第3章 大数据Kylin快速入门
上篇:第2章 Kylin环境搭建
1、需求:实现按照维度(工作地点)统计员工信息
数据准备
在Hive中创建数据,分别创建部门和员工外部表,并向表中导入数据。
(1)原始数据准备到/usr/local/hadoop/module/datas文件目录下
dept.txt
//添加数据
10 ACCOUNTING 1700
20 RESEARCH 1800
30 SALES 1900
40 OPERATIONS 1700
emp.txt
//添加数据
7369 SMITH CLERK 7902 1980-12-17 800.00 20
7499 ALLEN SALESMAN 7698 1981-2-20 1600.00 300.00 30
7521 WARD SALESMAN 7698 1981-2-22 1250.00 500.00 30
7566 JONES MANAGER 7839 1981-4-2 2975.00 20
7654 MARTIN SALESMAN 7698 1981-9-28 1250.00 1400.00 30
7698 BLAKE MANAGER 7839 1981-5-1 2850.00 30
7782 CLARK MANAGER 7839 1981-6-9 2450.00 10
7788 SCOTT ANALYST 7566 1987-4-19 3000.00 20
7839 KING PRESIDENT 1981-11-17 5000.00 10
7844 TURNER SALESMAN 7698 1981-9-8 1500.00 0.00 30
7876 ADAMS CLERK 7788 1987-5-23 1100.00 20
7900 JAMES CLERK 7698 1981-12-3 950.00 30
7902 FORD ANALYST 7566 1981-12-3 3000.00 20
7934 MILLER CLERK 7782 1982-1-23 1300.00 10
(2)建表语句
创建部门表
hive (default)> create external table if not exists default.dept(
> deptno int,
> dname string,
> loc int
> )
> row format delimited fields terminated by '\t';
OK
Time taken: 2.5 seconds
hive (default)>
创建员工表
hive (default)> create external table if not exists default.emp(
> empno int,
> ename string,
> job string,
> mgr int,
> hiredate string,
> sal double,
> comm double,
> deptno int)
> row format delimited fields terminated by '\t';
OK
Time taken: 0.332 seconds
hive (default)>
(3)查看创建的表
hive (default)> show tables;
OK
tab_name
dept
emp
student
Time taken: 0.364 seconds, Fetched: 3 row(s)
(4)向外部表中导入数据
导入数据
//部门表
hive (default)> load data local inpath '/usr/local/hadoop/module/datas/dept.txt' into table default.dept;
Loading data to table default.dept
Table default.dept stats: [numFiles=1, totalSize=69]
OK
Time taken: 1.508 seconds
//员工表
hive (default)> load data local inpath '/usr/local/hadoop/module/datas/dept.txt' into table default.emp;
Loading data to table default.emp
Table default.emp stats: [numFiles=1, totalSize=69]
OK
Time taken: 1.058 seconds
查询结果
hive (default)> select * from emp;
hive (default)> select * from dept;
1、登录系统
创建工程
(1)点击图上所示“+”号
2)填入项目名及描述点击Submit

选择数据源
(1)选择加载数据源方式
(2)输入要作为数据源的表

3)查看数据源
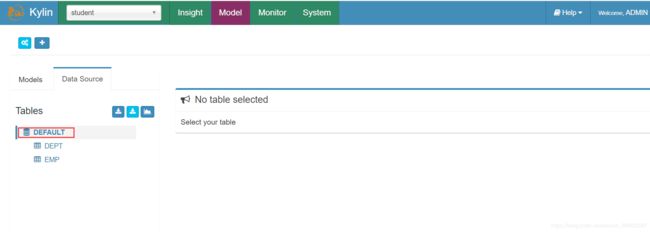
创建Model
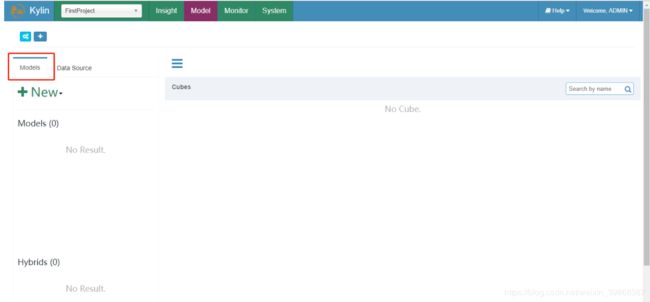
(1)回到Models页面
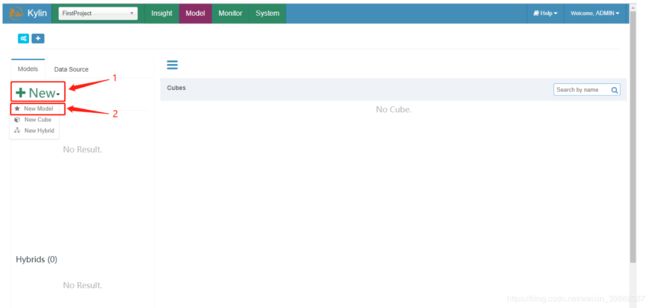
(2)点击New按钮后点击New Model
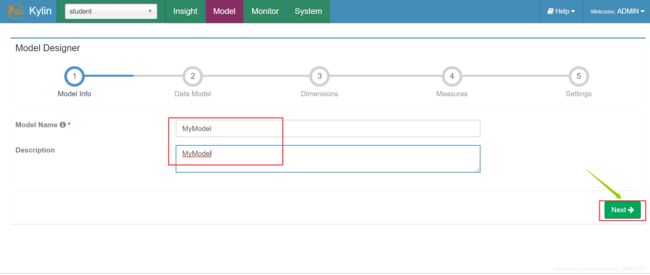
(3)填写Model名称及描述后Next
(4)选择事实表

(5)添加维度表
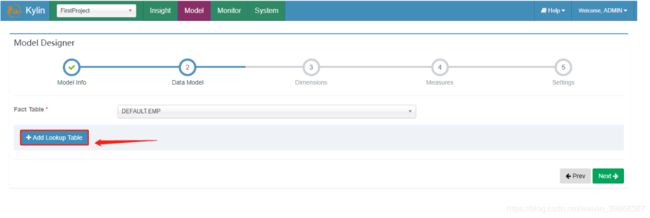

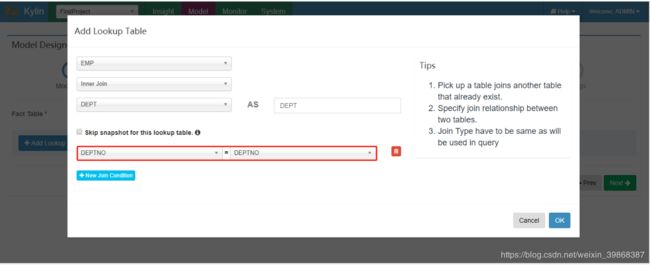
(6)选择添加的维度表及join字段
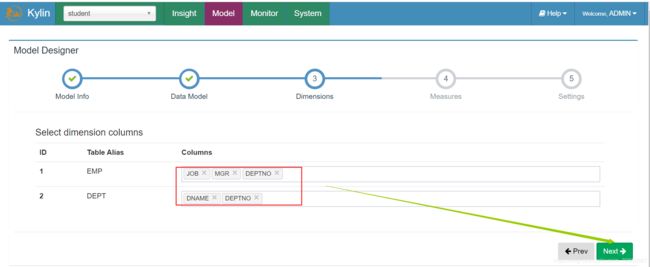
(7)选择维度信息
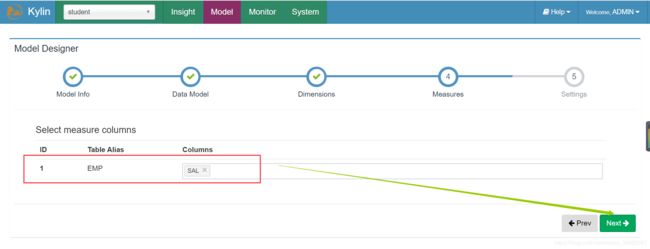
(8)选择度量信息
(9)添加分区信息及过滤条件之后“Save”
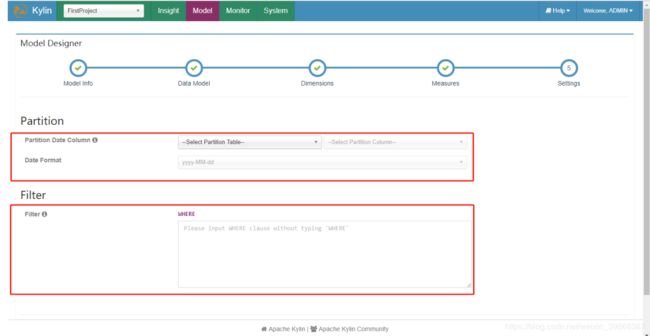
(10)创建Model完成

创建Cube
6)选择添加的维度表及join字段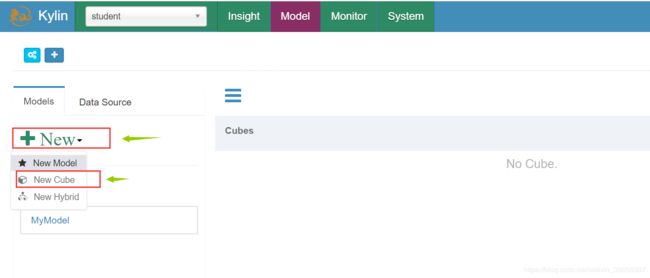
2)选择Model及填写Cube Name

3)添加维度
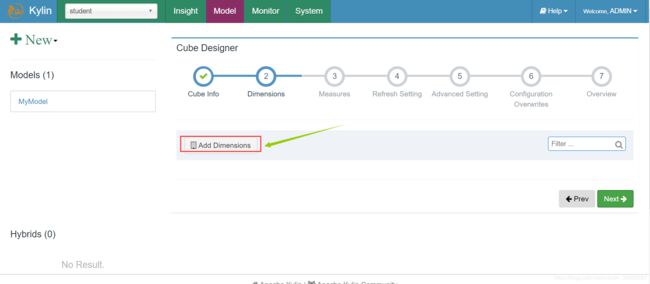

4)添加需要做预计算的内容


5)动态更新相关(默认)

6)高阶模块(默认)

7)需要修改的配置
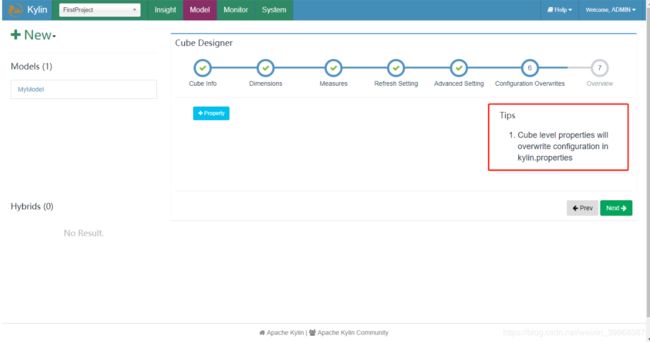
8)Cube信息展示
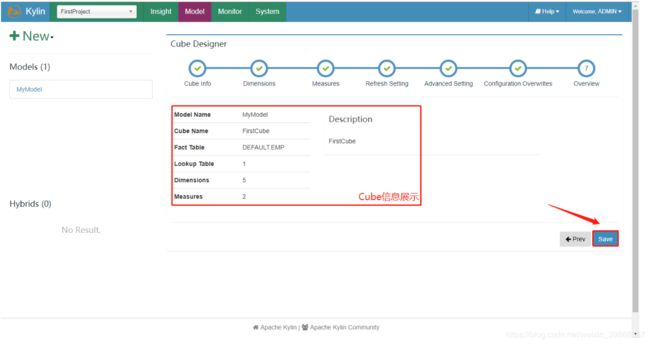
9)Cube配置完成

10)触发预计算

11)查看Build进度

12)构建Cube完成

2、Hive和Kylin性能对比
需求:根据部门名称[dname]统计员工薪资总数[sum(sal)]
Hive查询
hive (default)> select dname,sum(sal) from emp e join dept d on e.deptno = d.deptno group by dname;
Kylin查询
1)进入Insight页面
2)在New Query中输入查询语句并Submit
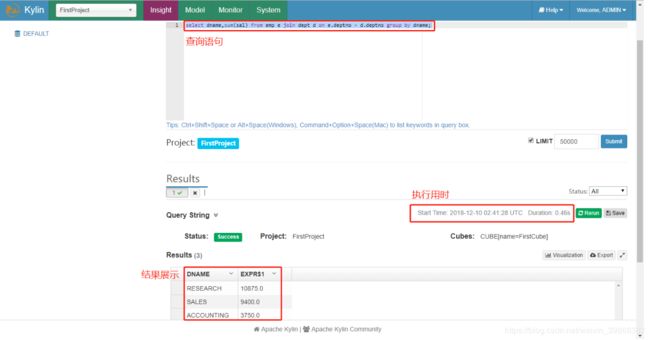
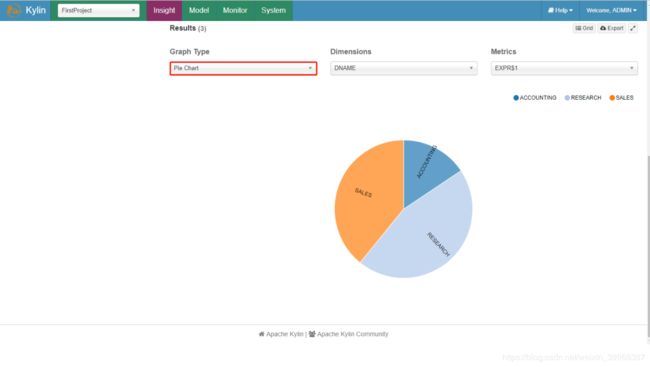
3)数据图表展示及导出
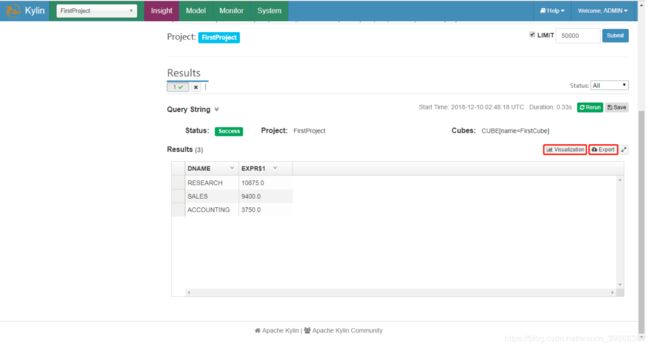
4)图表展示之条形图

4)图表展示之饼图