redis系列——生产环境Redis集群详解(六)
一、基本介绍
在主从架构中我们知道,每个master node都可以挂载多个slave node。但是每个slave的数据和master中的数据是一致的,如果我们想要在redis中存放更多的数据,就需要redis cluster了。如果你的数据量很少,主要是承载高并发高性能的场景,比如你的缓存一般就几个G,单机足够了。一个mater,多个slave,要几个slave跟你的要求的读吞吐量有关系,然后自己搭建一个sentinal集群,去保证redis主从架构的高可用性,就可以了。redis cluster,主要是针对海量数据+高并发+高可用的场景,海量数据,如果你的数据量很大,那么建议就用redis cluster。
1、redis cluster通信原理
redis cluster节点间采取gossip协议进行通信。跟集中式不同,不是将集群元数据(节点信息,故障,hash slot信息,等等)集中存储在某个节点上,而是互相之间不断通信,保持整个集群所有节点的数据是完整的。每个节点都有一个专门用于节点间通信的端口,就是自己提供服务的端口号+10000,比如7001,那么用于节点间通信的就是17001端口。每隔节点每隔一段时间都会往另外几个节点发送ping消息,同时其他几点接收到ping之后返回pong。
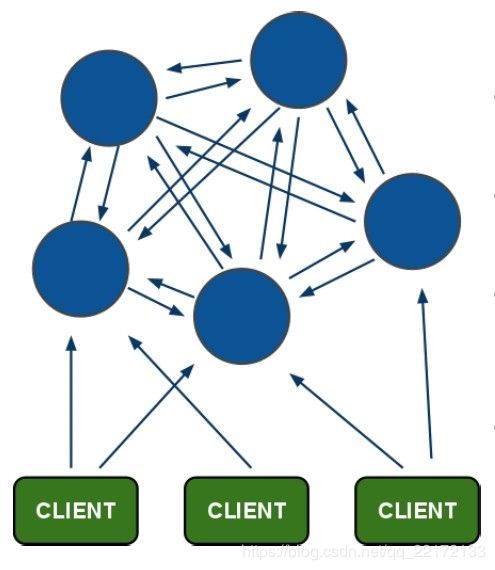
gossip协议包含多种消息,包括ping,pong,meet,fail,等等。我们下面来说明一下各种消息的含义:
- meet:比如某个节点发送meet给新加入的节点(redis-trib.rb add-node,后面讲),让新节点加入集群中,然后新节点就会开始与其他节点进行通信;
- ping:每个节点都会频繁给其他节点发送ping,其中包含自己的状态还有自己维护的集群元数据,互相通过ping交换元数据。每个节点每秒都会频繁发送ping给其他的集群,频繁的互相之间交换数据,互相进行元数据的更新;
- pong:返回ping和meet,包含自己的状态和其他信息,也可以用于信息广播和更新;
- fail:某个节点判断另一个节点fail之后,就发送fail给其他节点,通知其他节点,指定的节点宕机了。
1.ping消息深入
ping消息发送很频繁,而且要携带一些元数据,所以可能会加重网络负担。每个节点每秒会执行10次ping,每次会选择5个最久没有通信的其他节点。当然如果发现某个节点通信延时达到了cluster_node_timeout / 2,那么立即发送ping,避免数据交换延时过长,落后的时间太长了。
比如说,两个节点之间都10分钟没有交换数据了,那么整个集群处于严重的元数据不一致的情况,就会有问题。所以cluster_node_timeout可以调节,如果调节比较大,那么会降低发送的频率。每次ping,一个是带上自己节点的信息,还有就是带上1/10其他节点的信息,发送出去,进行数据交换。至少包含3个其他节点的信息,最多包含总节点-2个其他节点的信息。
2.维护集群的元数据方式比较
集中式:好处在于,元数据的更新和读取,时效性非常好,一旦元数据出现了变更,立即就更新到集中式的存储中,其他节点读取的时候立即就可以感知到;不好在于,所有的元数据的跟新压力全部集中在一个地方,可能会导致元数据的存储有压力。
gossip:好处在于,元数据的更新比较分散,不是集中在一个地方,更新请求会陆陆续续,打到所有节点上去更新,有一定的延时,降低了压力;缺点,元数据更新有延时,可能导致集群的一些操作会有一些滞后。
2、数据分布算法
1.原始Hash算法
在原始的Hash中,就是来了一个Key之后,计算其hash值。然后对节点数量(比如三台,那就是3)取模,取模结果一定在0~2之间,小于节点数量。然后把值打到对应的master node上去就可以了。
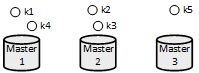
这是最最简单的数据分布算法,但是在高并发的场景来说,是不可以接受的。假如某个master宕机了,首先1/3的数据直接丢失了,并且要重新对剩下的两台master取模,再分配到其他的节点上去。但是最大的问题是,此时所有请求过来,都会基于最新的2个master取模,尝试获取数据,显然几乎取不到任何数据,然后大量的流量将会涌入到数据库中。
2.一致性Hash算法
在一致性Hash算法中会首先虚拟出一个环,然后每一个master节点都放在环上。同样的当key过来时,需要计算出hash值(每一个环上的点都对应一个Hash值),看hash值应该落到哪个位置,然后顺时针放到最近的master节点上即可。

这样即使其中一个master宕机了,因为照着顺时针走,之前的master找不到了,会走到下一个master去,当然也找不到数据,但是其中2/3是可以找到的。不过这里还存在缓存热点问题,即可能集中在某个hash区域的值特别多,那么会导致大量的数据都涌入同一个master内,造成master的热点问题,性能出现瓶颈。我们可以使用一致性hash算法虚拟节点来实现负载均衡,

即给每个master都做了均匀分布的虚拟节点,这样的话,在每个区域内,大量的数据都会均匀的分布到不同的节点内。
3.hash slot算法
这也是redis cluster的数据分布算法,Redis 集群中内置了 16384 个哈希槽,当需要在 Redis 集群中放置一个 key-value 时,redis 先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点,示例如下:

hash slot让node的增加和移除很简单,增加一个master,就将其他master的hash slot移动部分过去,减少一个master,就将它的hash slot移动到其他master上去。移动hash slot的成本是非常低的!并且任何一台机器宕机,另外两个节点不会影响,因为key找的是hash slot,而不是机器。
3、redis cluster主备切换
redis cluster的高可用的原理,几乎跟哨兵是类似的。如果一个节点认为另外一个节点宕机,那么就是pfail,主观宕机。如果多个节点都认为另外一个节点宕机了,那么就是fail,客观宕机,跟哨兵的原理几乎一样(sdown,odown)。在cluster-node-timeout内,某个节点一直没有返回pong,那么就被认为pfail。如果一个节点认为某个节点pfail了,那么会在gossip ping消息中,ping给其他节点,如果超过半数的节点都认为pfail了,那么就会变成fail。
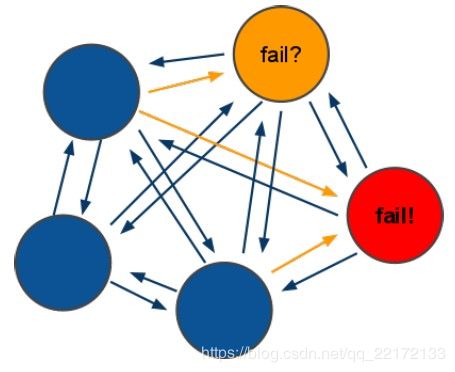
对宕机的master node,从其所有的slave node中,选择一个切换成master node。检查每个slave node与master node断开连接的时间,如果超过了cluster-node-timeout * cluster-slave-validity-factor,那么就没有资格切换成master。这个也是跟哨兵是一样的,从节点超时过滤的步骤。
所有的master node开始slave选举投票,给要进行选举的slave进行投票,如果大部分master node(N/2 + 1)都投票给了某个从节点,那么选举通过,那个从节点可以切换成master。
整个流程跟哨兵相比,非常类似,所以说,redis cluster功能强大,直接集成了replication和sentinal的功能。
二、搭建集群
搭建集群最少也得需要3台主机,如果每台主机再配置一台从机的话,则最少需要6台机器。因为实验没有这么多机器,我们这里就使用三台服务器来搭建:redis_01(129,放7001,7002)、redis_02(130,放7003,7004)、redis_03(131,放7005,7006)。首先我们在每个服务器上都先安装上redis,这里不再描述。安装完成后,创建如下几个文件夹:
mkdir -p /etc/redis-cluster
mkdir -p /var/log/redis
# 其他机器一样
mkdir -p /var/redis/7001
mkdir -p /var/redis/7002然后我们把redis.conf拷贝到/etc/redis-cluster文件夹中,并重命名为7001.conf,修改如下内容:
port 7001
cluster-enabled yes
# 这是指定一个文件,供cluster模式下的redis实例将集群状态保存在那里,包括集群中其他机器的信息,
# 比如节点的上线和下限,故障转移,不是我们去维护的,给它指定一个文件,让redis自己去维护的
cluster-config-file /etc/redis-cluster/node-7001.conf
# 节点存活超时时长,超过一定时长,认为节点宕机,master宕机的话就会触发主备切换,slave宕机就不会提供服务
cluster-node-timeout 15000
daemonize yes
pidfile /var/run/redis_7001.pid
dir /var/redis/7001
logfile /var/log/redis/7001.log
bind 192.168.234.129
appendonly yes同样修改7002~7006几台服务器。然后将redis_init_script脚本拷贝到/etc/init.d目录中,将redis_init_script重命名为redis_7001~redis_7006,并修改里面的端口号和位置等信息(参考安装启动)。
REDISPORT=7001
EXEC=/usr/local/software/redis/bin/redis-server
CLIEXEC=/usr/local/software/redis/bin/redis-cli
PIDFILE=/var/run/redis_${REDISPORT}.pid
CONF="/etc/redis-cluster/${REDISPORT}.conf"
# .......接下来通过脚本启动所有的redis(设置随服务器启动),然后我们进入第一台服务器,将redis解压文件src下的redis-trib.rb文件拷贝到/usr/local/bin目录中。因为集群管理工具(redis-trib.rb)是使用ruby脚本语言编写的。所以需要安装ruby,安装命令为
yum install -y ruby
yum install -y rubygems
gem install redis这里报了一个错
[root@redis_01 init.d]# gem install redis
Fetching: redis-4.1.2.gem (100%)
ERROR: Error installing redis:
redis requires Ruby version >= 2.3.0.因为CentOS 7 yum库中ruby的版本支持到 2.0.0,但是gem安装redis需要最低是2.3.0,所以我们要采用rvm来更新ruby
# 安装curl
yum -y install curl
# 安装rvm
gpg2 --keyserver hkp://keys.gnupg.net --recv-keys D39DC0E3
curl -L get.rvm.io | bash -s stable又报错了!!!
[root@redis_01 init.d]# curl -L get.rvm.io | bash -s stable
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 194 100 194 0 0 65 0 0:00:02 0:00:02 --:--:-- 65
100 24535 100 24535 0 0 2733 0 0:00:08 0:00:08 --:--:-- 5474
Downloading https://github.com/rvm/rvm/archive/1.29.9.tar.gz
Downloading https://github.com/rvm/rvm/releases/download/1.29.9/1.29.9.tar.gz.asc
gpg: 于 2019年07月10日 星期三 16时31分02秒 CST 创建的签名,使用 RSA,钥匙号 39499BDB
gpg: 无法检查签名:没有公钥
GPG signature verification failed for '/usr/local/rvm/archives/rvm-1.29.9.tgz' - 'https://github.com/rvm/rvm/releases/download/1.29.9/1.29.9.tar.gz.asc'! Try to install GPG v2 and then fetch the public key:
gpg2 --keyserver hkp://pool.sks-keyservers.net --recv-keys 409B6B1796C275462A1703113804BB82D39DC0E3 7D2BAF1CF37B13E2069D6956105BD0E739499BDB
or if it fails:
command curl -sSL https://rvm.io/mpapis.asc | gpg2 --import -
command curl -sSL https://rvm.io/pkuczynski.asc | gpg2 --import -
In case of further problems with validation please refer to https://rvm.io/rvm/security根据上面提示,安装前先执行:
gpg2 --keyserver hkp://pool.sks-keyservers.net --recv-keys 409B6B1796C275462A1703113804BB82D39DC0E3 7D2BAF1CF37B13E2069D6956105BD0E739499BDB然后重新执行安装命令,安装完成后修改 rvm下载 ruby的源,到 Ruby China 的镜像
gem sources --add https://gems.ruby-china.com/ --remove https://rubygems.org/查看rvm库中已知的ruby版本
[root@redis_01 init.d]# rvm list known
-bash: rvm: 未找到命令
[root@redis_01 init.d]# source /etc/profile.d/rvm.sh
[root@redis_01 init.d]# rvm list known
# MRI Rubies
[ruby-]1.8.6[-p420]
[ruby-]1.8.7[-head] # security released on head
[ruby-]1.9.1[-p431]
[ruby-]1.9.2[-p330]
[ruby-]1.9.3[-p551]
[ruby-]2.0.0[-p648]
[ruby-]2.1[.10]
[ruby-]2.2[.10]
[ruby-]2.3[.8]
[ruby-]2.4[.6]
[ruby-]2.5[.5]
[ruby-]2.6[.3]
[ruby-]2.7[.0-preview1]
ruby-head
# for forks use: rvm install ruby-head- --url https://github.com/github/ruby.git --branch 2.2
# JRuby
jruby-1.6[.8]
jruby-1.7[.27]
jruby-9.1[.17.0]
jruby[-9.2.7.0]
jruby-head
# Rubinius
rbx-1[.4.3]
rbx-2.3[.0]
rbx-2.4[.1]
rbx-2[.5.8]
rbx-3[.107]
rbx-4[.3]
rbx-head 那下面我们就来安装一个能用的ruby版本
rvm install 2.3.3
# 使用一个ruby版本
rvm use 2.3.3
# 设置默认版本
rvm use 2.3.3 --default
# 卸载一个已知版本
rvm remove 2.0.0
# 查看ruby版本
ruby --version然后再运行gem install redis即可(后面改成3.3.5的)
[root@redis_01 bin]# gem install redis -v 3.3.5
Fetching: redis-3.3.5.gem (100%)
Successfully installed redis-3.3.5
Parsing documentation for redis-3.3.5
Installing ri documentation for redis-3.3.5
Done installing documentation for redis after 1 seconds
1 gem installed注意:ruby gem安装的redis库,版本不能使用最新的4.0(测试3.2.1到3.3.5都可以),否则redis-trib.rb reshard 192.168.2.106:8002 重新分片时会报错误。如果不幸安装了,要先卸载最新redis库。
gem uninstall redis之后再在该台服务器上运行如下命令:
[root@redis_01 bin]# ./redis-trib.rb create --replicas 1 192.168.234.129:7001 192.168.234.129:7002 192.168.234.130:7003 192.168.234.130:7004 192.168.234.131:7005 192.168.234.131:7006
>>> Creating cluster
>>> Performing hash slots allocation on 6 nodes...
Using 3 masters:
192.168.234.129:7001
192.168.234.130:7003
192.168.234.131:7005
Adding replica 192.168.234.130:7004 to 192.168.234.129:7001
Adding replica 192.168.234.129:7002 to 192.168.234.130:7003
Adding replica 192.168.234.131:7006 to 192.168.234.131:7005
M: aa7acb8d250665a270e7246778deeeac92c79839 192.168.234.129:7001
slots:0-5460 (5461 slots) master
S: 5ae3f1af6d4637619ee30c1e3f475dd86b5df271 192.168.234.129:7002
replicates 27f131740e066a1dd2be3a3b318992551ee6cd77
M: 27f131740e066a1dd2be3a3b318992551ee6cd77 192.168.234.130:7003
slots:5461-10922 (5462 slots) master
S: f3951c292478e384721309bc33436c7ca54d8839 192.168.234.130:7004
replicates aa7acb8d250665a270e7246778deeeac92c79839
M: 872ea6d136beb824bd397a8a3eeb23287267e06a 192.168.234.131:7005
slots:10923-16383 (5461 slots) master
S: 99e43238b05317623085f22fe707d1314b46e51b 192.168.234.131:7006
replicates 872ea6d136beb824bd397a8a3eeb23287267e06a
Can I set the above configuration? (type 'yes' to accept): 上面是服务器分配的方案(--replicas 指定每个master有几个slave),我们可以看到slots就是hash槽的分配情况,同时每个master都在不同的服务器上。如果同意,输入yes即可部署完成,如果我们想查看集群状态
[root@redis_01 bin]# ./redis-trib.rb check 192.168.234.129:7001
>>> Performing Cluster Check (using node 192.168.234.129:7001)
M: aa7acb8d250665a270e7246778deeeac92c79839 192.168.234.129:7001
slots:0-5460 (5461 slots) master
1 additional replica(s)
M: 27f131740e066a1dd2be3a3b318992551ee6cd77 192.168.234.130:7003
slots:5461-10922 (5462 slots) master
1 additional replica(s)
S: f3951c292478e384721309bc33436c7ca54d8839 192.168.234.130:7004
slots: (0 slots) slave
replicates aa7acb8d250665a270e7246778deeeac92c79839
S: 5ae3f1af6d4637619ee30c1e3f475dd86b5df271 192.168.234.129:7002
slots: (0 slots) slave
replicates 27f131740e066a1dd2be3a3b318992551ee6cd77
M: 872ea6d136beb824bd397a8a3eeb23287267e06a 192.168.234.131:7005
slots:10923-16383 (5461 slots) master
1 additional replica(s)
S: 99e43238b05317623085f22fe707d1314b46e51b 192.168.234.131:7006
slots: (0 slots) slave
replicates 872ea6d136beb824bd397a8a3eeb23287267e06a
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.也可以在客户端查看集群状态
192.168.234.129:7001> cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:6
cluster_my_epoch:3
cluster_stats_messages_sent:926
cluster_stats_messages_received:926三、数据实验
我们在上面已经把redis cluster搭建起来了,redis cluster,提供了多个master,数据可以分布式存储在多个master上。每个master如果故障,那么久会自动将slave切换成master,高可用。下面我们就对redis cluster的基本功能,来测试一下。
1、实验一:多master写入
我们首先来打开一个客户端创建连接,并写入一些数据
[root@redis_01 bin]# ./redis-cli -h 192.168.234.129 -p 7001
192.168.234.129:7001> set k1 v1
(error) MOVED 12706 192.168.234.131:7005
192.168.234.129:7001> set k2 v2
OK我们发现第一个k1没要写入成功,让重定向到7005上来操作。在redis cluster写入数据的时候,其实是你可以将请求发送到任意一个master上去执行。但是,每个master都会计算这个key对应的CRC16值,然后对16384个hashslot取模,找到key对应的hashslot,找到hashslot对应的master。如果对应的master就在自己本地的话,set k2 v2,k2这个key对应的hashslot就在自己本地,那么自己就处理掉了。但是如果计算出来的hashslot在其他master上,那么就会给客户端返回一个moved error,告诉你,你得到哪个master上去执行这条写入的命令。
什么叫做多master的写入,就是每条数据只能存在于一个master上,不同的master负责存储不同的数据,分布式的数据存储。100w条数据,5个master,每个master就负责存储20w条数据,分布式数据存储。所以当碰到不是该master负责的key时,将让重定向到相应的master执行,现在我们来到redis_03机器上,执行
[root@redis_03 bin]# ./redis-cli -h 192.168.234.131 -p 7005
192.168.234.131:7005> set k1 v1
OK发现就可以执行成功了。在我们使用中,其实可以使用redis-cli -c启动,这样就会自动进行各种底层的重定向的操作。我们重新启动来get(和set一样)一下试试
[root@redis_01 bin]# ./redis-cli -h 192.168.234.129 -p 7001 -c
192.168.234.129:7001> get k1
-> Redirected to slot [12706] located at 192.168.234.131:7005
"v1"
192.168.234.131:7005> get k2
-> Redirected to slot [449] located at 192.168.234.129:7001
"v2"2、实验二:不同master各自的slave读取
我们就来找到7001的slave节点(应该是7004),之前我们在7001中set了一个k2,现在我们就来取一下试试
[root@redis_02 bin]# ./redis-cli -h 192.168.234.130 -p 7004
192.168.234.130:7004> get k2
(error) MOVED 449 192.168.234.129:7001事实上,在这个redis cluster中,如果你要在slave读取数据,那么需要带上readonly指令。我们再来尝试一下
192.168.234.130:7004> readonly
OK
192.168.234.130:7004> get k2
"v2"
192.168.234.130:7004> get k1
(error) MOVED 12706 192.168.234.131:7005可以取到了,当然如果我们想取k1的值,同样可以使用redis-cli -c启动。在这里我们应该发现了redis cluster在读写分离的时候,会有一定的限制性,默认情况下,redis cluster的核心的理念,主要是用slave做高可用的,每个master挂一两个slave,做数据的热备(master挂了之后,切换master马上就有数据),还有master故障时的主备切换,实现高可用的。
redis cluster默认是不支持slave节点读或者写的,跟我们手动基于replication搭建的主从架构不一样的。redis cluster,读写分离,复杂了点,也可以做。但是像我们使用的jedis客户端,对redis cluster的读写分离支持不太好的,默认的话就是读和写都到master上去执行的。如果你要让最流行的jedis做redis cluster的读写分离的访问,那可能还得自己修改一点jedis的源码,成本比较高;要不然就是自己基于jedis,封装一下,自己做一个redis cluster的读写分离的访问api,但是也比较复杂。
一般来说,redis cluster的时候,就没有所谓的读写分离的概念了。我们可以想一下读写分离,是为了什么?主要是因为要建立一主多从的架构,才能横向任意扩展slave node去支撑更大的读吞吐量。而在redis cluster的架构下,实际上本身master就是可以任意扩展的,你如果要支撑更大的读吞吐量,或者写吞吐量,或者数据量,都可以直接对master进行横向扩展就可以了,也可以实现支撑更高的读吞吐的效果。所以说扩容master,跟之前扩容slave,效果是一样的。
3、实验三:自动故障切换
在redis cluster 中我们期望当其中一个master挂掉时,它的slave会切换成master,当被挂掉的master节点恢复时,将会主动作为slave挂载到新的master下。现在便来开始尝试,首先我们来kill掉7001节点(slave节点为7004)。
[root@redis_01 bin]# ps -ef|grep redis
root 19458 1 0 07:48 ? 00:00:45 /usr/local/software/redis/bin/redis-server 192.168.234.129:7001 [cluster]
root 19463 1 0 07:48 ? 00:00:46 /usr/local/software/redis/bin/redis-server 192.168.234.129:7002 [cluster]
root 42649 37356 0 14:04 pts/1 00:00:00 grep --color=auto redis
[root@redis_01 bin]# kill -9 19458然后看看它对应的7004能不能自动切换成master
[root@redis_01 bin]# ./redis-trib.rb check 192.168.234.130:7004
*** WARNING: 192.168.234.130:7004 claims to be slave of unknown node ID aa7acb8d250665a270e7246778deeeac92c79839.
>>> Performing Cluster Check (using node 192.168.234.130:7004)
S: f3951c292478e384721309bc33436c7ca54d8839 192.168.234.130:7004
slots: (0 slots) slave
replicates aa7acb8d250665a270e7246778deeeac92c79839
M: 5ae3f1af6d4637619ee30c1e3f475dd86b5df271 192.168.234.129:7002
slots:5461-10922 (5462 slots) master
1 additional replica(s)
S: 99e43238b05317623085f22fe707d1314b46e51b 192.168.234.131:7006
slots: (0 slots) slave
replicates 872ea6d136beb824bd397a8a3eeb23287267e06a
S: 27f131740e066a1dd2be3a3b318992551ee6cd77 192.168.234.130:7003
slots: (0 slots) slave
replicates 5ae3f1af6d4637619ee30c1e3f475dd86b5df271
M: 872ea6d136beb824bd397a8a3eeb23287267e06a 192.168.234.131:7005
slots:10923-16383 (5461 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[ERR] Not all 16384 slots are covered by nodes.还没有切换,我们可能需要等会,等集群判断该master挂了才行,等会之后我们再来看一下集群状态
[root@redis_01 bin]# ./redis-trib.rb check 192.168.234.130:7004
>>> Performing Cluster Check (using node 192.168.234.130:7004)
M: f3951c292478e384721309bc33436c7ca54d8839 192.168.234.130:7004
slots:0-5460 (5461 slots) master
0 additional replica(s)
M: 5ae3f1af6d4637619ee30c1e3f475dd86b5df271 192.168.234.129:7002
slots:5461-10922 (5462 slots) master
1 additional replica(s)
S: 99e43238b05317623085f22fe707d1314b46e51b 192.168.234.131:7006
slots: (0 slots) slave
replicates 872ea6d136beb824bd397a8a3eeb23287267e06a
S: 27f131740e066a1dd2be3a3b318992551ee6cd77 192.168.234.130:7003
slots: (0 slots) slave
replicates 5ae3f1af6d4637619ee30c1e3f475dd86b5df271
M: 872ea6d136beb824bd397a8a3eeb23287267e06a 192.168.234.131:7005
slots:10923-16383 (5461 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.下面我们到7004,看是否可以直接读取数据(不用加readonly了)
192.168.234.130:7004> get k2
"v2"再试着把7001给重新启动,恢复过来,自动作为slave挂载到了7004上面去
192.168.234.130:7004> cluster nodes
f3951c292478e384721309bc33436c7ca54d8839 192.168.234.130:7004 myself,master - 0 0 9 connected 0-5460
5ae3f1af6d4637619ee30c1e3f475dd86b5df271 192.168.234.129:7002 master - 0 1568270239552 7 connected 5461-10922
aa7acb8d250665a270e7246778deeeac92c79839 192.168.234.129:7001 slave f3951c292478e384721309bc33436c7ca54d8839 0 1568270241574 9 connected
99e43238b05317623085f22fe707d1314b46e51b 192.168.234.131:7006 slave 872ea6d136beb824bd397a8a3eeb23287267e06a 0 1568270240563 6 connected
27f131740e066a1dd2be3a3b318992551ee6cd77 192.168.234.130:7003 slave 5ae3f1af6d4637619ee30c1e3f475dd86b5df271 0 1568270235510 7 connected
872ea6d136beb824bd397a8a3eeb23287267e06a 192.168.234.131:7005 master - 0 1568270237529 5 connected 10923-16383四、水平扩容
上面我们已经说过了,在redis cluster模式下,不建议做物理的读写分离,我们要通过master的水平扩容,来横向扩展读写吞吐量,还有支撑更多的海量数据。我们假如单机redis,读吞吐是5w/s,写吞吐2w/s,那么如果有5台master,就可以达到读吞吐量25w QPS,写10w QPS了。下面我们就来介绍redis是怎么扩容的。
1、准备工作
我们再在redis_03上创建两个redis实例,分别为7007和7008。可以参考之前的来创建,并启动。
[root@redis_03 init.d]# ps -ef|grep redis
root 29080 1 0 07:50 ? 00:00:52 /usr/local/software/redis/bin/redis-server 192.168.234.131:7005 [cluster]
root 29085 1 0 07:50 ? 00:00:52 /usr/local/software/redis/bin/redis-server 192.168.234.131:7006 [cluster]
root 33631 1 0 15:18 ? 00:00:00 /usr/local/software/redis/bin/redis-server 192.168.234.131:7007 [cluster]
root 33636 1 0 15:18 ? 00:00:00 /usr/local/software/redis/bin/redis-server 192.168.234.131:7008 [cluster]
root 33640 30917 0 15:19 pts/1 00:00:00 grep --color=auto redis这里我们准备把7007作为master,7008作为slave加到之前的cluster中去。我们知道一个cluster的hash slot是固定的(16384个),之前我们有三个master,所以每个差不多分5461个hash slot,现在变成了4个,我们还要把之前的hash slot放到新的master上来,每个放4096个。即要把之前3个master上,总共4096个hashslot迁移到新的第四个master上去。
2、加入新master
我们通过以下命令来进行master的添加
[root@redis_01 bin]# ./redis-trib.rb add-node 192.168.234.131:7007 192.168.234.129:7001
>>> Adding node 192.168.234.131:7007 to cluster 192.168.234.129:7001
>>> Performing Cluster Check (using node 192.168.234.129:7001)
S: aa7acb8d250665a270e7246778deeeac92c79839 192.168.234.129:7001
slots: (0 slots) slave
replicates f3951c292478e384721309bc33436c7ca54d8839
M: f3951c292478e384721309bc33436c7ca54d8839 192.168.234.130:7004
slots:0-5460 (5461 slots) master
1 additional replica(s)
S: 27f131740e066a1dd2be3a3b318992551ee6cd77 192.168.234.130:7003
slots: (0 slots) slave
replicates 5ae3f1af6d4637619ee30c1e3f475dd86b5df271
M: 5ae3f1af6d4637619ee30c1e3f475dd86b5df271 192.168.234.129:7002
slots:5461-10922 (5462 slots) master
1 additional replica(s)
M: 872ea6d136beb824bd397a8a3eeb23287267e06a 192.168.234.131:7005
slots:10923-16383 (5461 slots) master
1 additional replica(s)
S: 99e43238b05317623085f22fe707d1314b46e51b 192.168.234.131:7006
slots: (0 slots) slave
replicates 872ea6d136beb824bd397a8a3eeb23287267e06a
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
>>> Send CLUSTER MEET to node 192.168.234.131:7007 to make it join the cluster.
[OK] New node added correctly.这样就连接到新的redis实例上,现在我们再来确认是否加入了集群
[root@redis_01 bin]# ./redis-trib.rb check 192.168.234.130:7004
>>> Performing Cluster Check (using node 192.168.234.130:7004)
M: f3951c292478e384721309bc33436c7ca54d8839 192.168.234.130:7004
slots:0-5460 (5461 slots) master
1 additional replica(s)
M: 5ae3f1af6d4637619ee30c1e3f475dd86b5df271 192.168.234.129:7002
slots:5461-10922 (5462 slots) master
1 additional replica(s)
S: aa7acb8d250665a270e7246778deeeac92c79839 192.168.234.129:7001
slots: (0 slots) slave
replicates f3951c292478e384721309bc33436c7ca54d8839
M: 8a1484abbd061868040a9dcc8b760220058be9f6 192.168.234.131:7007
slots: (0 slots) master
0 additional replica(s)
S: 99e43238b05317623085f22fe707d1314b46e51b 192.168.234.131:7006
slots: (0 slots) slave
replicates 872ea6d136beb824bd397a8a3eeb23287267e06a
S: 27f131740e066a1dd2be3a3b318992551ee6cd77 192.168.234.130:7003
slots: (0 slots) slave
replicates 5ae3f1af6d4637619ee30c1e3f475dd86b5df271
M: 872ea6d136beb824bd397a8a3eeb23287267e06a 192.168.234.131:7005
slots:10923-16383 (5461 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.已经成功添加。
3、reshard一些数据过去
上面我们发现新的master并没有hash slot,我们可以通过reshard把一部分hash slot移动过来。我们这里移4096个hash slot
[root@redis_01 bin]# redis-trib.rb reshard 192.168.234.129:7001
>>> Performing Cluster Check (using node 192.168.234.129:7001)
......
How many slots do you want to move (from 1 to 16384)? 4096
What is the receiving node ID? 8a1484abbd061868040a9dcc8b760220058be9f6
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1:f3951c292478e384721309bc33436c7ca54d8839
Source node #2:5ae3f1af6d4637619ee30c1e3f475dd86b5df271
Source node #3:872ea6d136beb824bd397a8a3eeb23287267e06a
Source node #4:done
Moving slot 12286 from 872ea6d136beb824bd397a8a3eeb23287267e06a
Moving slot 12287 from 872ea6d136beb824bd397a8a3eeb23287267e06a
Do you want to proceed with the proposed reshard plan (yes/no)? yes
......4、添加node作为slave
以下是添加方式:
./redis-trib.rb add-node --slave --master-id 8a1484abbd061868040a9dcc8b760220058be9f6 192.168.234.131:7008 192.168.234.130:70045、删除node
先用reshard将数据都移除到其他节点,确保node为空之后,才能执行remove操作。总共4096个,我们移到其他三个master去1365 + 1365 + 1366个,和上面操作一样。确保node为空之后,才能执行remove操作
[root@redis_01 bin]# ./redis-trib.rb del-node 192.168.234.131:7007 8a1484abbd061868040a9dcc8b760220058be9f6当你清空了一个master的hashslot时,redis cluster就会自动将其slave挂载到其他master上去。这个时候就只要删除掉master就可以了。
五、Jedis连接集群
1、内部实现原理
我们上面已经知道了,使用redis-cli -c将会自动重定向连接。客户端可能会挑选任意一个redis实例去发送命令,每个redis实例接收到命令,都会计算key对应的hash slot。如果在本地就在本地处理,否则返回moved给客户端,让客户端进行重定向。其中计算hash slot的算法,就是根据key计算CRC16值,然后对16384取模,拿到对应的hash slot(节点间通过gossip协议进行数据交换,就知道每个hash slot在哪个节点上)。
但是基于重定向的客户端,很消耗网络IO,因为大部分情况下,可能都会出现一次请求重定向,才能找到正确的节点。所以大部分的客户端,比如java redis客户端,就是jedis,都是smart的。他们就是在本地缓存维护一份hashslot -> node的映射表,大部分情况下,直接走本地缓存就可以找到hashslot -> node,不需要通过节点进行moved重定向。
1.JedisCluster的工作原理
在JedisCluster初始化的时候,就会随机选择一个node,初始化hashslot -> node映射表,同时为每个节点创建一个JedisPool连接池。每次基于JedisCluster执行操作,首先JedisCluster都会在本地计算key的hashslot,然后在本地映射表找到对应的节点。
如果那个node正好还是持有那个hashslot,那么就ok;如果说进行了reshard这样的操作,可能hashslot已经不在那个node上了,就会返回moved。如果JedisCluter API发现对应的节点返回moved,那么利用该节点的元数据,更新本地的hashslot -> node映射表缓存。
重复上面几个步骤,直到找到对应的节点,如果重试超过5次,那么就报错,JedisClusterMaxRedirectionException。
说明:jedis老版本,可能会出现在集群某个节点故障还没完成自动切换恢复时,频繁更新hash slot,频繁ping节点检查活跃,导致大量网络IO开销。jedis最新版本,对于这些过度的hash slot更新和ping,都进行了优化,避免了类似问题。
2.hashslot迁移和ask重定向
如果hash slot正在迁移,那么会返回ask重定向给jedis。jedis接收到ask重定向之后,会重新定位到目标节点去执行,但是因为ask发生在hash slot迁移过程中,所以JedisCluster API收到ask是不会更新hashslot本地缓存。已经可以确定说,hashslot已经迁移完了,moved是会更新本地hashslot->node映射表缓存的。
2、Java API连接
1.普通连接
创建JedisCluster类连接redis集群。
@Test
public void testJedisCluster() throws Exception {
//创建一连接,JedisCluster对象,在系统中是单例存在
Set nodes = new HashSet<>();
nodes.add(new HostAndPort("127.0.0.1", 7001));
nodes.add(new HostAndPort("127.0.0.1", 7002));
nodes.add(new HostAndPort("127.0.0.1", 7003));
nodes.add(new HostAndPort("127.0.0.1", 7004));
nodes.add(new HostAndPort("127.0.0.1", 7005));
nodes.add(new HostAndPort("127.0.0.1", 7006));
JedisCluster cluster = new JedisCluster(nodes);
//执行JedisCluster对象中的方法,方法和redis一一对应。
cluster.set("cluster-test", "my jedis cluster test");
String result = cluster.get("cluster-test");
System.out.println(result);
//程序结束时需要关闭JedisCluster对象
cluster.close();
} 2.使用spring连接
首先配置applicationContext.xml
测试代码如下:
private ApplicationContext applicationContext;
@Before
public void init() {
applicationContext = new ClassPathXmlApplicationContext(
"classpath:applicationContext.xml");
}
// redis集群
@Test
public void testJedisCluster() {
JedisCluster jedisCluster = (JedisCluster) applicationContext
.getBean("jedisCluster");
jedisCluster.set("name", "zhangsan");
String value = jedisCluster.get("name");
System.out.println(value);
}