure 5 BranchingDemo Team Project, as Viewed in the Source Explorer
It’s obvious that we have no issue with branching, but can we reverse integrate(merge) changes in the model?
In Scenario1, the teams make no model changes, and with Scenerio2 only one of the two teams expands the models. The resultant RI from the Development branches to the associated scenario branch is uneventful with the unchanged Scenario1 model and the updated Scenario2 model.
Scenario3 is a more realistic example where both teams update the model. Dev1 Team creates two classes and Dev2 Team creates one class.
The assiduous reader will notice that both teams created a Class1 class, with different operations.
Reverse integrating the first of the two development branches back to the Scenario3 branch gives the false sense of security that the merge will be easy. But when the second team merges changes to the Scenario3 branch, conflicts for three files (.classdiagram, .layout and .uml) block the check-in, as shown in Figure 6.

Figure 6 A Merge Causes Conflicts Due to the Changes Made by Two Teams of the Class1 Class
We could select the options “Keep Target Branch Version” or “Take Source Branch Version” and answer the question whether merging is possible with a “yes.” The result, however, would be a very unhappy team losing its changes. The alternative is to select the “Merge Changes in Merge Tool” option for a manual merge, which is impractical, unintuitive and error-prone for most of us.
The branching and merging of architecture models is therefore possible, but is it recommended? The problem with the UML model is that the visualizations—for example, the class diagram—are spread across three main files (.layout, .classdiagram and .uml) as shown in Figure 7.

Figure 7 Visualizations Spread Across Three Main Files
The .layout file defines the size and positions of the shapes in the model. The .uml file is the “master” model, and the .classdiagram file holds a cache of the content from the .uml file, which is present in the diagram.
Merges are also difficult, as normal edits in the modeling tools are validated and often augmented by the tool to avoid invalid states. Such validation doesn’t happen in a pure XML merge, which causes the risk of creating invalid models that might not even open.
If each team makes changes only to their diagrams, and if these changes represent classes in separate packages, the problem could be reduced, as most changes would appear in separate files. Even so, inevitably there will be some cases where relationships that cross package boundaries are changed.
In reality, some teams will want to branch when creating new product iterations, which causes forking of source code, documentation and models. Models such as the activity, sequence, layer and class diagram are good examples of models that evolve over iterations, while the delivery team continues with the mainstream development and maintenance. Therefore, models may and often will evolve in two or more branches, which means that we’ll encounter the branching scenario and the often-challenging merge scenario at some point.
All of the current models are good candidates for branching, but none are conducive to merging. With the prospect of a challenging and error-prone merge, the recommendation is twofold:
- Avoid a merge by defining a solution and model view that represents classes in separate packages. The architecture tooling guidance proposes a solution view, shown in Figure 8, and a model view, shown in Figure 9, based on packages. Some care must be taken when diagrams have content from multiple packages, which is possible for Class, Component and Use Case. In this case, to fully avoid conflicts, users must avoid editing the metadata of elements that belong to the “foreign” package.
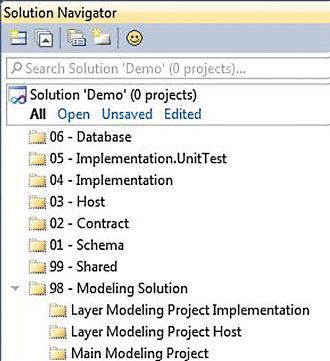
Figure 8 The Proposed Package-Based Structure as Seen in Solution View

Figure 9 The Proposed Package-Based Structure as Seen in UML Model Explorer
- Keep models on a branch that won’t be forked, similar to shared components.
The fallback is to visually and manually edit the models in one branch, using the options “Keep Target Branch Version” or “Take Source Branch Version” options as shown in Figure 10.

Figure 10 A Manual Model Edit Merge
For example, the models diverge in the two branches as shown and are merged manually (step 3) by visually comparing the models and manually updating the model in the top branch. The branch with the consolidated model is then reverse-integrated into Main (step 4) and the other branch with the outdated model is reverse-integrated (step 5) using “Take Target Branch Version” when resolving model conflicts.
In summary, there’s no good story for automatic model merging yet. The recommended strategy is to avoid a branch and merge scenario with the models, or to use the visual and manual model editing before merging.
We’ve now introduced a number of new branching scenarios that you may encounter in a complex real-world environment. In the next article in this series, we’ll investigate team projects and team project collections.
Bill Heys is a senior consultant with Microsoft Americas Consulting Services in New England. As a Visual Studio ALM Ranger, Heys specializes in custom application development and Application Lifecycle Management using Visual Studio. His blog is at blogs.msdn.com/b/billheys.
Willy-Peter Schaub is a solution architect with the Visual Studio ALM Rangers at the Microsoft Canada Development Center. Since the mid-’80s he’s been striving for simplicity and maintainability in software engineering. His blog is at blogs.msdn.com/b/willy-peter_schaub.
Thanks to the following technical experts for reviewing this article: Marcel de Vries, Jens Jacobsen, Bijan Javidi and Alan Wills