CVPR 2020 Oral | 旷视研究院提出注意力归一化AN,优化图像生成任务性能

IEEE国际计算机视觉与模式识别会议 CVPR 2020 (IEEE Conference on Computer Vision and Pattern Recognition) 大会官方论文结果公布,旷视研究院 16 篇论文被收录(其中含 6篇 Oral 论文),研究领域涵盖物体检测与行人再识别(尤其是遮挡场景),人脸识别,文字检测与识别,实时视频感知与推理,小样本学习,迁移学习,3D感知,GAN与图像生成,计算机图形学,语义分割,细粒度图像,对抗样本攻击等众多领域,取得多项领先的技术研究成果,这与已开放/开源的旷视AI生产力平台Brain++密不可分。
本文是旷视CVPR2020论文系列解读第11篇。旷视研究院提出一个在条件图像生成任务上通过归一化建模远距离关系的新方法;它基于实例归一化进行扩展,通过注意力归一化(Attentive Normalization, AN)描述长程依赖。在条件图像生成和图像修复任务上的大量实验证明了该方法在客观和视觉评估上的有效性。本文已入选CVPR2020 Oral论文。

论文名称:Attentive Normalization for Conditional Image Generation
论文链接:https://arxiv.org/abs/2004.03828
目录
导语
简介
注意力归一化(AN)
语义布局学习
软语义布局计算
局部归一化
应用
实验
类条件图像生成
生成式图像修复
结论
参考文献
往期解读
导语
生成对抗网络GAN的出现,让图像生成任务颇受关注。通过学习真实图像数据集,GAN可以生成足够拟真的图像,在诸如图像创作、图像编辑、数据增广等实践领域得到广泛运用。
虽然大多数图像生成器基于全卷积网络,并在结构数据(人脸)和非结构数据(自然场景)的数据上均取得了不错的建模效果,但在面狗、猫等复杂结构物体时,性能欠佳,原因在于卷积神经网络每层是局部有界的(locally bounded),而图像上远距离位置之间关系依赖于不同卷积层之间的马尔科夫建模。
进一步,尽管通过堆叠卷积层可以获得足够大的感受野,但是全卷积生成器仍然弱于建模图像上远距离位置之间的高阶关系。把握这种远距离信息之间的关系非常重要,因为它代表图像语义对应性,即人们熟悉且敏感的内容,比如自然物体的对称性、肢体的对应关系。
对此,自注意力生成对抗网络(Self-Attention GAN)迈出第一步,尝试在类条件(class-conditional)图像生成任务中建模远距离关系。SA-GAN在基于卷积的生成器中引入一个自注意力模块,用于处理图像上远距离信息之间的关系。然而,由于自注意力模块需要计算特征图上每两个点之间的相关关系,因此计算消耗会随着特征图的增大而显著增长。
对此,旷视研究院团队提出一个建模远距离关系的新方法,其效果和计算消耗皆优于现有方法。这一普遍的方法基于实例归一化(Instance Normalization,IN)构建,称之为注意力归一化(Attentive Normalization,AN),其实例效果如图1所示:

图1:GAN使用本文方法,实现条件图像生成效果图,(a)类条件图像生成,(b)图像修复
简介
以往的归一化通过对齐特征图均值和方差的空间维度来实现,这种策略忽略了如下信息,即不同位置在语义上的关联可以通过不同的均值和方差来体现,从而部分破坏了特征图习得的语义信息。
本文根据从特征图预测的语义布局信息,从空间上归一化输入的特征图。这种方法在改善对输入图像上远距离信息间关系学习的同时,还保留了空间语义布局信息。这一方法对语义布局的估计需要依赖两项经验观察:1)一个特征图可视为多个语义实体的组合结果;2)深层的神经网络会提取输入图像的高层语义。
由此,旷视研究院提出语义布局学习模块,它包含两个部分,1)语义布局预测和 2)自采样正则化;前者生成体现语义的mask,对特征图进行切分;后者正则化语义布局预测的优化结果,避免出现平凡解。
基于得到的语义布局,空间信息的传播可通过在每个语义布局区域里独立进行归一化来完成。因为这些有相似语义的特征点的分布在归一化操作后变得紧密了,所以该归一化操作自然会增强其关系,免受空间距离的限制。通过这些点独有的可学习的仿射变换,其共有特点得到了保留甚至是强化。
注意力归一化(AN)
注意力归一化(Attentive Normalization, AN)意在根据特征图的语义,将其切分为不同的区域,然后分别归一化和反归一化同一区域的特征点。这里,第一个任务由语义布局学习(semantic layout learning,SLL)模块完成;第二个由局部归一化操作完成。对于给定的特征图,AN可以学习一个软语义布局,并据其在空间上归一化特征图。
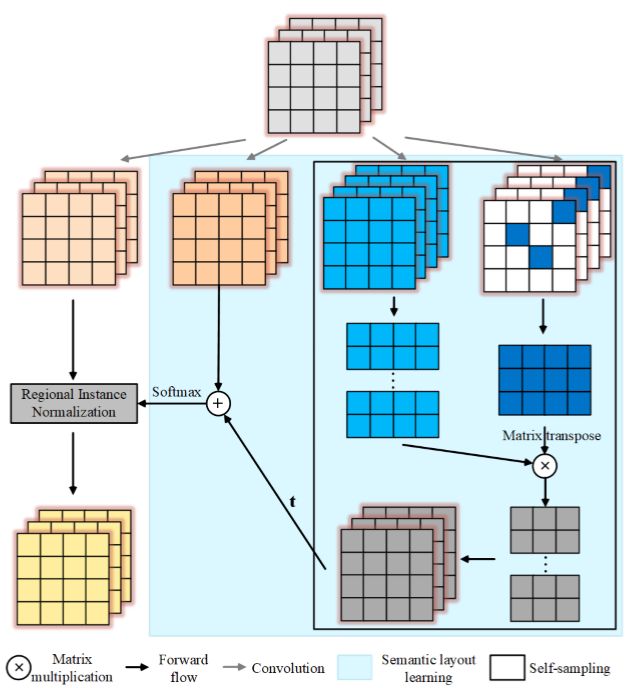
图2:AN示意图
如图2所示,AN由一个语义学习分支和一个自采样分支构成。前者用特定数量的卷积滤波器来捕获不同语义的区域,它基于这样的假设,即该分支里的每个滤波器与某些语义实体相关。
进一步,后者正则化语义实体的学习过程,使得前者不会得到无意义的语义结果,即那些与输入特征不相关的信息。结合两个分支的输出结果,AN会用sofmax计算图像的语义布局,然后在一个仿射变换特征图上对这个语义布局进行局部归一化。
语义布局学习
首先,假设每幅图像由n个语义实体组成,对于图像特征图的每个特征来说,其至少由一个语义实体所决定。这个假设给出了一种表达力很强的表示。因为这些实体可表示不同语境下的同一个已知事物。目前这一假设广泛应用于无监督表示学习。在语义布局的学习中,如何根据特征点与语义实体的关系聚拢特征点非常重要,因为这加大同类的类间相似度(intra-similarity)。
具体而言,研究员首先会给定n个理想的语义实体,然后将其与图像特征点的相关程度定义为其内积,最后,表示这些实体的语义通过反向传播进行学习。基于这些实体的激活状态,可以将输入特征图上的特征点聚合到不同的图像区域上。进一步,为加强这些实体所对应的不同模式,对这些实体进行正交正则化:
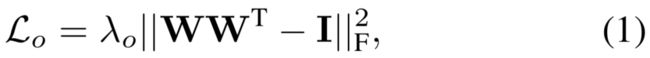
需要强调的是,仅仅依赖这个语义布局学习模块并不能让模型得到有效训练,因为这个模块会倾向于用单个语义实体来聚集所有特征点。具体原因是没有设置策略来对那些与输入特征点关联弱或根本无关联的无意义语义实体进行限制。为此,本文引入自采样分支,以提供一个合理的初始语义布局估计,避免上述问题的发生。
自采样正则化。受到特征量化工作的启发,研究员引入自采样分支来对语义的学习过程进行正则化。自采样分支会从输入特征图上随机选取n个特征点,作为语义实体的可选项。然后,当发现某些实体与输入特征图无关后,这个分支就会激活。它会利用同一张特征图里的相关性来近似估计语义布局。
具体而言,分支会从特征图k(X)上均匀采样n个特征像素,作为初始的语义滤波器。进一步,为了捕获更多明显的语义信息,研究员对k(X)先进行最大池化,然后计算一个激活状态图F:
![]()
软语义布局计算
原始语义激活图由如下公式计算:
![]()
它能够逐渐调整自采样分支带来的影响,使得当训练中出现无意义实体后,自采样分支能够提供有意义的实体可选项。
然后研究员用softmax对S^raw进行了归一化,得到软语义布局:

局部归一化
基于得到的软语义布局,对特征图中长距离关系的建模可以通过局部实例归一化完成。它关注空间信息,将每个独立区域作为一个实例,如图3所示。

图3:局部归一化示例,图中展示的特征图被分割为了4个不同区域(以颜色表示),每个区域的均值和方差根据本区域内的特征点来计算
有同样或类似语义的特征点间的相关性可以通过共享的均值与方差来改进,写为:
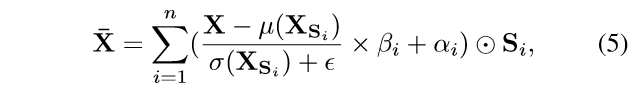
AN关于原始输入特征图的最终输出结果为:
![]()
通过逐渐在局部归一化上施加更多注意力,这种残差学习的方式能够平滑学习曲线。
应用
本文把提出的AN整合进两个GAN框架,分别进行类条件图像生成(class-conditional image generation)和生成式图像修复(generative image inpainting)任务。
类条件图像生成。此任务通过在给定图像上进行训练来学习合成图像分布。通过生成器G,系统会将一个随机采样的噪声z映射到图像x(标签为y)上。
本文中,生成器G由5个残差块组成,在第3个残差块上使用了AN,如图6所示。另外,判别器D由5个残差块组成,在第一个残差块上使用了AN模块。
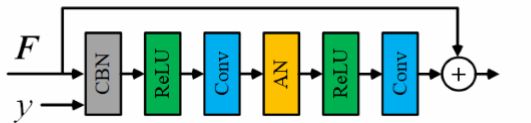
图6:使用了AN的残差块
处于优化的目的,用于训练生成器的对抗损失写为:
![]()
其对应的判别器更新损失为:
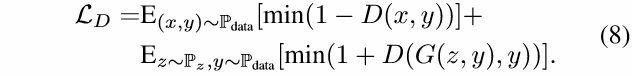
生成式图像修复。这项任务将不完整图像C和一个mask M(像素缺失即值为1,存在像素则值为0)作为输入,然后基于图像展示的语境,预测一个视觉上看起来合理的结果。生成的内容需要与既有内容连贯。在该任务中,通过对已知区域的探究来填补未知区域至关重要。
本文使用了一个两阶段神经网络框架,这两个阶段均利用了编码解码结构。其中AN用于第二阶段,对图像语境信息进行处理以优化最终的预测区域。
在这个任务中,学习的目标包括一个重建项和一个对抗项:
![]()
至于判别器D的训练,研究员使用了WGANGP 损失:
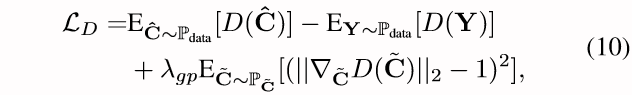
实验
由于类条件图像生成和生成式图像修复都需要生成足够可信的物体与复杂场景,很依赖对图像上远距离信息间关系的建模,因此本文选择这两项任务来评估AN对长距离关系的建模能力。
类条件图像生成
如表1所示,使用了本文AN方法的GAN在FID和Intra FID指标上都超越了SN-GAN与SN-GAN*,说明本文方法生成的图像更加真实且多样,验证了AN在捕捉长距离信息关系上的优越性。与SA-GAN相比,本文方法在三个指标上均低于前者,这说明AN可以实现与SA相媲美的性能。另外,从模型训练收敛的迭代次数来看,本文方法优于现有其他方法。
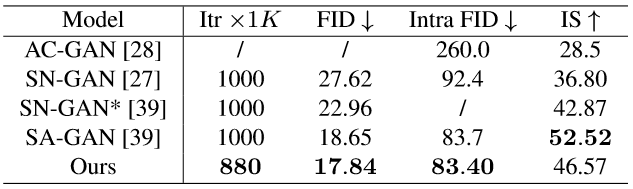
表1:本文方法在ImageNet上进行类条件图像生成任务的量化结果
从表2可知,在对自然场景或纹理(第一大行)以及复杂结构关系(第二大行)的处理上,AN均在Intra FID指标上(越低越好)显著超越了SN-GAN,且极少数任务不及SA-GAN。
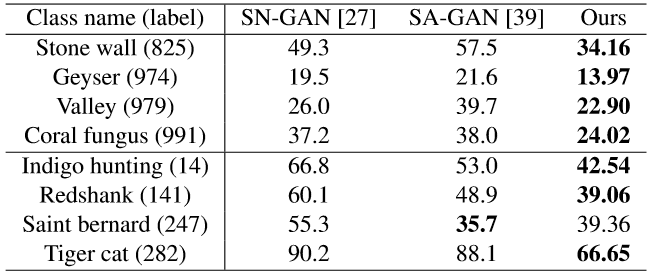
表2:在ImageNet的典型图像类别上的类条件生成Intra FID指标对比
通过图7也可以在视觉上验证这个结果,即AN可以很好处理纹理(Alp、Agaric)和结构敏感(Drilling platform、Schooner)的问题。

图7:由本文方法在ImageNet上随机生成的图像
生成式图像修复
生成式图像修复任务依赖于长距离语义关系以及类条件图像生成。与类条件图像生成的不同之处在于,在生成式图像修复任务中,语境区域的特征是已知的。如图9所示,本文方法得出的结果在视觉效果上会有更多语义布局(墙面与窗户)与纹理细节。量化评估测试(表3)结果也表明,本文方法能够增强信息在跨空间区域上的融合。

图9:Paris Streetview数据集上,生成式图像修复任务对比,(a)输入图像,(b)CA结果,(c)本文结果

表3:Paris Streetview数据集上的量化对比
结论
本文提出一个在条件图像生成任务上通过归一化进行远距离关系建模的新方法,它由语义布局学习与局部归一化两个操作组成,习得的语义布局足以让局部归一化来保留和增强从生成器习得的语义相关性。
入群交流
欢迎加入交流群

或者添加farman7230入群
参考文献
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In CVPR, pages 248–255, 2009.
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, DavidWarde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In NeurIPS, pages 2672–2680, 2014.
Klaus Greff, Sjoerd van Steenkiste, and J¨urgen Schmidhuber. Neural expectation maximization. In NeurIPS, pages 6691– 6701, 2017.
Quoc V. Le, Marc’Aurelio Ranzato, Rajat Monga, Matthieu Devin, Greg Corrado, Kai Chen, Jeffrey Dean, and Andrew Y. Ng. Building high-level features using large scale unsupervised learning. In ICML, 2012.
Taesung Park, Ming-Yu Liu, Ting-Chun Wang, and Jun-Yan Zhu. Semantic image synthesis with spatially-adaptive normalization. In CVPR, pages 2337–2346, 2019.
Deepak Pathak, Philipp Krahenbuhl, Jeff Donahue, Trevor Darrell, and Alexei A Efros. Context encoders: Feature learning by inpainting. In CVPR, pages 2536–2544, 2016.
Han Zhang, Ian Goodfellow, Dimitris Metaxas, and Augustus Odena. Self-attention generative adversarial networks. arXiv preprint arXiv:1805.08318, 2018.
往期解读
CVPR 2020 | 旷视研究院提出PVN3D:基于3D关键点投票网络的单目6DoF位姿估计算法
CVPR 2020 | 旷视研究院提出SAT:优化解决半监督视频物体分割问题
CVPR 2020 | 旷视研究院提出新方法,优化解决遮挡行人重识别问题
CVPR 2020 Oral | 旷视研究院提出Circle Loss,革新深度特征学习范式
CVPR 2020 Oral | 旷视研究院提出双边分支网络BBN:攻坚长尾分布的现实世界任务
CVPR 2020 Oral | 旷视研究院提出针对语义分割的动态路径选择网络
CVPR 2020 | 旷视研究院提出数据不确定性算法 DUL,优化人脸识别性能
CVPR 2020 Oral | 旷视研究院提出密集场景检测新方法:一个候选框,多个预测结果
CVPR 2020 | 旷视研究院提出UnrealText,从3D虚拟世界合成逼真的文字图像
CVPR 2020 Oral | 旷视研究院提出对抗攻击新方法DaST:无需真实数据训练替身模型
传送门
欢迎大家关注如下 旷视研究院 官方微信号????
