
创建Kubernetes集群时,首先出现的问题之一是:“我应该使用哪种类型的node节点,其中有多少个?
如果要构建本地群集,应该订购一些上一代的服务器,还是使用数据中心中的十几台旧计算机?
或者,如果您使用的是诸如Google Kubernetes Engine(GKE)之类的托管Kubernetes服务,是否应该使用八个n1-standard-1或两个n1-standard-4实例来实现所需的计算能力?
集群容量
通常,Kubernetes集群可以看作将一组单个节点抽象为一个大的“超级节点”。
该超级节点的总计算能力(就CPU和内存而言)是所有组成节点的能力之和。
有多种方法可以计算出集群的所需目标容量。
例如,假设您需要一个总容量为8个CPU内核和32 GB RAM的集群。
例如,由于要在集群上运行的一组应用程序需要此数量的资源。
以下是设计集群的两种可能方法:
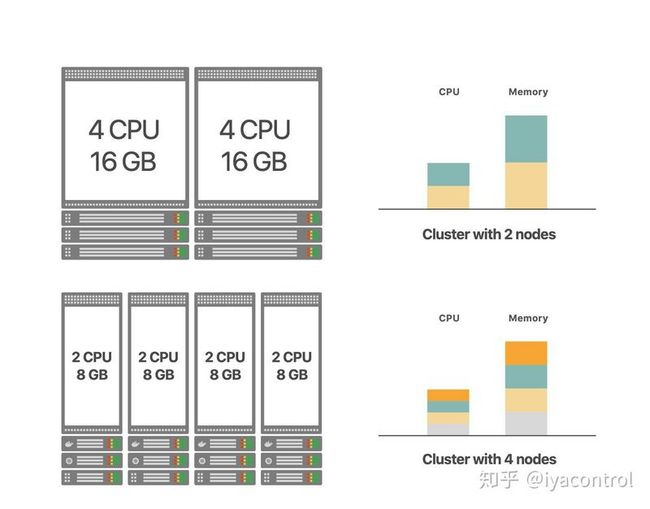
这两个选项都将导致群集具有相同的容量-但左边的选项使用4个较小的节点,而右边的选项使用2个较大的节点。
哪个更好?
为了解决这个问题,让我们看一下“很少有大节点”和“很多小节点”这两个相反方向的利弊。
请注意,本文中的“节点”始终指的是工作程序节点。主节点的数量和大小的选择是一个完全不同的主题。
数量少的大资源节点
在这个方向上,最极端的情况是拥有一个提供全部所需集群容量的单个工作节点。
在上面的示例中,这将是具有16个CPU内核和16 GB RAM的单个工作节点。
让我们看看这种方法可能具有的优势。
1. 较少的管理负担
简而言之,与必须管理大量计算机相比,管理少量计算机较省力。
更新和补丁可以更快地应用,机器可以更轻松地保持同步。
此外,几台机器上的预期故障的绝对数量比多台机器要少。
但是,请注意,这主要适用于裸机服务器,不适用于云实例。
如果您使用云实例(作为托管Kubernetes服务的一部分或您在云基础架构上自己的Kubernetes安装的一部分),则将对基础机器的管理外包给云提供商。
因此,在云中管理10个节点并没有比在云中管理单个节点更多的工作。
2. 更少的成本
虽然功能更强大的机器比低端机器更昂贵,但价格上涨并不一定是线性的。
换句话说,一台具有10个CPU内核和10 GB RAM的计算机可能比10台具有1个CPU内核和1 GB RAM的计算机便宜。
但是,请注意,如果您使用云实例,则这可能不适用。
在主要云提供商Amazon Web Services,Google Cloud Platform和Microsoft Azure的当前定价方案中,实例价格随容量线性增加。
例如,在Google Cloud Platform上,64个n1-standard-1实例的成本与单个n1-standard-64实例的成本完全相同—并且这两个选项都为您提供64个CPU内核和240 GB内存。
因此,在云中,通常无法使用大型计算机节省任何资金。
3. 允许运行占用资源多的应用
拥有大型节点可能只是您要在集群中运行的应用程序类型的要求。
例如,如果您有一个需要8 GB内存的机器学习应用程序,则无法在只有1 GB内存的节点的集群上运行它。
但是您可以在具有10 GB内存节点的集群上运行它。
1. 每个节点运行太多的应用
在更少的节点上运行相同的工作负载自然意味着在每个节点上运行更多的Pod。
这可能成为一个问题。
原因是每个Pod都会在节点上运行的Kubernetes代理上引入一些开销-例如容器运行时(例如Docker),kubelet和cAdvisor。
例如,kubelet对节点上的每个容器执行常规的活动性和就绪性探针-更多的容器意味着kubelet在每次迭代中需要进行更多的工作。
cAdvisor收集节点上所有容器的资源使用情况统计信息,并且kubelet定期查询此信息并将其公开在其API上-再次,这意味着cAdvisor和kubelet在每次迭代中都需要做更多的工作。
如果Pod的数量变大,这些事情可能会开始减慢系统速度,甚至使系统不可靠。、
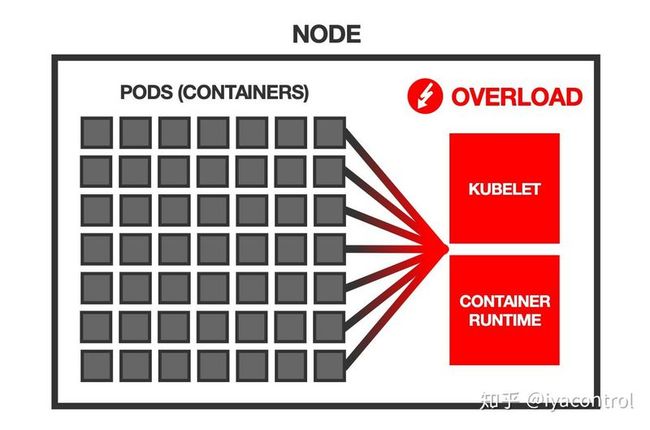
有报告称节点未准备就绪,因为常规的kubelet运行状况检查花费了太长时间,无法遍历节点上的所有容器。
由于这些原因,Kubernetes建议每个节点最多110个Pod。
直到此数目,Kubernetes已经过测试,可以在常见节点类型上可靠地工作。
根据节点的性能,您可能能够在每个节点上成功运行更多的Pod,但是很难预测事情是否会顺利进行或遇到问题。
大多数托管的Kubernetes服务甚至对每个节点的Pod数量施加了硬性限制:
- 在Amazon Elastic Kubernetes服务(EKS)上,每个节点的Pod的最大数量取决于节点类型,范围从4到737。
- 在Google Kubernetes Engine(GKE)上,无论节点类型如何,每个节点的限制为100个pod。
- 在Azure Kubernetes服务(AKS)上,默认限制是每个节点30个容器,但可以增加到250个。
因此,如果计划在每个节点上运行大量的Pod,则可能应该事先测试是否按预期工作。
2. 限制了副本数量
少量节点可能会限制应用程序的有效副本。
例如,如果您有一个由5个副本组成的高可用性应用程序,但是只有2个节点,则该应用程序的有效副本程度将降低为2。
这是因为5个副本只能分布在2个节点上,并且如果其中一个出现故障,它可能会立即删除多个副本。
另一方面,如果您至少有5个节点,则每个副本可以在一个单独的节点上运行,并且单个节点的故障最多会使一个副本崩溃。
因此,如果您具有高可用性要求,则可能需要集群中一定数量的最小节点。
3. 更高的故障影响范围
如果您只有几个节点,那么发生故障的节点的影响会比拥有多个节点的影响大。
例如,如果您只有两个节点,而其中一个发生故障,则大约有一半的Pod会消失。
Kubernetes可以将发生故障的节点的工作负载重新安排到其他节点。
但是,如果只有几个节点,则风险更高,即剩余节点上没有足够的备用容量来容纳故障节点的所有工作负载。
结果是您的应用程序的某些部分将永久关闭,直到您再次启动出现故障的节点为止。
因此,如果要减少硬件故障的影响,可能需要选择更多的节点。
4. 更大的扩容需求
Kubernetes为云基础架构提供了一个集群自动伸缩器,可根据当前需求自动添加或删除节点。
如果使用大节点,则缩放比例将增大,这会使缩放更加笨拙。
例如,如果您只有2个节点,则添加其他节点意味着将群集的容量增加50%。
这可能远远超出您的实际需要,这意味着您需要为未使用的资源付费。
因此,如果计划使用群集自动缩放,则较小的节点将允许更流畅和经济高效的缩放行为。
在讨论了几个大型节点的利弊之后,让我们转到许多小型节点的场景。
许多小节点
这种方法包括由许多小节点而不是几个大节点组成集群。
这种方法的优缺点是什么?
使用许多小节点的优点主要对应于使用少量大节点的缺点。
1. 减少了故障影响范围
如果您有更多的节点,则自然每个节点上的Pod会更少。
例如,如果您有100个Pod和10个节点,则每个节点平均仅包含10个Pod。
因此,如果其中一个节点发生故障,则影响将限制在总工作量的较小部分。
很有可能只有您的某些应用程序受到影响,并且可能只有少量的副本受到影响,因此整个应用程序都不会受到影响。
此外,其余节点上很可能有足够的备用资源来容纳发生故障的节点的工作量,以便Kubernetes可以重新安排所有Pod的时间,并且您的应用程序可以相对较快地返回到完整功能状态。
2. 允许更高的副本数量
如果您已经复制了高可用性应用程序,并且有足够的可用节点,则Kubernetes调度程序可以将每个副本分配给不同的节点。
您可以通过节点亲和性,容器亲和性/反亲和性以及污点和容忍来影响调度程序的容器调度。
这意味着,如果一个节点发生故障,最多将影响一个副本,并且您的应用程序保持可用。
1. node节点数量增多
如果使用较小的节点,则自然需要更多节点才能达到给定的集群容量。
但是,对于Kubernetes控制平面而言,大量节点可能是一个挑战。
例如,每个节点都必须能够与其他每个节点进行通信,这使得可能的通信路径的数量与节点数量的平方成正比增长,所有这些都必须由控制平面进行管理。
Kubernetes控制器管理器中的节点控制器定期遍历集群中的所有节点以运行运行状况检查-节点越多,节点控制器的负载就越大。
更多的节点意味着etcd数据库上的负载也将增加—每个kubelet和kube-proxy都会导致etcd的观察者客户端(通过API服务器),etcd必须将对象更新广播到该客户端。
通常,每个工作节点在主节点上的系统组件上都施加一些开销。
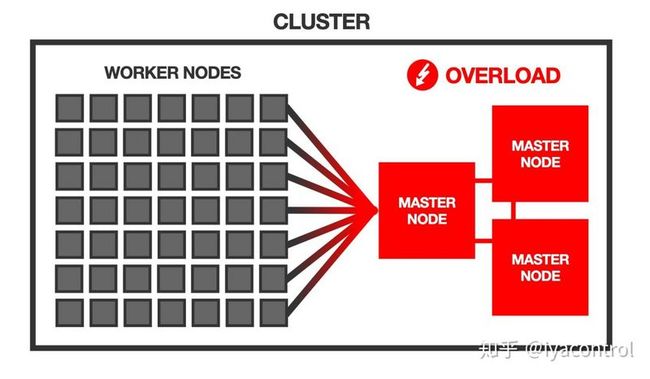
Kubernetes正式宣称支持最多5000个节点的集群。
但是,实际上,500个节点可能已经构成了不小的挑战。
通过使用性能更高的主节点,可以减轻大量工作节点的影响。
这是在实践中完成的工作-这是kube-up在云基础架构上使用的主节点大小:
- Google Cloud Platform
- 5 worker nodes →
n1-standard-1master nodes - 500 worker nodes →
n1-standard-32master nodes - Amazon Web Services
- 5 worker nodes →
m3.mediummaster nodes - 500 worker nodes →
c4.8xlargemaster nodes
如您所见,对于500个工作节点,使用的主节点分别具有32个和36个CPU内核以及120 GB和60 GB的内存。
这些是相当大的机器!
因此,如果您打算使用大量的小型节点,则需要牢记两件事:
- 您拥有的工作节点越多,所需的性能更好的主节点
- 如果计划使用500个以上的节点,则可能会遇到一些性能瓶颈,需要付出一些努力才能解决
Virtual Kubelet之类的新开发可以绕开这些限制,并允许具有大量工作程序节点的集群。
2.更大的系统负载
Kubernetes在每个工作程序节点上运行一组系统守护进程-这些守护进程包括容器运行时(例如Docker),kube-proxy和包括cAdvisor的kubelet。
所有这些守护程序一起消耗固定数量的资源。
如果使用许多小节点,则这些系统组件使用的资源部分会更大。
例如,假设单个节点的所有系统守护程序一起使用0.1个CPU内核和0.1 GB的内存。
如果您有一个包含10个CPU内核和10 GB内存的单个节点,则守护程序将占用集群容量的1%。
另一方面,如果您有10个1 CPU核心和1 GB内存的节点,则守护程序将占用集群容量的10%。
因此,在第二种情况下,您的账单中有10%用于运行系统,而在第一种情况下,仅为1%。
因此,如果您想最大化基础架构支出的回报,那么您可能会希望使用更少的节点。
3. 降低资源利用率
如果使用较小的节点,那么最终可能会遇到大量资源碎片,这些资源碎片太小而无法分配给任何工作负载,因此仍未使用。
例如,假设您所有的Pod都需要0.75 GB的内存。 如果您有10个具有1 GB内存的节点,则可以运行其中的10个Pod,最终在每个不再使用的节点上将获得0.25 GB的内存块。 这意味着浪费了群集总内存的25%。
另一方面,如果您使用具有10 GB内存的单个节点,则可以运行其中的13个Pod,最终只能使用0.25 GB的单个块而无法使用。 在这种情况下,您只会浪费2.5%的内存。
因此,如果要最大程度地减少资源浪费,使用较大的节点可能会提供更好的结果。
4. 小节点对于Pod的限制
在某些云基础架构上,小节点上允许的最大Pod数量比您预期的受到更多限制。
Amazon Elastic Kubernetes服务(EKS)就是这种情况,其中每个节点的Pod的最大数量取决于实例类型。
例如,对于一个t2.medium实例,Pod的最大数量为17,对于t2.small来说,其最大数量为11,对于t2.micro,则为4。
这些是非常小的数字!
任何超出这些限制的Pod都不会被Kubernetes调度程序调度,并且会无限期地处于Pending状态。
如果您不了解这些限制,则可能会导致难以发现的错误。
因此,如果您打算在Amazon EKS上使用小型节点,请检查每个节点对应的pods限制,并两次计数节点是否可以容纳您的所有Pod。
结论
因此,您应该在集群中使用几个大型节点还是多个小型节点?
与往常一样,没有确定的答案。
您想要部署到集群的应用程序类型可能会指导您做出决定。
例如,如果您的应用程序需要10 GB的内存,则您可能不应使用小型节点-集群中的节点应至少具有10 GB的内存。
或者,如果您的应用程序需要10倍的复制才能实现高可用性,那么您可能不应该仅使用2个节点-您的集群至少应包含10个节点。
对于介于两者之间的所有方案,它取决于您的特定要求。
上述哪些利弊与您有关?哪个不是?
话虽如此,没有规则要求所有节点的大小都必须相同。
没有什么可以阻止您在集群中混合使用不同大小的节点。
Kubernetes集群的工作节点可以完全异构。
这可能允许您权衡这两种方法的利弊。
最后,最好的方法就是尝试并找到最适合您的组合!
PS:本文属于翻译,原文