前言
上一节内容我们对在32位操作系统下堆栈帧进行了详细的分析,本节我们继续来看看在64位操作系统下对于过程调用在处理机制上是否会有所不同呢?
堆栈帧
我们给出如下示例代码方便对照汇编代码看,和上一节有所不同的是函数调用多了几个参数。
#includeint main() { int a = 1,b = 2, c = 3, d = 4, e = 5,f = 6, g = 7,h = 8; int func(int a, int b,int c,int d,int e,int f ,int g,int h); func(a,b,c,d,e,f,g,h); } int func(int a, int b,int c,int d,int e,int f ,int g,int h) { int i = 30; return a + b + c + d + e + f + g + h + i; }
接下来我们将上述代码转换为intel语法汇编代码,如下:
gcc -S -masm=intel -m64 1.c
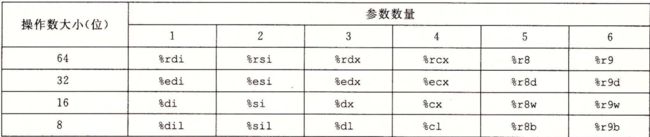
x86仅提供8个通用寄存器(eax,ebx,ecx,edx,ebp,esp,esi,edi),而x64将它们扩展到64位(前缀为“r”而不是“e”),并添加了另外8个(r8,r9,r10,r11,r12,r13,r14,r15)。由于x86的某些寄存器具有特殊的隐含含义,并且并未真正用作通用寄存器(最著名的是ebp和esp),因此有效的增加甚至更大。根据《深入理解计算机系统》这本书介绍,函数的前6个整数或指针参数在寄存器中传递,第一个放在rdi中,第二个放在rsi中,第三个放在rdx中,然后是rcx,r8和r9寄存器中,仅第7个参数及后续参数在堆栈上传递(如下图所示)
关于以上代码就不一一进行图解了,这里我用一张图解进行最终解释,如下:

由如上可知,前6个参数通过寄存器传递,而最后最后2个参数也就是g和h通过堆栈传递,但是除此和x86区别之外,还有个酒红色的区域,该空间不得由信号或中断处理程序修改,因此,函数可以使用此区域存储跨函数调用不需要的临时数据。尤其是,子函数可以在整个堆栈框架中使用此区域,而不是在序言和结语中调整堆栈指针,该区域称为红色区域(简而言之,保留该区域是一种优化)。比如在上述函数中调用子函数并将对应参数传递到子函数中去,此时会将子函数中的局部变量存储在该保留区域,这样一来就无需通过rsp减去堆栈地址为局部变量分配空间,从而达到优化目的。以上对于x86-64的堆栈帧调用约定遵循AMD64 ABI(Application Binary Interface:应用程序二进制接口),但是针对Windows x64位(ABI)定义了x86-64软件调用约定,称为fastcall。接下来我们结合基于Windows x64汇编代码讲讲和上述区别在哪里?我们知道首先为主函数分配一个堆栈帧,然后将对应参数压入栈,如上述a~h参数,对应汇编代码如下:
push rbp mov rbp, rsp sub rsp, 96 call __main //将立即数1写入【rbp-4】 mov DWORD PTR -4[rbp], 1 //将立即数2写入【rbp-8】 mov DWORD PTR -8[rbp], 2 //将立即数3写入【rbp-12】 mov DWORD PTR -12[rbp], 3 //将立即数4写入【rbp-16】 mov DWORD PTR -16[rbp], 4 //将立即数5写入【rbp-20】 mov DWORD PTR -20[rbp], 5 //将立即数6写入【rbp-24】 mov DWORD PTR -24[rbp], 6 //将立即数7写入【rbp-28】 mov DWORD PTR -28[rbp], 7 //将立即数8写入【rbp-32】 mov DWORD PTR -32[rbp], 8
我们知道接下来会调用函数,并将a~h参数进行传入,所以此时会将上述8个参数通过寄存器传递多对应堆栈上,这是x86操作系统上的做法,在windows x64也会是如此吗?如下:
//将【rbp-16】值(即4)写入寄存器r9d mov r9d, DWORD PTR -16[rbp] //将【rbp-12】值(即3)写入寄存器r8d mov r8d, DWORD PTR -12[rbp] //将【rbp-8】值(即2)写入寄存器edx mov edx, DWORD PTR -8[rbp] //将【rbp-4】值(即1)写入寄存器eax mov eax, DWORD PTR -4[rbp]
在windows x64上会将前4个参数存入对应寄存器(我们发现上述却是32位寄存器,这里可能和gcc编译器优化有关,windows x64会将edi和esi进行保留,所以最终参数顺序对应上述表edx、ecx、r8d、r9d,但是我们会发现表中根本就没有eax寄存器,请继续往下看),而剩余的参数则放到堆栈上,如下:
//将【rbp-32】值写入寄存器ecx mov ecx, DWORD PTR -32[rbp] //将寄存器ecx中的值(即8)写入【rsp+56】 mov DWORD PTR 56[rsp], ecx //将【rbp-28】值写入寄存器ecx mov ecx, DWORD PTR -28[rbp] //将寄存器ecx中的值(即7)写入【rsp+48】 mov DWORD PTR 48[rsp], ecx //将【rbp-24】值写入寄存器ecx mov ecx, DWORD PTR -24[rbp] //将寄存器ecx中的值(即6)写入【rsp+40】 mov DWORD PTR 40[rsp], ecx //将【rbp-20】值写入寄存器ecx mov ecx, DWORD PTR -20[rbp] //将寄存器ecx中的值(即5)写入【rsp+32】 mov DWORD PTR 32[rsp], ecx
此时理应进入函数调用,因为上述将立即数1存入的是eax寄存器,所以这里会将eax寄存器的数据传送到ecx(我有点疑惑,对照上述表的话,在windows x64会将esi和edi寄存器保留,第一个参数对应的寄存器应是edx,但是这里却是ecx寄存器,不明白edx和ecx寄存器存储参数的顺序为何颠倒了,若有明白的童鞋,还望指点一二),如下:
//将寄存器eax的数据【rbp-4】送入寄存器ecx mov ecx, eax
接下来开始调用函数,首先将返回地址压入栈,通过call指令如下:
call func
进入函数堆栈帧,首先设置当前函数堆栈帧,接下来则是分配局部变量空间,然后将局部变量入栈,并获取寄存器和堆栈上存储的数据进行计算,整个逻辑如下:
push rbp mov rbp, rsp sub rsp, 16 //将寄存器ecx中的值(即1)写入【rbp+16】 mov DWORD PTR 16[rbp], ecx //将寄存器edx中的值(即2)写入【rbp+24】 mov DWORD PTR 24[rbp], edx //将寄存器edx中的值(即3)写入【rbp+32】 mov DWORD PTR 32[rbp], r8d //将寄存器edx中的值(即4)写入【rbp+40】 mov DWORD PTR 40[rbp], r9d //将立即数写入【rbp-4】 mov DWORD PTR -4[rbp], 30 //将【rbp+16】值(即)写入寄存器edx mov edx, DWORD PTR 16[rbp] //将【rbp+24】值(即2)写入寄存器edx mov eax, DWORD PTR 24[rbp] //edx寄存器存储结果为3 add edx, eax //将【rbp+32】值(即3)写入寄存器eax mov eax, DWORD PTR 32[rbp] //edx寄存器存储结果为6 add edx, eax //将【rbp+40】值(即4)写入寄存器edx mov eax, DWORD PTR 40[rbp] //edx寄存器存储结果为10 add edx, eax //将【rbp+48】值(即5)写入寄存器edx mov eax, DWORD PTR 48[rbp] //edx寄存器存储结果为15 add edx, eax //将【rbp+56】值(即6)写入寄存器edx mov eax, DWORD PTR 56[rbp] //edx寄存器存储结果为21 add edx, eax //将【rbp+64】值(即7)写入寄存器edx mov eax, DWORD PTR 64[rbp] //edx寄存器存储结果为28 add edx, eax //将【rbp+72】值(即8)写入寄存器edx mov eax, DWORD PTR 72[rbp] //edx寄存器存储结果为36 add edx, eax mov eax, DWORD PTR -4[rbp] //eax寄存器存储结果为66 add eax, edx
计算完毕后,则是释放局部变量内存空间,并返回(注:释放局部变量内存空间和x86有所不同),如下:
//清理堆栈帧,释放局部变量空间 add rsp, 16 //弹出当前堆栈帧 pop rbp //弹出返回地址 ret
到这里关于函数堆栈帧已经执行完毕,这里稍微注意下,我们在主函数中调用函数时并未将结果返回,所以在汇编代码中会将已存储结果的寄存器数据置为0,然后同样也是释放主函数局部变量内存空间,如下:
//将eax寄存器中已存储的数据置为0 mov eax, 0 add rsp, 96 pop rbp ret
这里呢,我再一次将整个汇编代码逻辑通过图方式来进行详细解释,如下:
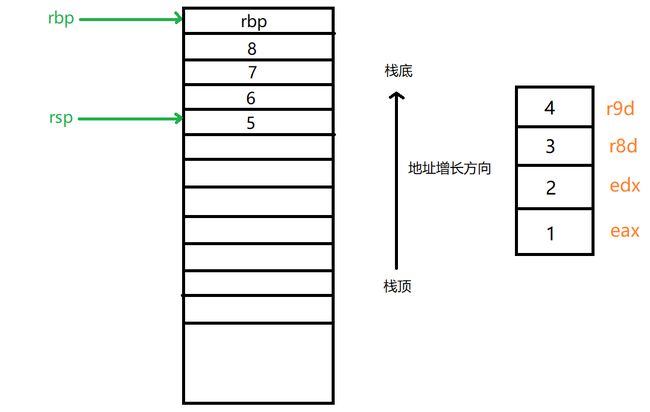
如上为调用函数之前主函数堆栈帧,此时前4个参数在对应寄存器上,而剩余4个参数则是在堆栈上,接下来进入调用函数堆栈帧,如下:
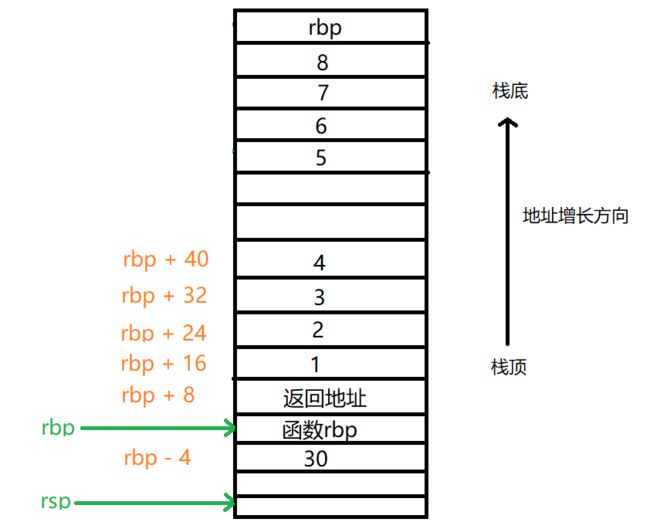
堆栈帧解惑
大多数数据结构将按照其自然对齐方式对齐,这意味着,如果数据结构需要与特定边界对齐,则编译器将根据需要插入填充(加速cpu访问,以空间换时间),针对x64调用约定虽然windows x64有所区别,但是都必须满足相同的堆栈对齐策略,也就是说栈必须与16字节边界完全对齐,如果内存地址可以被16整除,或者最后一位为0(用十六进制表示),换言之通过rsp分配的堆栈必须是16的倍数,比如上述主函数的96个字节,函数调用的16个字节(经查资料,gcc上的32位也是16个字节边界对齐),仔细观察上述图发现,当我们调用函数时(即call指令),此时会将8个字节的返回地址压入栈,这其实是windows x64中的做法,因此,在分配堆栈空间时,所有函数调用必须将堆栈调整为16n + 8形式,所以针对堆栈帧的偏移都为8。
在释放堆栈帧上内存空间时,我们发现是直接通过堆栈针rsp加上在分配时减去的字节数(比如主函数的add rsp,96),在x64处理器模式下,如上述极少情况下会通过rsp来调整参数而是通过rbp来进行偏移,同时x64会分配足够大的堆栈空间来调用最大目标函数(按参数方式使用),而x86模式下,esp的值会随着添加和从堆栈中清除参数而发生变化。
总结
x64处理器模式下需要满足16个字节边界对齐策略,它和x86处理器模式主要有两大区别,一个是x64处理器模式下的参数可通过寄存器来传递参数(这是一大优化,将参数压入堆栈必将导致内存访问),而x86处理器模式下的参数都是存储在堆栈上,另外一个是x64直接使用堆栈针来释放内存空间(即rsp),而x86使用堆栈帧释放空间(即ebp)。AMD x64 ABI和Windows x64 ABI也有几点区别,比如参数传递方式,AMD x64是前6个参数通过寄存器传递,而剩余参数放在堆栈上,而Windows x64则是前4个参数通过寄存器传递,而剩余参数放在堆栈上,AMD x64留有红色的暂存区域,而Windows x64认为该区域是不安全的,所以不存在,同时Windows x64在调用函数时会将8个字节的返回地址压入栈,所以对于参数的访问则需再移动8个字节以满足16个字节边界对齐调用约定,理论上不管是x86还是x64都应该有调用方清理堆栈应而不是被调用方,但是Windows x64模式则是被调用方清理堆栈,还有其他比如对浮点数的存储和处理等等。x64体系结构起源于AMD,被称为AMD64,后来由Intel实施,被称之为IA-32e,然后是EM64T,最后是Intel64。它也被称为x86-64,这两个版本之间有些不兼容,但是大多数代码在两个版本上都可以正常工作,我们更多的称之为x64或x86-64。