浅谈Java开发规范与开发细节(下)
上篇我们简单分析了一下规范中的命名规范、变量申明的时机、if与大括号的规范、包装类与基础类型常见问题和规范以及项目开发中的空指针等问题,本篇我们继续聊聊几个常见的但是企业开发中比较容易忽略的细节。
不要使用枚举类型作为返回值
还记得阿里巴巴Java开发手册上有很多地方提到了关于枚举的规范:
【参考】枚举类名带上 Enum 后缀,枚举成员名称需要全大写,单词间用下划线隔开。说明:枚举其实就是特殊的类,域成员均为常量,且构造方法被默认强制是私有。
【推荐】如果变量值仅在一个固定范围内变化用 enum 类型来定义。
【强制】二方库里可以定义枚举类型,参数可以使用枚举类型,但是接口返回值不允许使用枚举类型或者包含枚举类型的 POJO 对象。
一个是推荐的参考命名规范,一个是推荐的使用方法,但是我们注意到有一个强制的规范,一般情况下强制的规范都是为了避免企业开发一些细节的风险而标记出来的,可以看到阿里手册中有提到不允许在接口交互过程中使用枚举类型的参数进行传递,那么这是为什么呢?
我们知道,枚举的使用场景一般为在需要一组同类型的固定常量的时候,我们可以使用枚举来作为标记替代,因此枚举类不需要多例存在,保证了单例以后则是可以减少了内存开销。
**并且我们也知道,在编写枚举的时候,如果出现如果被 abstract 或 final 修饰,或者是枚举常量重复,都会立刻被编译器报错。并且在整个枚举类中,除了当前的枚举常量以外,并不存在其他的任何实例。**因为有了这些特性,使得我们在开发过程中,使用常量的时候比较容易。
但是我们深入了解后,**可以知道枚举的clone方法被final修饰,因此enum常量并不会被克隆,并且枚举类禁止通过反射创建实例,保证了绝对的单例,在反序列化的过程中,枚举类不允许出现实例不相同的情况。**而枚举类在使用过程中最重要的两个方法分别是:
1.用来根据枚举名称获取对应枚举常量的 publicstaticT valueOf(String)方法
2.用来获取当前所有的枚举常量的 publicstaticT[]values()方法
3.用来克隆的函数- clone
我们分别根据这几个方法来研究下为什么有枚举的这几个规范,首先我们来看看clone方法的注释:
1. `/**`
2. `* Throws CloneNotSupportedException. This guarantees that enums`
3. `* are never cloned, which is necessary to preserve their "singleton"`
4. `* status.`
5. `*`
6. `* @return (never returns)`
7. `*/`
从注释上我们就能看出来,枚举类型不支持clone方法,如果我们调用clone方法,会抛 CloneNotSupportedException异常,而与之相关的还有反射创建实例的 newInstance方法,我们都知道,如果不调用clone方法,一般可以使用反射,并且setAccessible 为 true 后调用 newInstance方法,即可构建一个新的实例,而我们可以看到此方法的源码:
1. `public T newInstance(Object... initargs)`
2. `throwsInstantiationException, IllegalAccessException,`
3. `IllegalArgumentException, InvocationTargetException`
4. `{`
5. `.........`
6. `//如果当前的类型为枚举类型,那么调用当前方法直接抛异常`
7. `if((clazz.getModifiers() & Modifier.ENUM) != 0)`
8. `thrownewIllegalArgumentException("Cannot reflectively create enum objects");`
10. `.........`
11. `return inst;`
12. `}`
从这我们可以看出,枚举为了**保证不能被克隆,维持单例的状态,禁止了clone和反射创建实例。**那么我们接着来看序列化,由于所有的枚举都是Eunm类的子类及其实例,而Eunm类默认实现了 Serializable和 Comparable接口,所以默认允许进行排序和序列化,而排序的方法 compareTo的实现大概如下:
1. `/**`
2. `* Compares this enum with the specified object for order. Returns a`
3. `* negative integer, zero, or a positive integer as this object is less`
4. `* than, equal to, or greater than the specified object.`
5. `*`
6. `* Enum constants are only comparable to other enum constants of the`
7. `* same enum type. The natural order implemented by this`
8. `* method is the order in which the constants are declared.`
9. `*/`
10. `public final int compareTo(E o) {`
11. `Enum other = (Enum)o;`
12. `Enum self = this;`
13. `if (self.getClass() != other.getClass() && // optimization`
14. `self.getDeclaringClass() != other.getDeclaringClass())`
15. `throw new ClassCastException();`
16. `return self.ordinal - other.ordinal;`
17. `}`
而ordinal则是代表每个枚举常量对应的申明顺序,说明枚举的排序方式默认按照申明的顺序进行排序,那么序列化和反序列化的过程是什么样的呢?我们来编写一个序列化的代码,debug跟代码以后,可以看到最终是调用了 java.lang.Enum#valueOf方法来实现的反序列化的。而序列化后的内容大概如下:
1. `arn_enum.CoinEnum?xr?java.lang.Enum?xpt?PENNYq?t?NICKELq?t?DIMEq~?t?QUARTER`
大概可以看到,序列化的内容主要包含枚举类型和枚举的每个名称,接着我们看看 java.lang.Enum#valueOf方法的源码:
1. `/**`
2. `* Returns the enum constant of the specified enum type with the`
3. `* specified name. The name must match exactly an identifier used`
4. `* to declare an enum constant in this type. (Extraneous whitespace`
5. `* characters are not permitted.)`
6. `*`
7. `* Note that for a particular enum type {@code T}, the`
8. `* implicitly declared {@code public static T valueOf(String)}`
9. `* method on that enum may be used instead of this method to map`
10. `* from a name to the corresponding enum constant. All the`
11. `* constants of an enum type can be obtained by calling the`
12. `* implicit {@code public static T[] values()} method of that`
13. `* type.`
14. `*`
15. `* @param The enum type whose constant is to be returned`
16. `* @param enumType the {@code Class} object of the enum type from which`
17. `* to return a constant`
18. `* @param name the name of the constant to return`
19. `* @return the enum constant of the specified enum type with the`
20. `* specified name`
21. `* @throws IllegalArgumentException if the specified enum type has`
22. `* no constant with the specified name, or the specified`
23. `* class object does not represent an enum type`
24. `* @throws NullPointerException if {@code enumType} or {@code name}`
25. `* is null`
26. `* @since 1.5`
27. `*/`
28. `public static > T valueOf(Class enumType,`
29. `String name) {`
30. `T result = enumType.enumConstantDirectory().get(name);`
31. `if (result != null)`
32. `return result;`
33. `if (name == null)`
34. `throw new NullPointerException("Name is null");`
35. `throw new IllegalArgumentException(`
36. `"No enum constant " + enumType.getCanonicalName() + "." + name);`
37. `}`
从源码和注释中我们都可以看出来,如果此时A服务使用的枚举类为旧版本,只有五个常量,而B服务的枚举中包含了新的常量,这个时候在反序列化的时候,由于name == null,则会直接抛出异常,从这我们也终于看出来,为什么规范中会强制不允许使用枚举类型作为参数进行序列化传递了。
慎用可变参数
在翻阅各大规范手册的时候,我看到阿里手册中有这么一条:
【强制】相同参数类型,相同业务含义,才可以使用 Java 的可变参数,避免使用 Object 。说明:可变参数必须放置在参数列表的最后。(提倡同学们尽量不用可变参数编程)
正例: public ListlistUsers(String type, Long… ids) {…}
吸引了我,因为在以前开发过程中,我就遇到了一个可变参数埋下的坑,接下来我们就来看看可变参数相关的一个坑。
相信很多人都编写过企业里使用的工具类,而我当初在编写一个Boolean类型的工具类的时候,编写了大概如下的两个方法:
1. `private static boolean and(boolean... booleans) {`
2. `for (boolean b : booleans) {`
3. `if (!b) {`
4. `return false;`
5. `}`
6. `}`
7. `return true;`
8. `}`
10. `private static boolean and(Boolean... booleans) {`
11. `for (Boolean b : booleans) {`
12. `if (!b) {`
13. `return false;`
14. `}`
15. `}`
16. `return true;`
17. `}`
这两个方法看起来就是一样的,都是为了传递多个布尔类型的参数进来,判断多个条件连接在一起,是否能成为true的结果,但是当我编写测试的代码的时候,问题出现了:
1. `public static void main(String[] args) {`
2. `boolean result = and(true, true, true);`
3. `System.out.println(result);`
4. `}`
这样的方法会返回什么呢?其实当代码刚刚编写完毕的时候,就会发现编译器已经报错了,会提示:
1. `Ambiguous method call. Both and (boolean...) in BooleanDemo and and (Boolea`
2. `n...) in BooleanDemo match.`
模糊的函数匹配,因为编译器认为有两个方法都完全满足当前的函数,那么为什么会这样的呢?我们知道在Java1.5以后加入了自动拆箱装箱的过程,为了兼容1.5以前的jdk版本,将此过程设置为了三个阶段:

而我们使用的测试方法中,在第一阶段,判断jdk版本,是不是不允许自动装箱拆箱,明显jdk版本大于1.5,允许自动拆箱装箱,因此进入第二阶段,此时判断是否存在更符合的参数方法,比如我们传递了三个布尔类型的参数,但是如果此时有三个布尔参数的方法,则会优先匹配此方法,而不是匹配可变参数的方法,很明显也没有,此时就会进入第三阶段,完成装箱拆箱以后,再去查找匹配的变长参数的方法,这个时候由于完成了拆箱装箱,两个类型会视为一个类型,发现方法上有两个匹配的方法,这时候就会报错了。
那么我们有木有办法处理这个问题呢?毕竟我们熟悉的 org.apache.commons.lang3.BooleanUtils工具类中也有类似的方法,我们都明白,变长参数其实就是会将当前的多个传递的参数装入数组后,再去处理,那么可以在传递的过程中,将所有的参数通过数组包裹,这个时候就不会发生拆箱装箱过程了!例如:
1. `@Test`
2. `public void testAnd_primitive_validInput_2items() {`
3. `assertTrue(`
4. `! BooleanUtils.and(new boolean[] { false, false })`
5. `}`
而参考其他框架源码大神的写法中,也有针对这个的编写的范例:

通过此种方法可以保证如果传入的是基本类型,直接匹配当前方法,如果是包装类型,则在第二阶段以后匹配到当前函数,最终都是调用了BooleanUtils中基本类型的and方法。
List的去重与xxList方法
List作为我们企业开发中最常见的一个集合类,在开发过程中更是经常遇到去重,转换等操作,但是集合类操作的不好很多时候会导致我们的程序性能缓慢或者出现异常的风险,例如阿里手册中提到过:
【 强 制 】ArrayList的subList结果不可强转成 ArrayList,否则会抛出ClassCastException异常,即java.util.RandomAccessSubList cannot be cast to java.util.ArrayList。
【强制】在SubList场景中,高度注意对原集合元素的增加或删除,均会导致子列表的 遍历、增加、删除产生 ConcurrentModificationException 异常。
【强制】使用工具类 Arrays.asList () 把数组转换成集合时,不能使用其修改集合相关的 方法,它的add/remove/clear 方法会抛出 UnsupportedOperationException 异常。
而手册中的这些xxList方法则是我们开发过程中比较常用的,那么为什么阿里手册会有这些规范呢?我们来看看第一个方法 subList,首先我们先看看SubList类和ArrayList类的区别,从类图上我们可以看出来两个类之间并没有继承关系:
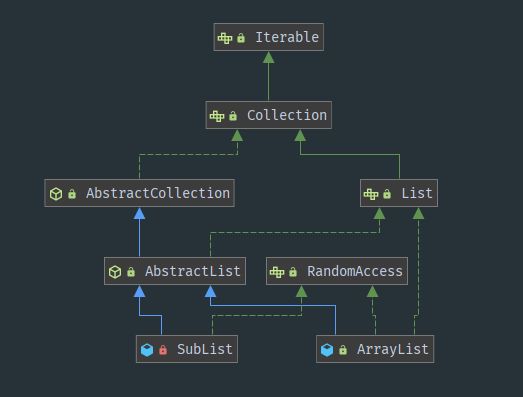
所以手册上不允许使用 subList强转为ArrayList,那么为什么原集合不能进行增删改查操作呢?我们来看看其源码:
1. `/**`
2. `* Returns a view of the portion of this list between the specified`
3. `* {@code fromIndex}, inclusive, and {@code toIndex}, exclusive. (If`
4. `* {@code fromIndex} and {@code toIndex} are equal, the returned list is`
5. `* empty.) The returned list is backed by this list, so non-structural`
6. `* changes in the returned list are reflected in this list, and vice-versa.`
7. `* The returned list supports all of the optional list operations.`
8. `*`
9. `* This method eliminates the need for explicit range operations (of`
10. `* the sort that commonly exist for arrays). Any operation that expects`
11. `* a list can be used as a range operation by passing a subList view`
12. `* instead of a whole list. For example, the following idiom`
13. `* removes a range of elements from a list:`
14. `*
`
15. `* list.subList(from, to).clear();`
16. `*
`
17. `* Similar idioms may be constructed for {@link #indexOf(Object)} and`
18. `* {@link #lastIndexOf(Object)}, and all of the algorithms in the`
19. `* {@link Collections} class can be applied to a subList.`
20. `*`
21. `* The semantics of the list returned by this method become undefined if`
22. `* the backing list (i.e., this list) is structurally modified in`
23. `* any way other than via the returned list. (Structural modifications are`
24. `* those that change the size of this list, or otherwise perturb it in such`
25. `* a fashion that iterations in progress may yield incorrect results.)`
26. `*`
27. `* @throws IndexOutOfBoundsException {@inheritDoc}`
28. `* @throws IllegalArgumentException {@inheritDoc}`
29. `*/`
30. `publicList subList(int fromIndex, int toIndex) {`
31. `subListRangeCheck(fromIndex, toIndex, size);`
32. `returnnewSubList(this, 0, fromIndex, toIndex);`
33. `}`
我们可以看到代码的逻辑只有两步,第一步检查当前的索引和长度是否变化,第二步构建新的SubList出来并且返回。从注释我们也可以了解到,SubList中包含的范围,如果对其进行增删改查操作,都会导致原来的集合发生变化,并且是从当前的index + offSet进行变化。
那么为什么我们这个时候对原来的ArrayList进行增删改查操作的时候会导致SubList集合操作异常呢?我们来看看ArrayList的add方法:
1. `/**`
2. `* Appends the specified element to the end of this list.`
3. `*`
4. `* @param e element to be appended to this list`
5. `* @return true (as specified by {@link Collection#add})`
6. `*/`
7. `publicboolean add(E e) {`
8. `ensureCapacityInternal(size + 1); // Increments modCount!!`
9. `elementData[size++] = e;`
10. `returntrue;`
11. `}`
我们可以看到一点,每次元素新增的时候都会有一个 ensureCapacityInternal(size+1);操作,这个操作会导致modCount长度变化,而modCount则是在SubList的构造中用来记录长度使用的:
1. `SubList(AbstractList parent,`
2. `int offset, int fromIndex, int toIndex) {`
3. `this.parent = parent;`
4. `this.parentOffset = fromIndex;`
5. `this.offset = offset + fromIndex;`
6. `this.size = toIndex - fromIndex;`
7. `this.modCount = ArrayList.this.modCount; // 注意:此处复制了 ArrayList的 modCount`
8. `}`
而SubList的get操作的源码如下:
1. `public E get(int index) {`
2. `rangeCheck(index);`
3. `checkForComodification();`
4. `returnArrayList.this.elementData(offset + index);`
5. `}`
可以看到每次都会去校验一下下标和modCount,我们来看看 checkForComodification方法:
1. `private void checkForComodification() {`
2. `if (ArrayList.this.modCount != this.modCount)`
3. `throw new ConcurrentModificationException();`
4. `}`
可见每次都会检查,如果发现原来集合的长度变化了,就会抛出异常,那么使用SubList的时候为什么要注意原集合是否被更改的原因就在这里了。
那么为什么asList方法的集合不允许使用新增、修改、删除等操作呢?
我们来看下和ArrayList的方法比较:

很明显我们能看出来,asList构建出来的List没有重写 add、 remove 函数,说明该类的集合操作的方法来自父类 AbstactList,我们来看看父类的add方法:
1. `public void add(int index, E element) {`
2. `throw new UnsupportedOperationException();`
3. `}`
从这我们可以看出来,如果我们进行add或者remove操作,会直接抛异常。
集合去重操作
我们再来看一个企业开发中最常见的一个操作,将List集合进行一次去重操作,我本来以为每个人都会选择使用 Set来进行去重,可是当我翻看团队代码的时候发现,居然很多人偷懒选了List自带的 contains方法判断是否存在,然后进行去重操作!我们来看看一般我们使用Set去重的时候编写的代码:
1. `public static Set removeDuplicateBySet(List data) {`
2. `if (CollectionUtils.isEmpty(data)) {`
3. `return new HashSet<>();`
4. `}`
5. `return new HashSet<>(data);`
6. `}`
而HashSet的构造方法如下:
1. `publicHashSet(Collection c) {`
2. `map = newHashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));`
3. `addAll(c);`
4. `}`
主要是创建了一个HashMap以后进行addAll操作,我们来看看addAll方法:
1. `public boolean addAll(Collection c) {`
2. `boolean modified = false;`
3. `for (E e : c)`
4. `if (add(e))`
5. `modified = true;`
6. `return modified;`
7. `}`
从这我们也可以看出来,内部循环调用了add方法进行元素的添加:
1. `public boolean add(E e) {`
2. `return map.put(e, PRESENT)==null;`
3. `}`
而add方法内部依赖了hashMap的put方法,我们都知道hashMap的put方法中的key是唯一的,即天然可以避免重复,我们来看看key的hash是如何计算的:
1. `static final int hash(Object key) {`
2. `int h;`
3. `return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);`
4. `}`
可以看到如果 key 为 null ,哈希值为 0,否则将 key 通过自身 hashCode 函数计算的的哈希值和其右移 16 位进行异或运算得到最终的哈希值,而在最终的 putVal方法中,判断是否存在的逻辑如下:
1. `p.hash == hash && ((k = p.key) == key || (key != null&& key.equals(k)))`
而看到这我们基本已经明了了,set的hash计算还是依靠元素自身的hashCode计算,只要我们需要去重的元素实例遵循了重写hashCode也重写equals的规则,保持一致,直接使用set进行去重还是很简单的。反过来我们再来看看List的 contains方法的实现:
1. `/**`
2. `* Returns true if this list contains the specified element.`
3. `* More formally, returns true if and only if this list contains`
4. `* at least one element e such that`
5. `* (o==null ? e==null : o.equals(e)).`
6. `*`
7. `* @param o element whose presence in this list is to be tested`
8. `* @return true if this list contains the specified element`
9. `*/`
10. `public boolean contains(Object o) {`
11. `return indexOf(o) >= 0;`
12. `}`
可以看到其实是依赖于indexOf方法来判断的:
1. `/**`
2. `* Returns the index of the first occurrence of the specified element`
3. `* in this list, or -1 if this list does not contain the element.`
4. `* More formally, returns the lowest index i such that`
5. `* (o==null ? get(i)==null : o.equals(get(i))),`
6. `* or -1 if there is no such index.`
7. `*/`
8. `public int indexOf(Object o) {`
9. `if (o == null) {`
10. `for (int i = 0; i < size; i++)`
11. `if (elementData[i]==null)`
12. `return i;`
13. `} else {`
14. `for (int i = 0; i < size; i++)`
15. `if (o.equals(elementData[i]))`
16. `return i;`
17. `}`
18. `return -1;`
19. `}`
可以看到indexOf的逻辑为,如果为null,则遍历全部元素判断是否有null,如果不为null也会遍历所有元素的equals方法来判断是否相等,所以时间复杂度接近 O(n^2),而Set的containsKey方法主要依赖于getNode方法:
1. `/**`
2. `* Implements Map.get and related methods.`
3. `*`
4. `* @param hash hash for key`
5. `* @param key the key`
6. `* @return the node, or null if none`
7. `*/`
8. `finalNode getNode(int hash, Object key) {`
9. `Node[] tab; Node first, e; int n; K k;`
10. `if((tab = table) != null&& (n = tab.length) > 0&&`
11. `(first = tab[(n - 1) & hash]) != null) {`
12. `if(first.hash == hash && // always check first node`
13. `((k = first.key) == key || (key != null&& key.equals(k))))`
14. `return first;`
15. `if((e = first.next) != null) {`
16. `if(first instanceofTreeNode)`
17. `return((TreeNode)first).getTreeNode(hash, key);`
18. `do{`
19. `if(e.hash == hash &&`
20. `((k = e.key) == key || (key != null&& key.equals(k))))`
21. `return e;`
22. `} while((e = e.next) != null);`
23. `}`
24. `}`
25. `returnnull;`
26. `}`
可以看到优先通过计算的hash值找到table的第一个元素比较,如果相等直接返回第一个元素,如果是树节点则从树种查找,不是则从链中查找,可以看出来,如果hash冲突不是很严重的话,查找的速度接近 O(n),很明显看出来,如果数量较多的话,List的 contains速度甚至可能差距几千上万倍!
字符串与拼接
在Java核心库中,有三个字符串操作的类,分别为 String、 StringBuffer、 StringBuilder,那么势必会涉及到一个问题,企业开发中经常使用到字符串操作,例如字符串拼接,但是使用的不对会导致出现大量的性能陷阱,那么在什么场合下使用String拼接什么时候使用其他的两个比较好呢?我们先来看一个案例:
1. `public String measureStringBufferApend() {`
2. `StringBuffer buffer = new StringBuffer();`
3. `for (int i = 0; i < 10000; i++) {`
4. `buffer.append("hello");`
5. `}`
6. `return buffer.toString();`
7. `}`
9. `//第二种写法`
10. `public String measureStringBuilderApend() {`
11. `StringBuilder builder = new StringBuilder();`
12. `for (int i = 0; i < 10000; i++) {`
13. `builder.append("hello");`
14. `}`
15. `return builder.toString();`
16. `}`
18. `//直接String拼接`
19. `public String measureStringApend() {`
20. `String targetString = "";`
21. `for (int i = 0; i < 10000; i++) {`
22. `targetString += "hello";`
23. `}`
24. `return targetString;`
25. `}`
使用JMH测试的性能测试结果可以看出来,使用StringBuffer拼接比String += 的方式效率快了200倍,StringBuilder的效率比Stirng += 的效率快了700倍,这是为什么呢?
原来String的 += 操作的时候每一次都需要创建一个新的String对象,然后将两次的内容copy进来,再去销毁原来的String对象,再去创建。。。。而StringBuffer和StringBuilder之所以快,是因为内部预先分配了一部分内存,只有在内存不足的时候,才会去扩展内存,而StringBuffer和StringBuilder的实现几乎一样,唯一的区别就是方法都是 synchronized包装,保证了在并发下的字符串操作的安全性,因此导致性能会有一定幅度的下降。
那么是不是String拼接一定就是最快的呢?
也不一定,例如下面的例子:
1. `public void measureSimpleStringApend() {`
2. `for (int i = 0; i < 10000; i++) {`
3. `String targetString = "Hello, " + "world!";`
4. `}`
5. `}`
6. `//StringBuilder拼接`
7. `public void measureSimpleStringBuilderApend() {`
8. `for (int i = 0; i < 10000; i++) {`
9. `StringBuilder builder = new StringBuilder();`
10. `builder.append("hello, ");`
11. `builder.append("world!");`
12. `}`
13. `}`
相信有经验的就会发现,直接两个字符串片段直接 + 的拼接方式,效率竟然比StringBuilder还要快!这个巨大的差异,主要来自于 Java 编译器和 JVM 对字符串处理的优化。" Hello, " + "world! " 这样的表达式,并没有真正执行字符串连接。
编译器会把它处理成一个连接好的常量字符串"Hello, world!"。这样,也就不存在反复的对象创建和销毁了,常量字符串的连接显示了超高的效率。
但是我们需要注意一点,如果说拼接的两个字符串不是片段常量,而是一个变量,那么效率就会急剧下降,jvm是无法对字符串变量操作进行优化的,例如:
1. `public void measureVariableStringApend() {`
2. `for (int i = 0; i < 10000; i++) {`
3. `String targetString = "Hello, " + getAppendix();`
4. `}`
5. `}`
7. `private String getAppendix() {`
8. `return "World!";`
9. `}`
因此我们可以从中总结出来,使用字符串拼接的几个实践建议:
1.Java 的编译器会优化常量字符串的连接,我们可以放心地把长的字符串换成多行,需要注意的是使用 + 拼接常量,而不是 += ,这两个是不同的概念。
2.带有变量的字符串连接,StringBuilder 效率更高。如果效率敏感的代码,建议使用StringBuilder,并且在日常开发中一般都不建议使用StringBuffer,除非当前的确有严格的并发安全的要求。