吴恩达深度学习——超参数调优
文章目录
- 引言
- 参数调优处理
- 为超参数选择合适的范围
- 超参数训练的实践:Pandas VS Caviar
- 归一化网络的激活函数
- 将Batch Norm拟合进神经网络
- Batch Norm为什么奏效
- 测试时的Batch Norm
- 多分类问题-Softmax 回归
- 训练一个Softmax分类器
- 深度学习框架
- TensorFlow
- 参考
引言
本文是吴恩达深度学习第二课:改善深层网络的笔记。这次内容包括深度学习的实用技巧、提高算法运行效率、超参数调优。
第二课有以下三个部分,本文是第二部分。
- 深度学习的实用指南
- 提高算法运行效率
- 超参数调优
参数调优处理
神经网络中有很多超参数,那要如何找到一套好点的参数设置呢。

比如上面的这些参数,如果要按重要程度来排序的话,红框里面的学习率是最重要的;其次是橙框框出的那些参数;再其次是紫框框出的那些;最后是没有框出的那些。
那如果想调试一些参数值,要怎么做呢。

之前常见的做法是在网格中取样本点,比如上面有两个参数,每个样本点代表两个参数的值。然后尝试这25个点,看哪个选择效果最好。
而在深度学习中,我们常用下面的做法。就是随机取点,比如也取25个点。

然后从中选出效果最好的点,这样做的原因是对于你要解决的问题而言,通常都不知道哪个超参数最重要。就像上面看到的一样,一些参数比其他参数更重要。
举个例子,假设超参数一是学习率,超参数二是Adam算法中的 ε \varepsilon ε。
这种情况下,学习率的取值很重要,而 ε \varepsilon ε则相对无关紧要。
如果在网络中取点,

用规整网格的方法试了5个学习率取值,你会发现无论 ε \varepsilon ε取什么,结果基本上都是一样的(在同一个学习率 α \alpha α下)。
因为有25个样本值,但是只尝试了5个 α \alpha α取值。
而随机取值,可以尝试25个独立的 α \alpha α值。

上面只是两个超参数,如果有三个的话,就会是一个立方体。

如果有更多的参数就无法画出来了。
当给超参数取值时,一个惯例是采用由粗到细的策略。

假设有两个参数,并且你发现红线画出的那个取值效果较好,它附近的几个点也不错。接下来要做的是,放到这块小的区域,然后在里面更加密集地取值。

也就是在上面蓝色方格中取更多的点,再搜索哪个点效果最好。
这种从粗到细的搜索经常使用。
但超参数的搜索内容不止这些,下面我来介绍如何为超参数选择合适的范围。
为超参数选择合适的范围
上面我们已经知道了可以随机取值提升搜索效率,但是这里的随机取值并不是在有效值范围内的随机均匀取值,而是选择合适的范围,用来探究这些超参数哪个重要。

假设想知道网络的单元数多少合适,通常要预先设定一个范围,比如50到100,此时可以看到上面从50到100的数轴,我们可以随机在上面取点(这里要取整数),这是一个搜索特定超参数的很直观的方式。
或者我们要选择神经网络的层数 L L L,或许可以定位2到4中的某个值。
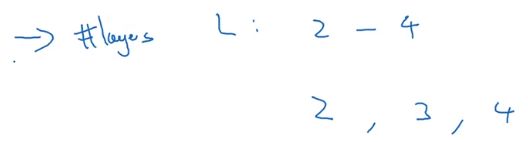
上面都是取整数的例子,那如果取一些小数呢,比如学习率 α \alpha α的取值。
假设我们将学习率最小值设为0.0001,最大值为1。

如果还是用类似前面的方法的话,即从0.0001到1中随机取值,可能90%的结果落到了0.1到1之间。(相当于按0.1将1分成了10份,取到0~0.1的概率只有10%)。
这样看上去不对,此时考虑标尺搜索超参数的方式更合理。

即依次取0.0001、0.001、0.01、0.1、1。然后以幂次-4到0之间随机取值(要有小数),取到的值作为 10 10 10的幂次,就可以得到我们想要的随机值。
在python中可以这么做:
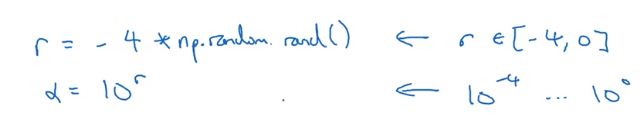
上面 σ \sigma σ取值[-4,0]之间的随机数,然后取 1 0 σ 10^\sigma 10σ就可以得到我们想要的 α \alpha α。
>>> r = -4 * np.random.rand()
>>> r
-2.8480000821641887
>>> 10 ** r
0.001419057253217574
最后另一个棘手的例子是给指数加权平均值的 β \beta β取值。
假设我们认为 β \beta β的取值是0.9到0.999之间的某个值。

解决这个问题的最好方法是改成考虑 1 − β 1 -\beta 1−β的取值,也就是0.1到0.001之间。这样就和我们上面考虑 α \alpha α的问题一样。

一旦我们得到了一个比较不错的值,我们还可以应用由粗到细的方法,在附近更加密集的随机取值。
超参数训练的实践:Pandas VS Caviar
你也许已经找到了一组好的超参数设置,并继续发展算法。但在几个月的过程中,你可以观察到你的数据逐渐发生改变,或许只是数据中心更新了服务器。
正因为有这些原因,可能原来的超参数设定不再好用,所以建议每隔几个月至少重新评估一次设定的超参数。
关于如何搜索超参数的问题,有两种主要的流派。
一种是你像照顾婴儿一样照顾一个模型

可能第一天收敛效果不错,然后第二天你增大了学习率,然后过了几天,你发现学习率太大了,又把学习率改为之前的设置。可以说每天都花时间照顾此模型。
这种情况通常是你机器的资源不够好,计算能力不强,不能再同一时间试验大量模型时才采取的办法。
而另一种方法则显得财大气粗了一点,就是同时试验多种模型。

一般设定了一些超参数,然后让它自己运行,可能经过几周后得到这样的曲线;同时你可能有不同的模型,第二个模型可能会生成紫色曲线:

显然紫色曲线对应的模型更好一点,甚至同时试验了多种模型:

用这种方式可以同时试验许多不同的参数设定,到最后只要选择效果最好的那个即可。
一般第一种方法叫做熊猫方式,因为熊猫的孩子比较少,一次通常只有一个,会花费很多精力抚养熊猫宝宝。
而第二种方式就像鱼子酱一样,一次会产生上亿个鱼卵。

所以这两种方法取决于你的计算机资源。
归一化网络的激活函数
在深度学习兴起后,最重要的一个思想之一就是批归一化(Batch Normalization),批归一化会使参数搜索问题变得很容易,使神经网络对超参数的选择更加稳定,超参数的范围也可以更庞大,工作效果也很好。重要的是会使我们很容易的训练深层网络。
当训练一个模型,比如逻辑回归时,我们知道归一化输入特征可以加速学习过程。

那更深层的网络呢,不仅有输入特征,每层还有激活值。

如果你想训练这些参数,比如 W [ 3 ] , b [ 3 ] W^{[3]},b^{[3]} W[3],b[3],那若能归一化 a [ 2 ] a^{[2]} a[2]岂不是美滋滋。
在逻辑回归中,我们看到如果归一化输入特征 x 1 , x 2 , x 3 x_1,x_2,x_3 x1,x2,x3,会帮助我们更有效的训练 w , b w,b w,b。
现在的问题是,我们能否归一化每层的输出值 a a a。严格来说是归一化 z z z值。
下面看如何实现批归一化。
假设你有一些隐藏单元值,从 z ( 1 ) z^{(1)} z(1)到 z ( m ) z^{(m)} z(m),这些来自隐藏层 l l l,精确的写法应该是 z [ l ] ( i ) z^{[l](i)} z[l](i),这里为了方便简化了 l l l符号。
已知这些值,先要计算平均值,然后计算方差。
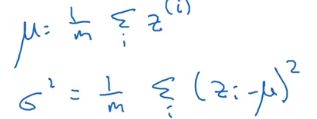
接着归一化每个 z ( i ) z^{(i)} z(i)值。

同样防止分母为零,加上了一个很小的值。
这样就把这些 z z z值归一化为均值为0方差为1的值,但是我们不想让隐藏单元总是含有均值0方差1分布的值,也许有不同的分布更有意义。
因此要计算 z ∼ ( i ) \overset{\sim}{z}^{(i)} z∼(i)
z ∼ ( i ) = γ z n o r m ( i ) + β \overset{\sim}{z}^{(i)} = \gamma z^{(i)}_{norm}+ \beta z∼(i)=γznorm(i)+β
这 γ \gamma γ和 β \beta β是模型的学习参数,不是超参数。
这里 γ \gamma γ和 β \beta β的作用是可以随意设置 z ∼ \overset{\sim}{z} z∼的平均值。
如果 γ = σ 2 + ε \gamma = \sqrt{\sigma^2 + \varepsilon} γ=σ2+ε,而 β = μ \beta = \mu β=μ,
那么 z ∼ ( i ) = z ( i ) \overset{\sim}{z}^{(i)} = z^{(i)} z∼(i)=z(i)
通过给 γ \gamma γ和 β \beta β赋其他值,就可以使你构造含其他平均值和方差的隐藏单元值。
所以现在用 z ∼ ( i ) \overset{\sim}{z}^{(i)} z∼(i)取代 z ( i ) z^{(i)} z(i)来参与神经网络的后续计算。
我们从这小节学到的是,批归一化的作用是它适用的归一化过程不只是输入层,同样适用于神经网络中的深层隐藏神经元。
不过训练输入和这些隐藏单元值的一个区别是,我们不想隐藏单元值必须是均值0方差1的标准正态分布,以便利用激活函数的非线性部分。
所以批归一化的真正作用是使隐藏单元值的均值和方差归一化,使它们有固定的均值和方差。
将Batch Norm拟合进神经网络

假设我们有一个这样的神经网络,对于上面这些记号应该很熟悉了吧。那我们要如何加入Batch Norm(简称BN)呢,

如果没有Batch Norm,下一步就是代入激活函数得到激活值了,但是我们今天要在这一步加入Batch Norm。

如上节所说的,我们加入BN,通过参数 β [ 1 ] , γ [ 1 ] \beta^{[1]},\gamma^{[1]} β[1],γ[1] 计算得到 z ∼ [ 1 ] \overset{\sim}{z}^{[1]} z∼[1]。然后再代入激活函数,得到 a [ 1 ] = g [ 1 ] ( z ∼ [ 1 ] ) a^{[1]} = g^{[1]}(\overset{\sim}{z}^{[1]}) a[1]=g[1](z∼[1])。这样就计算完第一层的结果。

BN发生在 Z Z Z和 a a a的计算过程之间。接下来通过这个 a [ 1 ] a^{[1]} a[1]来计算 z [ 2 ] z^{[2]} z[2],和第一层一样,我们对 z [ 2 ] z^{[2]} z[2]进行BN。
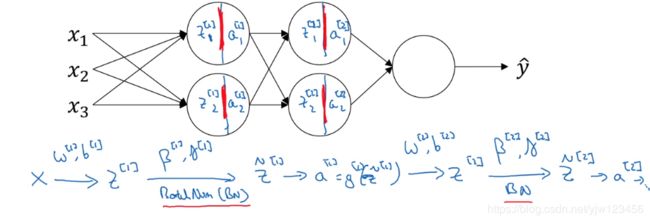
这里要强调的是BN发生在计算 z z z和 a a a之间的。
这里我们(每个隐藏层)引入了两个参数 γ , β \gamma,\beta γ,β,所有现在网络的参数是:
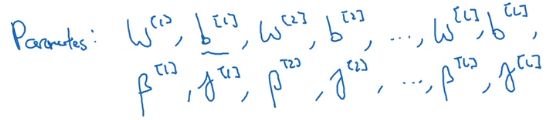
这些参数都可以通过模型自己学习的,

更新的公式和参数 W , b W,b W,b一样,同时也可以应用Adam或RMSprop。
在实践中,BN通常和mini-batch一起使用。

这里要指出的是

在应用BN时,我们要先将 z [ l ] z^{[l]} z[l]归一化,结果为均值0方差1的分布,然后再通过 β \beta β和 γ \gamma γ进行缩放。 这意味着,无论 b [ l ] b^{[l]} b[l]的值是多少,都会将均值设成0的过程中被减掉,因此在这里增加的任何常数的数值都不会发生改变,因为它们会被均值减法所抵消。 也就是使用BN,可以消除 b [ l ] b^{[l]} b[l]这个参数,或者说将它设为零即可。

z [ l ] z^{[l]} z[l]的式子中可以直接去掉 b b b:

变成由 β [ l ] \beta^{[l]} β[l]控制转移或偏置条件。

下面来看下这些参数的维度, z [ l ] z^{[l]} z[l]的维度是 ( n [ l ] , 1 ) (n^{[l]},1) (n[l],1), β [ l ] \beta^{[l]} β[l]和 γ [ l ] \gamma^{[l]} γ[l]的维度也是 ( n [ l ] , 1 ) (n^{[l]},1) (n[l],1)。
因为这是隐藏单元的数量,要与 z [ l ] z^{[l]} z[l]的维度匹配才能对其进行转换。
下面总结一下如何用BN来应用梯度下降法。

Batch Norm为什么奏效
我们知道对输入特征进行归一化可以加速学习,而BN做的和输入特征归一化类似的事情。
BN有用的第二个原因是它可以使权重比你的网络更加深。
下面以一个例子说明。

比如我们有一个网络,假设已经在所有黑猫的图像上训练了数据集,如果现在要把这个网络应用于其他颜色的猫

此时可能你的模型适用的不会很好。

如果黑猫图像中的训练集是上图左边那样分布的,而其他颜色猫训练集分布是右边那样的,那么无法期待在左边训练好的模型能同样在右边也表现的很好。
训练集的数据分布和预测集的数据分布不一致的问题就叫做“covariate shift”问题(或者可以想成输入值改变的问题就是covariate shift)。
如果你已经学习了 x x x到 y y y的映射,此时若 x x x的分布改变了,那么你可能需要重新训练你的模型。
还是以一个例子说明下,考虑下面这个神经网络:

我们从第三个隐藏来看看学习过程,假设已经学习了参数 W [ 3 ] , b [ 3 ] W^{[3]},b^{[3]} W[3],b[3]。从该层来看的话,它从上一层得到一些输入值,接下来它要做些事情希望使输出值 y ^ \hat y y^更接近于真实值 y y y。
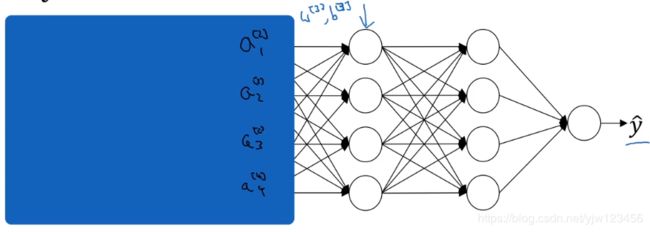
我们先遮住左边部分,从该层来看,它得到了4个输入值,用 a [ 2 ] a^{[2]} a[2]来表示,但这些值也可能是输入特征值。
该层的工作是找到一种方式,使这些值映射到 y ^ \hat y y^。也许现在做得不错。

现在把遮罩打开,这个网络还有参数 W [ 2 ] , b [ 2 ] W^{[2]},b^{[2]} W[2],b[2]和 W [ 1 ] , b [ 1 ] W^{[1]},b^{[1]} W[1],b[1]。如果这些参数发生改变,那么第三层得到的输入也会发生改变。
因此也就有了covariate shift问题,所以BN的作用是减少这些输入值改变的程度。
如果绘制出来的话(这里取两个输入来绘制),BN说的是, z 1 [ 2 ] , z 2 [ 2 ] z^{[2]}_1,z^{[2]}_2 z1[2],z2[2]的值可以改变,
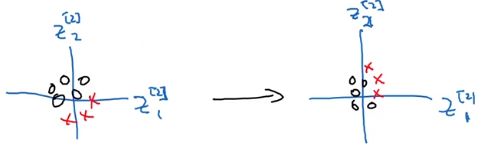
但是无论怎么变化,它们的均值和方差是一样的,由 γ [ 2 ] \gamma^{[2]} γ[2]和 β [ 2 ] \beta^{[2]} β[2]决定均值和方差具体是多少。
这在一定程度上限制了上一层的参数更新能影响数据分布的程度,因此说BN减少了输入值改变的问题。
也可以这样想,BN减弱了前层参数的作用与后层参数的作用之间的联系,它使得网络每层可以自己学习,稍微独立于其他层,这有助于加速整个网络的学习。
BN还有一个作用是有一点正则化效果。
- 每个小批次都被该小批次上计算的均值和方差所缩放(假设每个小批次大小为像64或128这种相对少的大小)。
- 因为没有在整个数据集上计算均值和方差,因此均值和方差会有一点噪音。类似dropout,为每层激活值增加了噪音。
- 类似dropout,BN有一点正则化效果。因为给隐藏单元增加了噪音,迫使后面的隐藏单元不会过分依赖于任何一个隐藏单元。
因为正则化效果比较小,所以还是可以和dropout一起使用。
因为BN一次只能处理一个mini-batch数据,它在mini-batch上计算均值和方差。因为测试时没有mini-batch样本,所以需要做一些不同的东西以确保预测有意义。
测试时的Batch Norm
BN将你的数据以mini-batch的形式逐一处理,但在测试时,你可能需要对每个样本逐一处理。
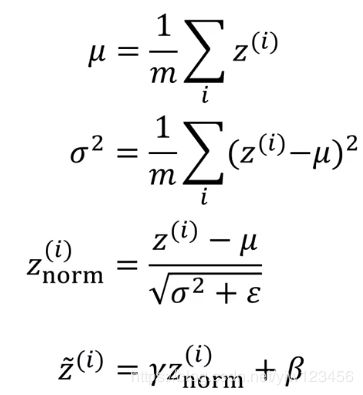
上面是在训练时用到的BN式子,在训练是都是应用于mini-batch的。但在测试时需要用其他方式来得到 μ , σ 2 \mu,\sigma^2 μ,σ2。
典型的做法是用一个指数加权平均来估算 μ , σ 2 \mu,\sigma^2 μ,σ2,这个指数加权平均涵盖了所有mini-batch。
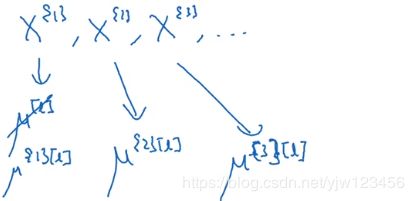
假设在 l l l层得到很多小批次的均值,对这些均值做指数加权平均就得到了这一隐藏层的 μ \mu μ估计,同样地也可以对小批次的 σ 2 \sigma^2 σ2进行估计。
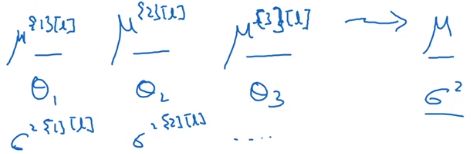
最后在测试时,对应于下面这个等式

只要用估计的 μ , σ 2 \mu,\sigma^2 μ,σ2来计算即可, z z z值是计算出来的, γ , β \gamma,\beta γ,β直接用训练时学到的。
多分类问题-Softmax 回归
我们之前的例子都是二分类问题,今天我们来了解下多分类问题。
有一种逻辑回归的一般形式叫Softmax回归,能预测多个类别的概率。
假设现在不是要识别是否为猫,而是要识别猫(类1)、狗(类2)和鸡(类3),如果不属于任何一类,则分为其他(类0)。

我们用 C C C表示类别的总数,这里有4种。

因此我们可以构建一个神经网络,它的输出层有4个单元。我们想要输出单元的值告诉我们属于这4种类型中每一种的概率有多大。
这里的 y ^ \hat y y^会是一个 ( 4 , 1 ) (4,1) (4,1)维度的向量,并且因为输出的是概率,这4个概率加起来应该等于1。
要做到这一点通常要使用Softmax层。

在计算出最后一层的 Z [ L ] Z^{[L]} Z[L]后,要应用Softmax激活函数。
它的做法是这样的,首先要计算临时变量 t = e z [ L ] t =e ^{z^{[L]}} t=ez[L],它的维度这个例子中也是 ( 4 , 1 ) (4,1) (4,1)。
然后计算 a [ L ] a^{[L]} a[L]为向量 t t t的归一化,使得 a [ L ] a^{[L]} a[L]中元素和为1,它的维度这个例子中也是 ( 4 , 1 ) (4,1) (4,1)。
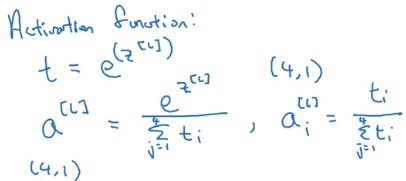
这里取指数 e e e的目的是使得所有的值都为正数,满足了概率为正的定义,同时让每个值除以总和,这样所得的值加起来就为 1 1 1。然后可以根据值的大小得出属于哪个类别的概率最大。
下面以一个例子说明,

这里是类别0的值最大,也就是属于类别0的概率最大。最后用紫线框出来的四个值就是 y ^ \hat y y^的输出。

这里的激活函数是Softmax函数。
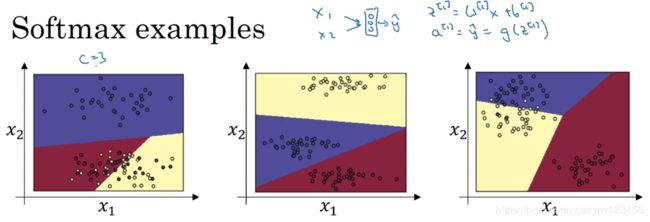
上面是Softmax的三个例子,这里输入为 x 1 , x 2 x_1,x_2 x1,x2,把它们直接接入Softmax层,这里这里有3个类别,就会得到3个输出。上面相当于是一个没有隐藏层的神经网络。
从决策边界可以直觉的感受到,这些决策边界都是线性的。
当然,深度网络会有更多的层和神经元,因为用的激活函数都是非线性的,我们就可以学习到更复杂的非线性决策边界。
训练一个Softmax分类器
本小节我们来看下如何训练一个使用了Softmax层的模型。

先来回顾下上小节的内容,上面是Softmax函数的计算过程,最后由输入值5变成了0.842。这里的softmax说的是和hardmax对应的, hardmax是

hardmax会把最大元素的位置上放1,其他放0。这种比较适用于手写数字识别的one-hot向量。
接下来我们看下如何训练带有softmax输出层的神经网络。
先来看下损失函数的定义,下面是真实标签 y y y和输出标签 y ^ \hat y y^。

从上面的例子看到,这个结果不太好。因为这实际上是一只猫,但是只给了猫20%的概率。
那么如果用损失函数来表示这种差别呢,对应了两个向量的差别第一个想到的应该就是交叉熵了吧。损失函数的定义如下:

这个例子中只有 y 2 = 1 y_2 =1 y2=1,其他都是 0 0 0,因此上面的项可以简化为:

因此

要最小化损失函数,就变成要最小化 − log y ^ 2 -\log \hat y_2 −logy^2,即最大化 y ^ 2 \hat y_2 y^2,由softmax的公式可以值,最大也不会超过 1 1 1。
上面是单个样本的损失函数,那整个训练集的成本函数 J J J要如何计算呢

就是对每个样本的损失函数值取个平均即可。
最后说一下代码实现细节,因为 C = 4 C=4 C=4, y y y和 y ^ \hat y y^都是一个 ( 4 , 1 ) (4,1) (4,1)向量
所以向量化实现的话,对于 m m m个样本, Y Y Y写成:

Y ^ \hat Y Y^也这样表示:

最后看一下有softmax输出层时如何实现梯度下降法。
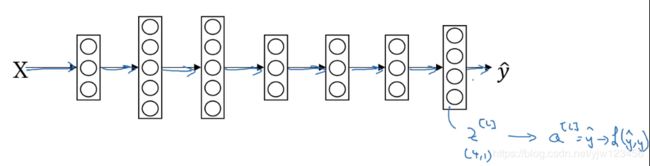
我们上面讲了前向传播,那反向传播呢

关键是 d z dz dz的表达式。

求 d z dz dz表达式可参考:吴恩达深度学习——神经网络基础
下面介绍一下深度学习框架,从这次课程开始就可以不用自己实现深度神经网络了。
深度学习框架

如今又这么的深度学习框架(教程录制的时候可能还没有PyTorch和TensorFlow2)
这里分享一下选择框架的标准:
- 便于编程(包括开发和发布)
- 运行高效
- 完全开放(不仅需要开源,还需要良好的管理)
TensorFlow
(本小节介绍的是TensorFlow1,这还是博主第一次学习TensorFlow1)。
假设现在有一个简单损失函数 J J J需要最小化,

我们来看怎样利用TensorFlow将其最小化。
# 定义参数w
w = tf.Variable(0,dtype=tf.float32)
# 定义损失函数
cost = tf.add(tf.add(w**2,tf.multiply(-10.,w)),25)# w^2 - 10w + 25
# 学习算法 用0.01的学习率来最小化损失函数
train = tf.train.GradientDescentOptimizer(0.01).minimize(cost)
init = tf.global_variables_initializer()
session = tf.Session()
session.run(init)
print(session.run(w)) # 初始为0
session.run(train)
print(session.run(w)) # 运行一次梯度下降后,得到的w是0.099999994

下面我们运行梯度下降1000次迭代。
for i in range(1000):
session.run(train)
print(session.run(w))
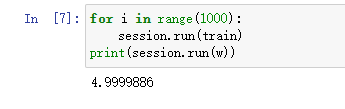
运行1000次梯度下降后,得到的w变成了4.9999,此时已经很接近最优值了。
基本上用tf只要实现前向传播,它能弄明白如何做反向传播和梯度计算。
#cost = tf.add(tf.add(w**2,tf.multiply(-10.,w)),25)# w^2 - 10w + 25
cost = w**2 - 10*w +25
tf还重载了运行符,这样上面的代码可以简写。
上面我们最小化的是固定参数的损失函数。
如果你想要最小化的函数是训练集函数又该怎么办呢,如果把训练数据加入TensorFlow程序呢
# 定义参数w
w = tf.Variable(0,dtype=tf.float32)
# 把x定义成一个3x1的矩阵
x = tf.placeholder(tf.float32,[3,1])
# 定义损失函数
#cost = tf.add(tf.add(w**2,tf.multiply(-10.,w)),25)# w^2 - 10w + 25
# cost = w**2 - 10*w +25
cost = x[0][0]*w**2 + x[1][0]*w + x[2][0]
现在x变成了控制这个二次函数系数的数据,这个placeholder说的是后面会为x提供值。
# 模拟x的数据
cofficients = np.array([[1.],[-10.],[25.]])
# 定义参数w
w = tf.Variable(0,dtype=tf.float32)
# 把x定义成一个3x1的矩阵
x = tf.placeholder(tf.float32,[3,1])
# 定义损失函数
#cost = tf.add(tf.add(w**2,tf.multiply(-10.,w)),25)# w^2 - 10w + 25
# cost = w**2 - 10*w +25
cost = x[0][0]*w**2 + x[1][0]*w + x[2][0]
# 学习算法 用0.01的学习率来最小化损失函数
train = tf.train.GradientDescentOptimizer(0.01).minimize(cost)
init = tf.global_variables_initializer()
session = tf.Session()
session.run(init)
print(session.run(w)) # 初始为0
session.run(train,feed_dict={x:cofficients})
print(session.run(w))
for i in range(1000):
session.run(train,feed_dict={x:cofficients})
print(session.run(w))

session = tf.Session()
session.run(init)
print(session.run(w)) # 初始为0
这三行代码在tf里面是符合表达习惯的,
with tf.Session() as sessioin:
session.run(init)
print(session.run(w)) # 初始为0
有些程序员习惯上面这么写。
这段代码cost = x[0][0]*w**2 + x[1][0]*w + x[2][0]的作用是让tf建立计算图

参考
- 吴恩达深度学习 专项课程