R TALK | 旷视研究院周而进:距离对齐技术在人脸识别中的应用

「R TALK」是一个深度学习专栏,由北京智源-旷视联合实验室推出,旨在通过一场场精彩纷呈的深度学习演讲,展示旷视研究院的学术分享及阶段性技术成果,抛砖引玉,推陈出新,推动中国乃至全球领域深度学习技术的发展。这是「R Talk」第 10期分享。

目录
人脸识别系统简介
引言
基本工作流程
性能判断指标
如何找到好的人脸表示
人脸识别的实际应用挑战
人脸识别系统简介
引言
今天的分享主题是人脸识别,即如何让机器来识别人的身份,它有两个典型应用:(1)人脸认证,即用算法判别两张图像是否是同一个人;(2)身份查询,即匹配查询的图像与候选解。

这两个问题看似类似,其实不同。人脸认证系统不关心其处理的图像的分身,只关心对比的两张图像是否同一个人,常见应用是手机解锁;身份查询系统需要在一个有身份的查询库中,通过比对,找出输入图像到底属于谁,常见应用是门禁系统。
那么,具体到如何比较两个人脸的相似度,如何去建模、表示人脸信息,其实在计算机视觉中有很多方法。一种通用方式是借助深度学习或手工建模的方式获取表示人脸的特征向量。
对于这些特征向量,我们期望其有一些良好特性,例如在该向量所处的欧氏空间中拥有相似度的概念,如下图表示。我们希望同一个人的照片能够被映射到相近的空间区域中,而不同的人的特征映射的距离则较远。

即对于同一个人的不同照片,我们考察其类内距离是多少;对于不同类的人,考察其类间距离是多少。对于理想的人脸识别系统,我们期望类内的距离尽可能小,类间距离尽可能大。
这也隐含着对于一个好的人脸识别系统所带有的先验判断,希望它找到一个好的变换,这个变换能将输入(像素空间)映射到特征空间上,在这个特征空间,欧式距离的比对其实就等价于对图片进行相似度的比对。因此,人脸识别任务就是去找到这样一个特征变换的方法。
基本工作流程
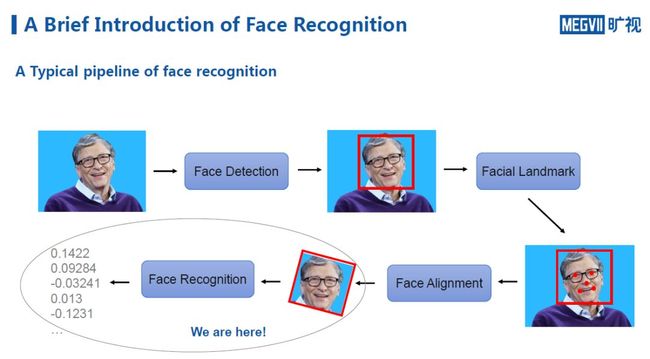
这里以单张图像在典型的人脸识别系统中经过的步骤进行距离说明。
第一步,当系统拿到图像以后,会对图像进行人脸检测,以判断图像中是否存在人脸;如果有,则会同时定位出人脸的位置。
第二步,另一个子系统会对人脸进行关键点定位,即将人脸的眼睛、嘴角等有明确语义特征的信息标定出来。为何要定位,可以将其理解为一种更加精细化的人脸检测,能够更精确地知道人脸的主要部位 分别都在哪些位置。
第三步,进行人脸对齐,即将与统一模板不符的人脸(歪头、过大、过小),放缩到统一模板上,这一步需要关键点定位才能完成。它的好处在于,能够有效降低后一步人脸识别系统处理问题的复杂度。
最后,图像被输入人脸识别系统,通过函数映射,得到人脸特征向量。
上述介绍的是一个最典型的人脸识别系统经历的过程,今天,我们主要讨论这个过程的最后一步,即如何从对齐的人脸图像上学习人脸特征。
性能判断指标
人脸认证场景一般会对两个图像进行相似度对比,如果特征距离小于一个阈值,则认为这两张图像属于同一个人,自然地,评价该系统的性能指标一般可分为:
TAR(True Accept Positive Rate):它表示正确通过率,即对属于同一个身份的图像进行N次比较,能够通过的概率。比如手机解锁人脸,反复进行10次解锁,通过8次,则TAR为80%。
FAR(False Accept Rate):它表示误通过率,即假设有人用错误的图像来攻击该系统,成功的概率。
身份查询系统的性能指标是Top-k Acc:它表示首位命中率或前k位命中率,即当有图像进入库中进行查询时,考察系统计算出的最相似的图像(或前k位相似的图像)是否是该用户当时注册的人脸图像。
这个指标更多考虑的是相似度而非阈值问题,即图像间的阈值可以很低,但是在相对关系中依然能够找到首位命中,那么它也叫首位命中率。
如何找到好的人脸表示
找到一个好的人脸表示,是计算机视觉的经典课题。根据一份调查总结显示,早期,人们通过研究简单的统计量寻找人脸识别方法,当然这样的系统性能较差。
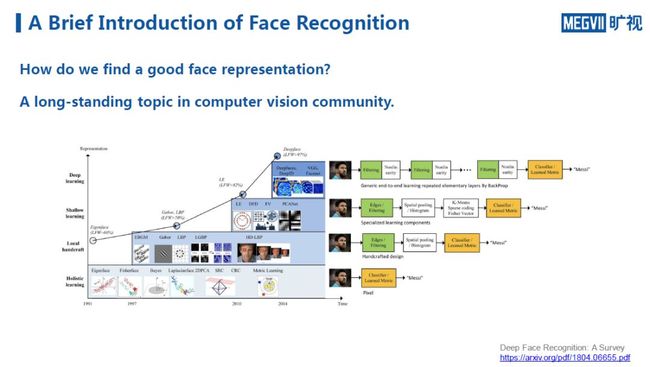
2000年左右,一大批基于手工设计特征的方法出现。相较于早期基于统计量的算法,这些算法虽然极大提升了性能,但也造成了新的问题。它们让整个人脸识别系统的流程变得很长,中间涉及的手工设计环节也非常复杂;另外,同样是由于流程变长,系统的场景限制性也增加,在真实应用场景中往往不够鲁棒。
2013、2014年,在深度学习的推动下,人脸识别系统的性能普遍得到质的飞跃。下面介绍在深度学习发展过程中与人脸识别有关的一些典型工作,从中把握到人脸识别领域在深度学习技术发展以来,研究问题视角的流变过程。
比较早期的工作可以追溯到2014年,一个是Facebook的DeepFace,另一个是香港中文大学的DeepID。二者致力于让系统找到更好地学习人脸特征的方法。
具体而言,研究员假设系统如果能够把足够大的训练集中的人都分辨清楚,那么它也相对能够将这种能力泛化到它没见过的人脸图像上去。经过实验验证,这种方法的确极大提升了当时人脸识别系统的性能。

到了2015年,Google提出 一项新工作——FaceNet,与上述两项工作思路不同,FaceNet更贴近于本次分享一开始介绍的人脸识别思路,即认为同一个人的图像之间的距离近,反之距离远。
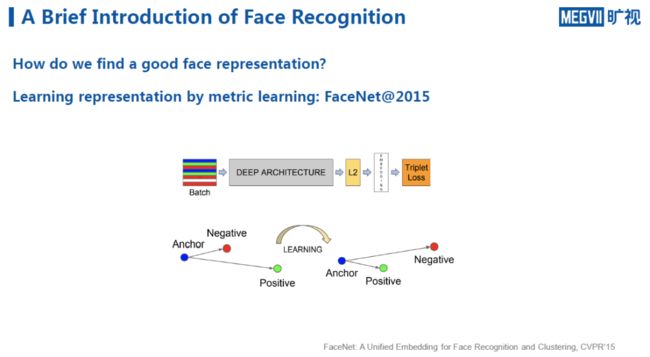
可以看出,这个定义是一个典型的metric learning。Google的FaceNet提出了经典的Triplet Loss,即找到一些三元组,其中有来自同一个人的Anchor与Positive图像,而Negative来自于另一个人。通过让神经网络学习一个表示,使得同一个人距离小于不同人之间的距离。
对比这个方法与第一类方法,可以发现,其核心思想都是希望学习到一个好的人脸表示,但手段有差异。前者希望学习一个全局的分类器,把训练图像中的人彼此分开;而后者则基于local learning,希望每次找到一些三元组,能够在局部将彼此分开。
第二种方法的好处是对于长尾数据应用更加友好。因为现实场景中收集的数据往往在分布上具有长尾效应,即由于很难收集到人们较多的图像,如果这时仅对它们使用简单的多分类网络,则学习效率较低。然而如果以类似第二种方法进行metric learning,通过在上面做难样本的挖掘,找到一些更难的三元组,学习效率相对而言提升更快。
谷歌之后,2017年另一项著名工作问世——SphereFace,它主要用来改进基于多分类的人脸识别系统,其的出发点是,为了让多分类网络分类更准确,希望在训练的时候能够进一步降低类内的距离,从而提高网络的识别性能。如果把分类网络的weight看作是每一个类的类中心,对于分类器而言,给定一个人脸的特征,只要这个中心点和该特征的角度相对来说比离其它中心点更近,那么这个图像就可以实现准确分类。

以上图左边给出的二分类为例,对于第一类图像,它可以弥散于整个半球,只要在左半球,它永远都可以被分类为第一类;在右半球则会被分类为第二类。然而这样不符合人脸识别系统在未见过的数据的泛化性的要求,也就是说,虽然系统在二分类问题上性能合格,但一旦输入其没见过的数据,那彼此之间分类性能就会下降。
因此SphereFace这个工作的核心思想是,在做多分类时增加一个margin,它能够对分类的角度施加一个约束,它不仅要求离平均脸的中心点足够近,同时还需要在离近的某个倍数上,即放在了图中右半球上。同时,光是分到左右半球是不够的,而是能够把特征都聚焦在一个小小的圆锥上。
这个约束条件起到的作用是对于训练数据,我们希望通过softmax loss,能够让神经网络在训练集上学习到更加集中的特征,使得网络的判别能力大幅增强,相应的,在系统未见过的数据上,intra-distance也会有明显下降。
在多个数据集以及真实场景下的验证显示,SphereFace这类基于large margin softmax的改进思想大幅提升了人脸识别系统的性能和鲁棒性。
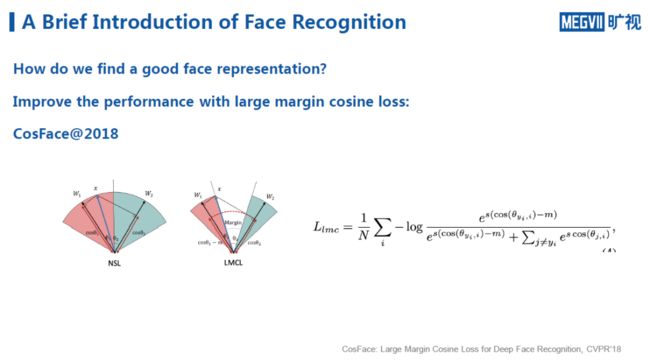
延续这一类思想,近两年来也涌现出许多新方法,如2018年的CosFace。同样,它也是对Large Margin进行提升,但这次改进就不是在角度上,而是对于Cos的值进行约束。从上图中右边的公式可以看出,对于目标类,我们希望其cos的值带上一个惩罚项,即它需要比别人多一个margin,分类才会更准确。
从原理上看,CosFace和SphereFace基本一致,但是从实际效果看,直接在cos值上减去margin的方法会使得训练更加稳定。因为大家知道,如果直接对θ角做限制,由于cos函数是一个周期函数,因此有可能发生减一圈又绕回去的情况,需要额外进行一些非周期的延拓。但如果是从cos值切入则不存在这个问题,所以在实际训练的时候会更佳鲁棒。
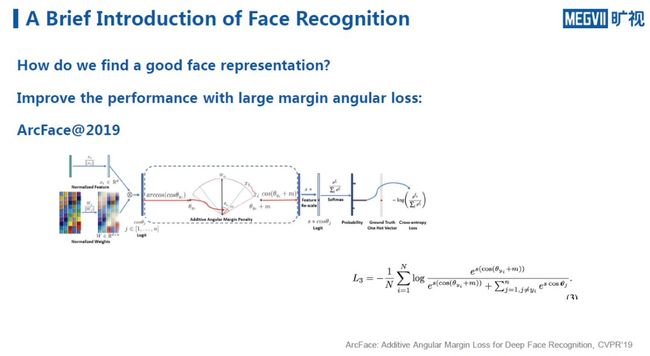
另一项与SphereFace类似的方法是2019年的ArcFace,它与SphereFace不同之处在于,它不对角度做乘法的约束而是做加法的约束,所以从实际的训练效果来看,它训练的难度和loss的稳定性都较SphereFace有明显改善。

上面介绍的方法都是基于分类网络的改进,而基于metric learning的改进最近几年也出现了很多工作。
一个典型的例子是2016年的NPairLoss,其核心思想在于,无论是pairwise loss还是triplet loss,在训练时都是将数据堆叠成mini batch放到神经网络中,那么这时会发现,如果要做N个triplet loss,则需要让神经网络在一个batch中对3N张图像抽取特征,进而只产生N个三元组loss,这样的数据利用效率很低。
换句话说,任意两张图像之间都可以形成一个pair,任意一个三元组之间也可以形成一个三元组loss,所以NPairLoss的动机就在于此,即我们需要更高效地把一个batch中的数据彼此之间更高效地利用起来。
通过这样的改进,一方面可以提升学习效率,一次就可以做N^2对三元组的loss;另一方面,由于三元组的学习方法每次只能看到一个局部(一个三元组),所以梯度噪声很大。因此做NPairLoss的好处在于,对于任意一个Anchor,一个正样本,我们不仅可以看到正样本,还可以看到负样本,这N个负样本的梯度对这个Anchor形成了合力,能够很大程度上降低metric learning这种local learning的学习方法带来的梯度噪声,从而极大加速了学习效率。
所以当前主流基于metric learning做人脸识别的方法基本都会尝试NPairLoss,或基于它的思想变种。
除了在loss上做改进,其他方向上也有很多可改进的地方。这里介绍一下我们团队在2018年ECCV上的一个工作GridFace。它的核心思想是通过纠正面部的几何形变来提升人脸识别的性能。

几何形变的来源很多,比如做表情、摆姿态等等。传统方法希望通过一个仿射变换将人脸进行对齐。但是众所周知,放射变换其实是一个homography,只能对平面内的变换进行纠正。然而由于人脸是3D结构,所以不可能通过一个仿射变换对其进行纠正。
在GridFace这项工作中,我们希望能够对人脸的3D结构进行自动建模。其思想是用大量仿射变换来无监督地学习人脸背后的3D结构,然后将这些小网格都转到它对应的template位置上。因此,只要这些小网格学到了人脸的结构,就能将人脸的姿态纠正过来。
人脸识别的实际应用挑战
1. 当数据成像质量参差不齐,如何能够训练出相对鲁棒,对训练数据依赖性没有那么强的神经网络?
解决这个问题能够极大降低新模组与传感器出现时,算法迁移的成本和复杂度。

2. 如何设计针对低功耗设备的专有神经网络?
这其中就涉及到在低功耗设备上如何设计网络结构、如何训练量化的神经网络、如何降低量化在推理过程中的误差等一系列问题。

3. 数据标注的成本非常高。
这里图中显示的例子是文本标注,人脸标注也是如此,大家可以想一下,作为人类我们在认知熟悉的人脸时精度很高,但是当遭遇陌生人我们往往很难在短时间内分辨其特征。而为了提升算法的性能,往往需要对很多相似的陌生人进行标注,这个过程会消耗大量的成本。

4. 人脸识别系统在实际应用中对误报率的要求相当高
人脸识别系统在实际大规模应用中如果要达到可靠水平,其误报率要求相当严格,以下图为例,假设当前误报率是1e-8,看上去相当低,但在一个有10万人的园区一天就可能发生500次误报。
所以,如果要在这样的规模或者更大规模场景下使用,对于人脸识别系统的误报率要求是指数级上升的,当前在各大AI顶会上纷纷刷榜的模型还远远没有达到这样的诉求,所以人脸识别任务任重而道远。

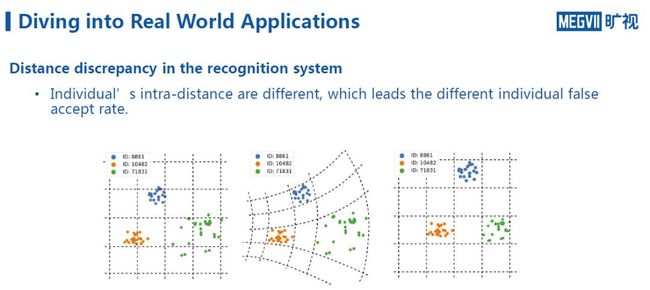
5. 人脸识别系统的距离不对齐问题
这里以一个案例来说明。从下图可知,通过将公开数据集上同样人的不同图片的特征投影到二维平面上,可以发现不同的人在二维平面上特征的类内距离差别非常大。也就是说,系统对有些人的人脸特征学习得很好,所以类间距很小,而对于那些学得不太好的人,类间距就会很大。
这个问题会导致,在实际应用过程中,系统的平均误报率可能在千分之一或万分之一,但是对于不同的人而言,这个误报率可能相差很大。这可能严重影响用户的使用体验。
那么如何纠正这个问题?从目标上看,我们希望神经网络学习到一个好的特征表示,然而它在不同的人身上往往体现出不同的intra-variance,所以人们提出能否有一个纠正网络纠正这个距离。
一个可能的方法是在高维空间中统计这个流形的密度,如果发现人脸特征的分布密度较高,则可以将其拉平,较低则将其聚拢,这样能够得到一个较为一致的特征分布。进而个体的FAR指标的方差就会显著下降。
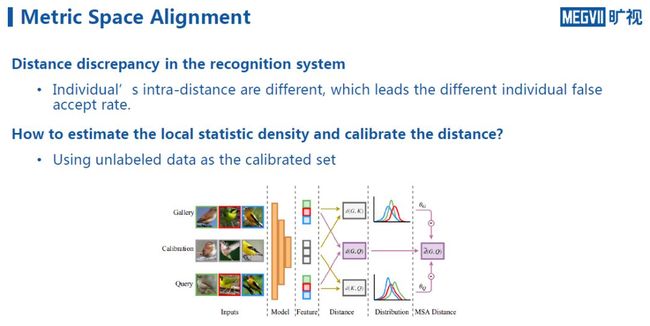
如何来估计这个密度呢?我们发现,在实际过程中有很多未标注的数据,例如门禁系统每天拍到的图像都属于未标注的数据,我们可以用这个数据来估计该应用场景下特征分布的密度情况。具体而言,给定一个未标注的calibration set k_G,假设有一张查询的图像q,则算出来的距离会经过一个修正函数Θ(Θ是关于任意一张查询图像和我们指定的误报率的函数)。
这也就是说,对于任意一张查询图像,我们都对与它有关的距离进行修正,这个修正的幅度,与我们关心的误报率有关。我们希望在修正之后,对于每个用户的误报率都能够达到总体上给出的误报率水平,也即是达到下图公式中写的10^(-t_1) 。

在实际中,我们以数数的方法来估算这个密度,即去统计在整个未标注的calibration set上,有多少图像在距离修正之后可以保证误报率小于既定的阈值。通过这个数字,可以反算出距离修正函数到底应该是多少。计算的方法是,对于任何一张查询的图像,观察在calibration set中有多少张图像和它的距离小于了既定的阈值。
因此,基于上述修正,可以得到如下图的一个单边距离修正函数。即利用未标注的数据,以及它和真实数据是近似同源分布的假设,我们就可以通过将距离修正函数Θ在未标注数据中修正的估计值从真实的距离中减去的方式,来计算库中的图像和查询图像之间的距离。

如果对注册图和查询图像都构建了calibration set,则最终能够对距离修正得到一个双边的修正函数,也即是说,对于任意两张图像,对图像A做一个距离修正,得到关于图像A的函数;对图像B也做一个距离修正,得到关于B的函数,最终可以对两个修正函数通过超参进行组合。
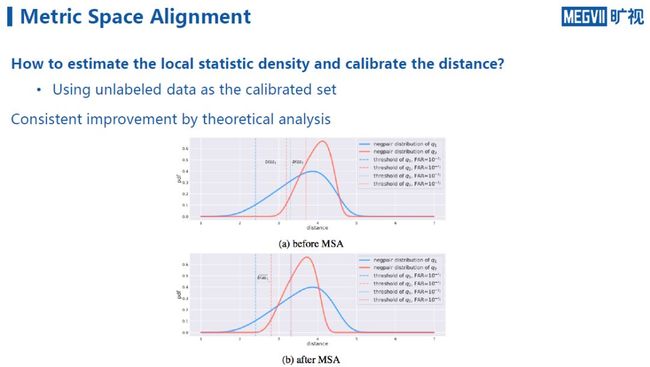
通过分析,可以发现这样的修正效果具有理论保证。具体而言,对任意一个误报率进行距离修正,都可以持续地在其它误报率上得到距离修正的效果,只不过这个效果没有在指定的误报率上准确。也即是说,对于任意一个误报率进行修正,会使得在所有误报率的intra-variance上都得到提升。
至于需要多少图才能满足距离修正的要求,这里可以看一个实验。可以发现,距离修正其实并不需要太多图像,仅仅几百张图像就可以达到很好的性能提升,这一点在实际应用中也得到了验证。

下图是另一项实验,中间的实线代表数据集的平均误报率,横轴是设定的阈值,纵轴代表对应阈值的误报率,阴影部分的面积代表我们统计的个人误报率波动方差,来观察对于数据中每一个人,误报率的波动情况。
以FAR =10^(-2)为平均误报率来看,对于不同的人,误报率可能上涨3倍,也可能提升10倍。而橙色图像代表经过距离修正之后的个人误报率方差,可以发现误报率稳定性得到明显提升,在实际应用中,这可以极大降低不同用户对于产品体验感受的波动。

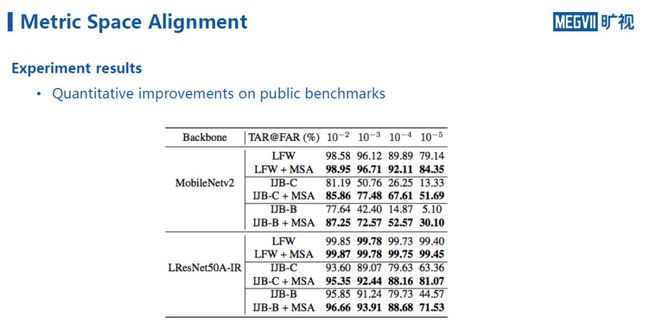
下图展示的是我们团队将该方法在一些公开数据集上进行测试的结果,类似的可以发现,在不同的误报率指标下,随着距离修正模块的增加,系统的整体性能得到显著提升。
总结来看,距离修正操作其实是人脸识别特征出来以后的后处理手段,并不需要改变神经网络本身的结构,也不需要重新训练网络,是一个即插即用的模块,它能针对实际的场景,来纠正误报率,降低方差,进一步也会提升系统整体的准确率。
以上是我的分享,谢谢大家!欢迎大家加入旷视研究院!
入群交流
欢迎加入旷视人脸识别技术交流群

或添加微信号“farman7230”申请入群
视频回顾
---------R Talker 介绍-------
周而进,旷视研究院人脸识别组负责人,毕业于清华大学电子工程系,毕业后他作为第12号员工加入旷视任高级研究员,年仅27岁便担任人脸识别研究组负责人,负责组建并带领旷视人脸识别研究组,在人脸检测、人脸识别、人脸属性等相关技术上推进和成果落地。
往期回顾
R Talk | 旷视首席科学家孙剑:云、端、芯上的视觉计算
R Talk | 旷视研究院目标检测概述:Beyond RetinaNet and Mask R-CNN
R Talk | 旷视研究院姚聪博士:深度学习时代的文字检测与识别技术
R Talk | 旷视南京研究院魏秀参:细粒度图像分析综述
R Talk | 旷视研究院张祥雨:高效轻量级深度模型的研究与实践
R Talk | 旷视研究院张弛:行人重识别及其应用
R Talk | 旷视研究院危夷晨:不确定性学习在视觉识别中的应用
R Talk | 旷视成都研究院负责人刘帅成:图像对齐及其应用
R Talk | 旷视研究院SLAM组负责人刘骁:三维视觉与机器人
传送门
欢迎大家关注如下 旷视研究院 官方微信号????
