改善深度学习训练的trick总结 | CSDN博文精选

扫码参与CSDN“原力计划”
作者 | ZesenChen
来源 | CSDN博客精选
在深度学习中,同样一个模型用不同的初始化,数据处理,batch size,学习率,优化器都能得到不同性能的参数。我根据自己参与过的比赛中经常用到的一些trick进行大致的总结,有代码的会顺便附上,方便自己以后使用。
学习率调整
在训练模型过程中,我们可以使用固定的学习率,但一些研究工作显示在模型训练过程中使用动态的学习率有助于加速收敛,在更少的epoch里得到更好的模型精度。
CLR
https://arxiv.org/pdf/1506.01186.pdf
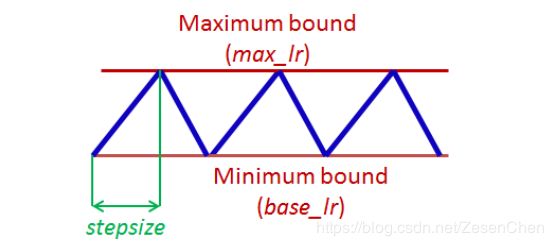
在每个batch/epoch训练结束后调整学习率,而且在一定范围内呈周期性变化,有助于用更少的迭代次数得到更优的参数。CLR一般有三中参数调整模式:‘exp_range’,‘triangular’和’triangular2’;下图是’triangular2’模式。
代码链接
pytorch版本:
https://github.com/anandsaha/pytorch.cyclic.learning.rate
keras版本:
https://www.kaggle.com/shujian/single-rnn-with-4-folds-clr
参数设置
1、其中stepsize最好设置为一个epoch迭代次数的2~10倍;
2、base_lr是最低学习率,max_lr是最高学习率,max_lr最好设置为base_lr的3到4倍;
3、一共有三种周期变化模式:trianglar、triangular2、exp_range,在论文中,后两者表现更好。
余弦退火
在采用批次随机梯度下降算法时,神经网络应该越来越接近Loss值的全局最小值。当它逐渐接近这个最小值时,学习率应该变得更小来使得模型不会超调且尽可能接近这一点。余弦退火(Cosine annealing)利用余弦函数来降低学习率,进而解决这个问题,如下图所示:
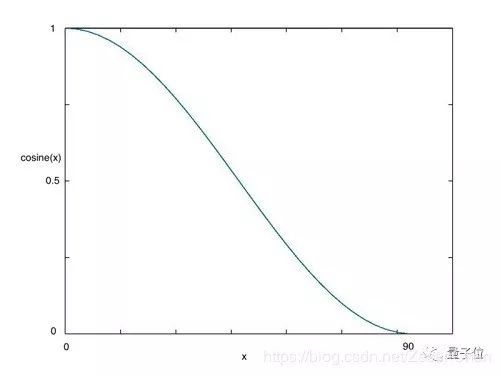
该调整学习率的方法pytorch是自带的,在torch.optim.lr_scheduler模块中,函数名为CosineAnnealingLR,用法可以参考pytorch文档:https://pytorch.org/docs/master/optim.html#how-to-adjust-learning-rate。
SGDR
https://arxiv.org/pdf/1608.03983.pdf
神经网络在训练过程中容易陷入局部最优值,SGDR通过梯度下降过程中突然提高学习率来跳出局部最优值并找到通向全局最优值的路径。这种方式称为带重启的随机梯度下降。

代码链接
keras版本:
https://github.com/emrul/Learning-Rate
参数设置
1、min_lr:最小学习率,max_lr:最大学习率;
2、base_iterations:第一个下降周期的长度,mul_iterations:后面每个下降周期是之前下降周期的几倍;
3、使用SGDR回调函数的时候记得把模型的优化器设置为’sgd’;
Switch Adam to SGD
https://arxiv.org/pdf/1712.07628.pdf
前期用Adam优化器,迅速收敛,后期切换到SGD,慢慢寻找最优解。
集成手段
在传统集成方法中,stacking与bagging是比较主流的方法,stacking即是训练一些不同的模型在同一批数据上得到不同的预测结果,将预测结果作为新的特征,最后用一个上层的模型学习这些新特征到目标之间的映射关系,如果是用的线性分类器,那也可以称为blending。这种方法在深度学习中当然也是适用的,但需要多个基模型的训练,比较耗时。所以有相关的研究工作提出了单模型集成的方法。
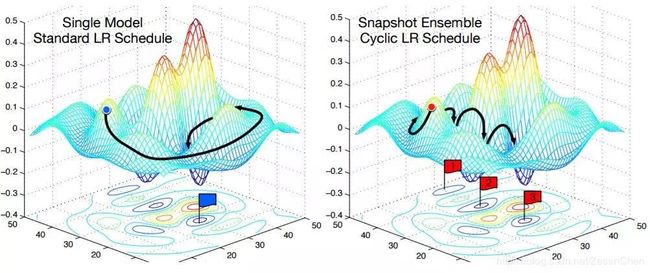
Snapshot Ensemble
https://openreview.net/pdf?id=BJYwwY9ll
神经网络在训练过程中容易陷入局部最优值,快照集成方法把每个epoch中的局部最优参数保存下来,并最终取各个模型的平均。该方法属于单模型集成,不需要耗费额外的训练代价,而且适合与防止局部最优的方法结合使用。
代码链接
keras版本:
https://github.com/titu1994/Snapshot-Ensembles
FGE
https://arxiv.org/pdf/1802.10026.pdf
FGE采用线性分段循环学习策略代替余弦;每个循环只有2到4个epoch。由于在足够多的不同模型间,存在低损失的连接通路,沿着这些通路,采用短循环是可行的,而且在这一过程中,会产生差异足够大的模型,集成这些模型会产生很好的结果。与快照集成相比,FGE提高了模型的性能,每次循环经过更少的epoch就能找到差异足够大的模型(训练速度更快)。
SWA
https://arxiv.org/pdf/1803.05407.pdf
1、每次学习率循环结束时产生的局部最小值趋向于再损失面的边缘域累积,这些边缘区域上的损失值较小(W1,W2 and W3) 。通过对这几个这样的点取平均,很有可能得到一个更低损失的全局化的通用解(下图中的Wswa)。即在权重空间而不是模型空间对这些点进行平均。
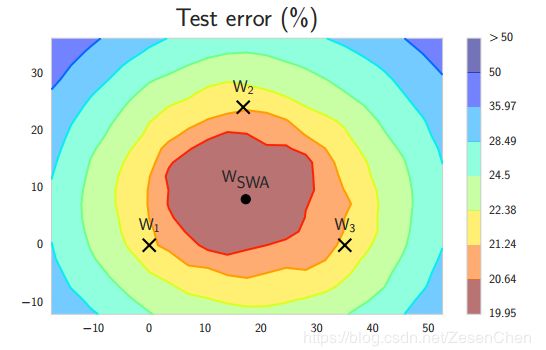
2、FGE集成对k个模型集成的测试预测需要k倍的计算时间。但SWA可以解释成FGE集成的近似值,且只需单个模型的测试时间。
3、相较于SGD, SWA能够使所取得的解在本质上具有更好的优化。SGD一般收敛于最优点的宽阔平坦区域边界附近的点;此外,SWA能够找到一个位于该地区中心的点。
代码链接
keras版本:https://github.com/xuyiqiang-learn/SWA_keras
点击阅读原文,查看作者更多文章!
技术的道路一个人走着极为艰难?
一身的本领得不施展?
优质的文章得不到曝光?
别担心,
即刻起,CSDN 将为你带来创新创造创变展现的大舞台,
扫描下方二维码,欢迎加入 CSDN 「原力计划」!

(*本文为AI科技大本营转载文章,转载请联系作者)
◆
精彩推荐
◆
开幕倒计时 2 天!2019 中国大数据技术大会(BDTC)即将震撼来袭!豪华主席阵容及百位技术专家齐聚,十余场精选专题技术和行业论坛,超强干货+技术剖析+行业实践立体解读。

推荐阅读
陆首群:评人工智能如何走向新阶段?
准备面试题就够了吗?这些内容对考核更重要
一张图生成定制版二次元人脸头像,还能“模仿”你的表情
无需标注数据,利用辅助性旋转损失的自监督GANs,效果堪比现有最好方法
激辩:机器究竟能否理解常识?
Instagram个性化推荐工程中三个关键技术是什么?
从YARN迁移到k8s,滴滴机器学习平台二次开发是这样做的
【建议珍藏系列】如果你这样回答「什么是线程安全」,面试官都会对你刮目相看!
985 高校计算机系学生都在用的笔记本,我被深深地种草了!
从拨号到 5G :互联网登录完全指南

你点的每个“在看”,我都认真当成了AI