Oracle常见索引扫描方式总结
目录
一、简介
二、索引唯一扫描
三、索引范围扫描
四、索引全扫描
五、索引快速全扫描
六、索引跳跃式扫描
七、总结
一、简介
Oracle提供了五种索引扫描类型,根据具体索引类型、数据分布、约束条件以及where限制的不同进行选择:
- 索引唯一扫描(index unique scan)
- 索引范围扫描(index range scan)
- 索引全扫描(index full scan)
- 索引快速扫描(index fast full scan)
- 索引跳跃扫描(index skip scan)
下面我们依次对每种方式进行详细的说明。
二、索引唯一扫描
简称:index unique scan
通过唯一索引查找一个数值经常返回单个ROWID。如果该唯一索引有多个列组成(即组合索引),则至少要有组合索引的引导列参与到该查询中。
如创建一个索引:
create index idx_test on emp(ename, deptno, loc)则下面的语句可以使用该索引:
select ename from emp where ename = ‘JACK’ and deptno = ‘DEV’如果该语句只返回一行,则存取方法称为索引唯一扫描。但是注意下面的语句不会使用该索引,因为where子句种没有引导列。
select ename from emp where deptno = ‘DEV’如果存在UNIQUE 或PRIMARY KEY 约束(它保证了语句只存取单行)的话,Oracle经常实现唯一性扫描,索引唯一性扫描的结果最多返回一条记录。
下面通过一个简单的示例说明索引唯一扫描的场景:
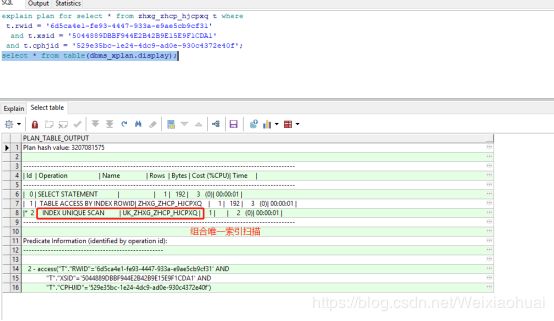
【a】表结构说明:RWID、XSID、CPHJID三个字段组成组合唯一索引

【b】SQL语句 : 使用到了组合索引的三个字段,显然这三个字段组合起来能够唯一确定一条数据,所以使用到了索引唯一扫描。
explain plan for select * from zhxg_zhcp_hjcpxq t where
t.rwid = '6d5ca4e1-fe93-4447-933a-e9ae5cb9cf31'
and t.xsid = '5044889DBBF944E2B42B9E15E9F1CDA1'
and t.cphjid = '529e35bc-1e24-4dc9-ad0e-930c4372e40f';
select * from table(dbms_xplan.display);【c】SQL执行计划
三、索引范围扫描
简称:index range scan
- 当索引是组合索引时,而且select ename from emp where ename = ‘JACK’ and deptno = ‘DEV’语句返回多行数据,虽然该语句还是使用该组合索引进行查询,可此时的存取方法称为索引范围扫描。
- 当扫描对象是唯一性索引时,此时目标sql的where条件一定是范围查询(如between..and...、>、<、<>、>=、<=等);
- 当扫描对象是非唯一性索引时,此时目标sql的where条件没有限制(可以是等值,也可以是范围查询)
下面通过一个简单的示例说明索引范围扫描的场景:
explain plan for select * from vc_zhxg_xsxx_xsjbxx;
select * from table(dbms_xplan.display);【a】表结构说明


【b】执行计划
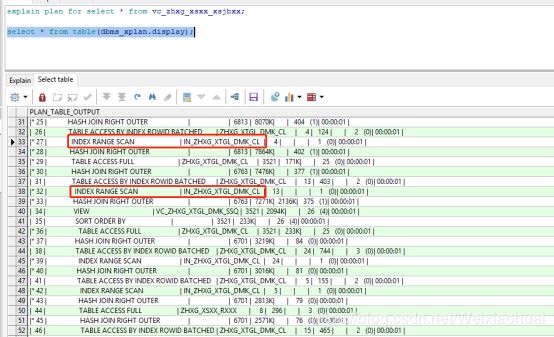
【c】索引范围扫描小总结:
使用index rang scan的3种情况:
- (a) 在唯一索引列上使用了range操作符(> < <> >= <= between);
- (b) 在组合索引上,只使用部分列进行查询,导致查询出多行;
- (c) 对非唯一索引列上进行的任何查询;
四、索引全扫描
简称:index full scan
与全表扫描TABLE ACCESS FULL对应,也有相应的全Oracle索引扫描。在某些情况下,可能进行全Oracle索引扫描而不是范围扫描,需要注意的是全Oracle索引扫描只在CBO模式下才有效。 CBO根据统计数值得知进行全Oracle索引扫描比进行全表扫描更有效时,才进行全Oracle索引扫描,而且此时查询出的数据都必须从索引中可以直接得到。
下面通过一个简单的示例说明索引全扫描的场景:
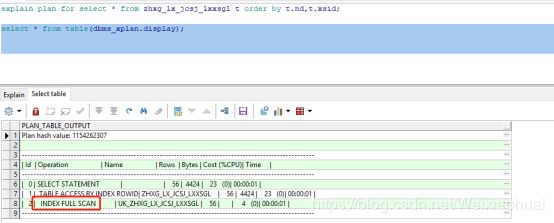
【a】表结构说明:ND、XSID两个字段组成组合唯一索引

【b】SQL语句 : 注意order by t.nd, t.xsid
explain plan for select * from zhxg_lx_jcsj_lxxsgl t order by t.nd,t.xsid;
select * from table(dbms_xplan.display);【c】执行计划
五、索引快速全扫描
简称:index fast full scan
扫描索引中的所有的数据块,与 index full scan很类似,但是一个显著的区别就是它不对查询出的数据进行排序,即数据不是以排序顺序被返回。在这种存取方法中,可以使用多块读功能,也可以使用并行读入,以便获得最大吞吐量与缩短执行时间。
注意点:
索引快速全扫描的执行结果不一定是有序的。这是因为索引快速全扫描时Oracle是根据索引行在磁盘上的物理存储顺序来扫描,而不是根据索引行的逻辑顺序来扫描的,所以扫描结果才不一定有序(对于单个索引叶子块中的索引行而言,其物理存储顺序和逻辑存储顺序一致;但对于物理存储位置相邻的索引叶子块而言,块与块之间索引行的物理存储顺序则不一定在逻辑上有序)。
下面通过一个简单的示例说明索引快速全扫描的场景:
【a】表结构说明:

【b】SQL语句
explain plan for select nd,xsid from zhxg_lx_jcsj_lxxsgl t;
select * from table(dbms_xplan.display);【c】执行计划

六、索引跳跃式扫描
简称:INDEX SKIP SCAN
主要发生在多个列建立的组合索引上,如果SQL中谓词条件只包含索引中的部分列,并且这些列不是建立索引时的第一列时,就可能发生INDEX SKIP SCAN。这里SKIP的意思是因为查询条件没有第一列或前面几列,被忽略了。
下面通过一个简单的示例说明索引跳跃式扫描的场景:
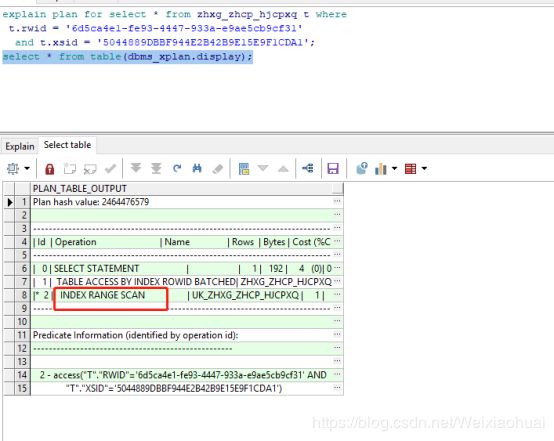
【a】表结构说明:RWID、XSID、CPHJID三个字段组成一个唯一组合索引

【b】SQL语句:使用到了索引列的第一列RWID和第二列XSID
explain plan for select * from zhxg_zhcp_hjcpxq t where
t.rwid = '6d5ca4e1-fe93-4447-933a-e9ae5cb9cf31'
and t.xsid = '5044889DBBF944E2B42B9E15E9F1CDA1';
select * from table(dbms_xplan.display);【c】执行计划:很显然,肯定走索引,而且是索引范围扫描
观察下面的SQL,使用到了RWID、XSID、CPHJID三个索引,显然三者组合唯一,使用到唯一索引扫描。
explain plan for select * from zhxg_zhcp_hjcpxq t where
t.rwid = '6d5ca4e1-fe93-4447-933a-e9ae5cb9cf31'
and t.xsid = '5044889DBBF944E2B42B9E15E9F1CDA1'
and t.cphjid = '529e35bc-1e24-4dc9-ad0e-930c4372e40f';
select * from table(dbms_xplan.display);
再观察下面的SQL,使用到组合索引的第二列XSID和第三列CPHJID,注意到这里跳过了第一列引导列索引RWID,这其实就是索引跳跃现象,显然使用到的就是索引跳跃式扫描,在开发中我们应尽量避免出现索引跳跃。
explain plan for select * from zhxg_zhcp_hjcpxq t where
t.xsid = '5044889DBBF944E2B42B9E15E9F1CDA1'
and t.cphjid = '529e35bc-1e24-4dc9-ad0e-930c4372e40f';
select * from table(dbms_xplan.display);
七、总结
以上就是关于Oracle中常见的五种索引扫描方式的总结,主要注意下面几点,能有效提高SQL查询效率。
- 尽可能使SQL走唯一索引扫描和索引范围扫描;
- 至于索引全扫描可能遇到的较少些,一般出现了再具体分析下;
- 尽量避免出现索引跳跃现象,尽量满足Oracle索引最左前缀匹配原则;
参考资料:
https://www.cnblogs.com/zwl715/p/3601137.html
https://blog.csdn.net/choubei6141/article/details/100741178
https://www.cnblogs.com/yumiko/p/5972246.html