ICLR-20 | 旷视研究院提出MABN:解决小批量训练BN不稳定的问题

尽管批归一化技术(BN)在深度学习领域非常成功,但当样本批次非常小时,如何使用BN依然充满挑战。小批次的批统计量非常不稳定,会导致模型训练的收敛速度较慢,推理性能欠佳。旷视研究院提出滑动平均归一化(MABN)来解决小批次训练问题。在小批次情况下,MABN可以完全恢复原始BN在充足批次量下的性能,并与Group Normalization等非线性方法相比,推理效率更高。MABN在多种计算机视觉任务的实验均获得小批次训练,线性推理的SOTA表现。本论文已收录于ICLR 2020。

论文名称:Towards Stablizing Batch Statistics in Backward Propagation of Batch Normalization
论文链接:https://arxiv.org/abs/2001.06838
论文代码:https://github.com/megvii-model/MABN
目录
导语
简介
批归一化中的统计量
批归一化回顾
批统计量的不稳定性
滑动平均批归一化
滑动平均统计量替代批统计量
通过减少统计量稳定归一化
实验
ImageNet图像分类
COCO检测与分割
结论
参考文献
导语
批归一化(Batch Normalization/BN)是当前最为流行的神经网络训练技术之一,其有效性在诸多应用中已广泛证明,成为一些当前最佳的深度模型的必备组件。
尽管BN很成功,当批次(Batch Size)非常小时,BN的使用依然充满挑战。小批次样本的批统计量(Batch Statistics)高度不稳定,导致训练的收敛速度较慢,推理性能欠佳。
为此,很多改良版的归一化方法被提出,它们大概分为两类:
1)一些办法通过纠正批统计量试图还原BN在样本批次量充足时的性能,但是这些办法全都无法完全恢复BN的性能;
2)使用实例级的归一化 (instance level normalization),使模型免受批统计量的影响。这一类方法可在一定程度上恢复BN在小批次上的性能,但是目前看来,实例级的归一化方法不能完全满足工业需求,因为这类方法必须在推理过程(inference)引入额外的非线性运算,大幅增加实际执行开销。
注意,BN会在训练结束时使用整个训练数据的统计量,而不是批统计量。因此,BN是线性算子,可在推理过程中融入卷积层。
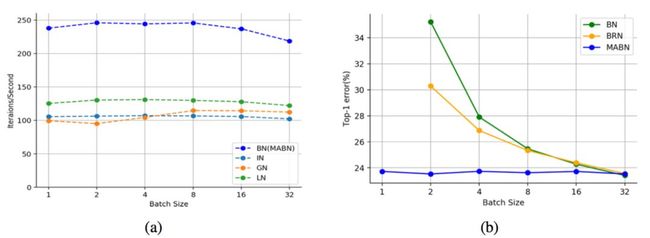
图 1:不同归一化方法在推理阶段的吞吐量对比
由图1(a)可知,在推理阶段使用ResNet-50,实例级归一化的计算时间几乎是BN的两倍。因此,在小批次训练中恢复BN的性能而不在推理过程中引入任何非线性运算是一项艰巨而必要的任务。
简介
本文中,旷视研究院首次揭示了:在归一化层的前向传播(Forward Propagation/FP)和反向传播(Backward Propagation/BP)的过程中,有不只2个,而是4个批统计量的参与。BP涉及的2个额外的批统计量与模型的梯度相关,并在模型梯度的正则化过程中扮演了重要角色。

图 2:训练时来自ResNet-50的BN层(layer.1.0.bn1)的批统计量随着训练次数增加的趋势图
在本文实验中(参见图2),由于批次较小,在BP过程中的梯度相关联的批统计量的方差甚至比广为人知的批统计量(中间过程feature map 的均值,方差)的更大。研究员认为,与梯度相关联的批次统计量的不稳定是BN在小批量训练情形下表现不佳的关键原因之一。
根据以上分析,旷视研究院提出一种全新的归一化方法,称为滑动平均批归一化(Moving Average Batch Normalization/MABN)。MABN可以完全解决小批次问题,且无需在推理过程中引入任何非线性操作。MABN的核心思想是用滑动平均统计量(moving average statistics/MAS)代替批统计量归一化feature map。
本文用不同类型的滑动平均统计量分别代替参与FP和BP的批统计量,并进行理论分析以证明其合理性。但是在实践中发现,直接使用滑动平均统计量代替批统计量无法使模型训练收敛。
本文将其归因于训练不稳定引起的梯度爆炸。为避免训练崩溃,本文通过减少批统计量的数量,中心化卷积核的权重(weight centralization),并采用重归一化策略(Renormalization)来改进原始批归一化的形式。本文还从理论上证明了已修改的归一化形式比原始归一化形式更稳定。
研究员在包括ImageNet和COCO在内的多个计算机视觉公开数据集和任务上,证明了MABN的有效性。所有实验结果表明,小批次(1或2)的MABN可以达到与常规批次的BN相当的性能(见图1(b))。此外,它的推理消耗也与原始BN相同(见图1(a))。
批归一化中的统计量
批归一化回顾
首先,批归一化的(Ioffe & Szegedy, 2015) 的等式:假设BN层的输入是![]() 。在训练过程中,迭代t的已归一化的feature map Y被计算为:
。在训练过程中,迭代t的已归一化的feature map Y被计算为:
![]()
另外,参数对![]() 用于缩放和移动已归一化的值Y:
用于缩放和移动已归一化的值Y:
![]()
缩放和平移部分默认所有的归一化形式添加,为简单起见,以下讨论中将省略。
如Ioffe & Szegedy (2015)所示,在局部梯度 给定的情况下,局部梯度
给定的情况下,局部梯度 可计算为:
可计算为:
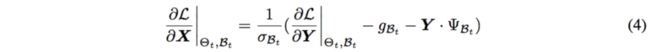
其中 · 指逐元素乘积,![]() 和
和![]() 的计算为:
的计算为:

由等式(5)可知,在BP过程中,![]() 和
和![]() 也属于参与BN反传过程的批统计量。但是以前的研究对此从未有过充分讨论。
也属于参与BN反传过程的批统计量。但是以前的研究对此从未有过充分讨论。
批统计量的不稳定性
根据Ioffe & Szegedy (2015),理想的归一化方法是使用基于整个训练数据集计算的期望和方差进行特征图X的归一化操作:

但是,在优化器是随机梯度下降(Stochastic Gradient Descent/SGD)的情形下使用全数据集的统计量是不切实际的。因此,Ioffe&Szegedy(2015)使用随机梯度训练中的小批次(mini-batch)计算统计量以代替全数据统计量。这种简化使得将均值和方差纳入反传图中成为可能。
批统计量包含总体的均值和方差随着模型更新而变化的信息,以便随着权重更新正确地正则化模型梯度,从而在个体样本变化与总体变化的平衡方面发挥重要作用。因此,精确估算总体统计量(population statistics)十分关键。
众所周知,批统计量是一种蒙特卡洛估计(Monte Carlo Estimatior),它的方差与样本数量成反比,因此,当批次较小时,批统计量的方差会急剧增加。图2给出了在ImageNet训练期间,ResNet-50的一个具体的归一化层的批统计量的变化。
小批次统计量的不稳定性从两个方面降低了模型的性能:
1)小批次统计量的不稳定性使训练不稳定,导致收敛缓慢;
2)小批次统计量的不稳定性会在批统计量和总体统计量之间产生巨大差异。
由于模型训练使用批统计量,评估模型使用总体统计量,因此批统计量和总体统计量之间的差异将导致训练和推理不一致,使模型在评估集上表现欠佳。
滑动平均批归一化
根据上述讨论,恢复BN性能的关键是解决小批次统计量的不稳定性。因此,本文给出了两种解决方案:1)使用滑动平均统计量(MAS)估计总体统计量;2)通过改进归一化形式减少统计量的数量。
滑动平均统计量替代批统计量
当批次较小时,MAS似乎可以替代批统计量来估计总体统计量。本文考虑两类MAS:简单移动平均统计量(Simple Moving Average Statistics/SMAS)和指数移动平均统计量(Exponetial Moving Average Statistics/EMAS)。下述定理1表明,在一般条件下,SMAS和EMAS比批统计量更稳定:

定理1不仅证明MAS相较于批统计量有更小的方差,还说明在当统计量收敛时(式8),如果动量(mometum)α较大,EMAS优于SMAS,方差更低。前传统计量满足收敛性,所以用SMAS代替前传统计量;反传统计量并不一定满足这一条件,所以反传统计量仅用SMAS代替。理论分析之外,实验还有力地表明MAS替代小批次统计量的有效性。
本质上,Batch Renormalization/BRN(Ioffe,2017)就是用EMAS代替前传批统计量。
通过减少统计量的数量稳定归一化
为进一步稳定小批次的训练过程,本文考虑使用![]() 而不是EX和Var(X)归一化特征图X,归一化的等式可修改为:
而不是EX和Var(X)归一化特征图X,归一化的等式可修改为:
![]()
修改的好处显而易见:在FP和BP期间仅剩下两个批统计量,相较于原始归一化形式,改进后的归一化层的不稳定性有所降低。实际上,本文可从定理2给出修改好处的理论证明:

但是,因为消去了中心化feature map的过程,模型性能会有所降低。可以通过增加中心化权重,弥补中心化feature map的缺失。
实验
本节给出了MABN在ImageNet、COCO等颇具挑战性的视觉任务的实验结果。
ImageNet图像分类
本文在包含100个类别的ImageNet数据集上对MABN做了评估,结果如下表所示:

表1:ImageNet分类任务中ResNet-50 top-1错误率对比
其中,梯度批大小是32/GPU,Regular表示归一化批大小是32,而Small表示归一化批大小是2。
本文还做了详尽的消去实验(ablation study),仔细验证了MABN各个组成部分的作用:
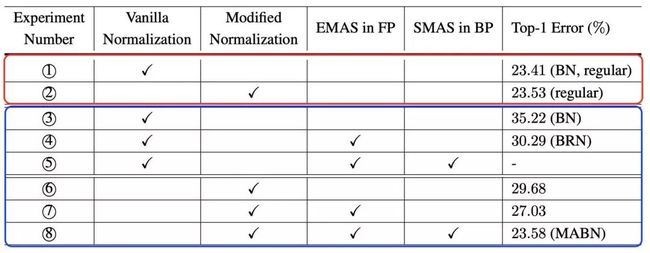
表2: ResNet-50在ImageNet分类任务上消去实验的表现。其中红框里的结果是批次为正常大小时的结果(batch size=32);蓝框里的结果是批次特别小时的结果(batch size=2)
可以看到,仅有MABN在小批次情形下可以达到与正常批次大小的BN的相同水平的表现。
COCO检测与分割
本文按照Mask R-CNN的基本设定在COCO数据集上进行实验,并比较了MABN和它的baseline在不同训练情形下的表现。
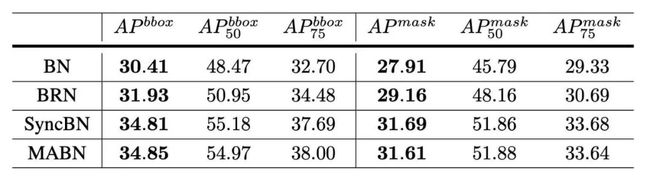
表3: COCO检测和分割任务中Mask-RCNN平均精度的对比,仅有backbone上有归一化层,随机初始化
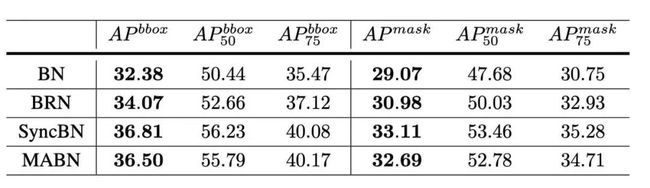
表5:COCO检测和分割任务中Mask-RCNN平均精度的对比,backbone和检测头部均有归一化层,随机初始化

表6: COCO检测和分割任务中Mask-RCNN平均精度的对比,backbone和检测头部均有归一化层,ImageNet预训练模型初始化
以上给出了MABN(批次大小为2)与原始BN(批次大小为2),BRN(批次大小为2)和SyncBN(批次大小为16)的对比结果。可以看出,MABN性能明显优于BN和BRN,并与SyncBN相当。
CityScapes语义分割
本文测试了MABN在语义分割任务上的表现,并与baseline做对比,结果如下:

表8: CityScapes语义分割任务,PSPNET在测试数据集的表现。Backbone是ResNet-101,用ImageNet预训练模型做初始化
MABN的性能依旧远好于BN和BRN,与SyncBN相当。
结论
本文揭示BN的反向传播中隐藏的批处理统计量的的存在,它们对批次大小非常敏感,当批次太小时可能会严重影响模型训练效果。这一发现提供了BN在小批次情况下性能降低的新解释。
据此分析,旷视研究院提出MABN来解决小批次训练问题。在小批次情况下,MABN可以完全恢复原始BN的性能,并且与GN等类似方法相比,推理效率极高。本文在多种计算机视觉任务的实验证明了MABN的卓越性能。
参考文献
Ioffe, S., & Szegedy, C. (2015, June). Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In International Conference on Machine Learning (pp. 448-456).
Ioffe, S. (2017). Batch renormalization: Towards reducing minibatch dependence in batch-normalized models. In Advances in neural information processing systems (pp. 1945-1953).
Wu, Y., & He, K. (2018). Group normalization. In Proceedings of the European Conference on Computer Vision (ECCV) (pp. 3-19).
Qiao, S., Wang, H., Liu, C., Shen, W., & Yuille, A. (2019). Weight standardization. arXiv preprint arXiv:1903.10520.
Ba, J. L., Kiros, J. R., & Hinton, G. E. (2016). Layer normalization. arXiv preprint arXiv:1607.06450.
Ulyanov, D., Vedaldi, A., & Lempitsky, V. (2016). Instance normalization: The missing ingredient for fast stylization. arXiv preprint arXiv:1607.08022.
传送门
欢迎大家关注如下 旷视研究院 官方微信号????
