哔哩哔哩2019秋招技术岗(前端、运维、后端、移动端)第三套笔试题
1. 现有如下代码段:
x = 2;
while(x<n/2)
x = 2*x;
假设n>=0,则其时间复杂度应为(A)
A. O(log2(n))
B. O(nlog2(n))
C. O(n)
D. O(n^2)
解析:
时间复杂度与空间复杂度参考链接:https://blog.csdn.net/zolalad/article/details/11848739
2. 下列各序列中不是堆的是(B)
A. (9,8,5,3,4,2,1)
B. (9,4,5,8,3,1,2)
C. (9,5,8,4,3,2,1)
D. (9,8,5,4,3,1,2)
解析:
根据给出的序列 按照层级建树 例如A中 根节点为9,9的左节点为8,右节点为5。8的左节点为3,右节点为4。5的左节点为2,右节点为。 树建完之后,判断子节点是否全都大于自己的根节点或子节点是否全都小于自己的根节点。若满足该条件则形成的是堆,否则就不是堆。
在该题中的B,4小于自己的根节点9,8却大于自己的根节点4,所以不是堆
3. 下面关于二叉排序树的说法错误的是(A)
A. 在二叉排序树中,完全二叉树的查找效率最低
B. 对二叉排序树进行中序遍历,必定得到节点关键字的有序序列
C. 二叉排序树的平均查找长度是O(log2(n))
D. 二叉排序树的查找效率与二叉树的树形有关
解析:
二叉排序树即:对任一子树都有 “左树<子树根节点<右树” 的二叉树结构,对每一次查找,都会对当前节点的值进行比较,小于则进入左孩子,大于则进入右孩子,如此重复,直到确定结果。因此每次查找都对应着二叉树的的一条路径(分支),二叉树所有分支的平均长度决定了查找效率,越短越好
A选项:在所有二叉树中,完全二叉树的平均分支长度最短(节点数相同的情况下),查找效率最高,描述相反,故错误
B选项:因为“左树<子树根节点<右树”,而中序遍历也是左树优先输出,子树根节点次之,右树最后输出,这也正是它排序的原理,正确
C选项:以完全二叉树作为典型,n个节点的树深度为log2(n),其他树可以在增删时通过左旋和右旋调整成完全二叉树,正确
D选项:树的形状不同,分支的平均长度也会不同,树形能够综合考虑所有分支,故正确。但是要注意,除了完全二叉树外,其他树的深度并不能决定该树的查找效率,因为深度仅由最长的分支决定,只是考虑了一条路径,无法反映所有路径的平均长度。
4. 关于TCP协议描述不正确的是(B)
A. 建立连接需要三次握手
B. TIME_WAIT状态时不再接受报文
C. TIME_WAIT状态的持续时间是可以调整的
D. FIN报文一般由请求方负责发送
解析:
TIME_WAIT:
客户端连接在接收到服务器接收到报文段后,并未直接进入CLOSED状态,而是转移到TIME_WAIT状态。在这个状态,客户端 连接要等待一段长为2 MSL(Maxinum Segment Life 报文段最大生存时间)的时间,才能完全关闭。
先说第一点,如果Client直接CLOSED了,那么由于IP协议的不可靠性或者是其它网络原因,导致Server没有收到Client最后回复的ACK。那么Server就会在超时之后继续发送FIN,此时由于Client已经CLOSED了,就找不到与重发的FIN对应的连接,最后Server就会收到RST而不是ACK,Server就会以为是连接错误把问题报告给高层。这样的情况虽然不会造成数据丢失,但是却导致TCP协议不符合可靠连接的要求。所以,Client不是直接进入CLOSED,而是要保持TIME_WAIT,当再次收到FIN的时候,能够保证对方收到ACK,最后正确的关闭连接。
再说第二点,如果Client直接CLOSED,然后又再向Server发起一个新连接,我们不能保证这个新连接与刚关闭的连接的端口号是不同的。也就是说有可能新连接和老连接的端口号是相同的。一般来说不会发生什么问题,但是还是有特殊情况出现:假设新连接和已经关闭的老连接端口号是一样的,如果前一次连接的某些数据仍然滞留在网络中,这些延迟数据在建立新连接之后才到达Server,由于新连接和老连接的端口号是一样的,又因为TCP协议判断不同连接的依据是socket pair,于是,TCP协议就认为那个延迟的数据是属于新连接的,这样就和真正的新连接的数据包发生混淆了。所以TCP连接还要在TIME_WAIT状态等待2倍MSL,这样可以保证本次连接的所有数据都从网络中消失。
TIME_WAIT参考链接:https://blog.csdn.net/csdnlijingran/article/details/88545676
5. 可唯一确定一棵二叉树的是(A C)
A. 给定一棵二叉树的后序和中序遍历序列
B. 给定一棵二叉树的先序和后序遍历序列
C. 给定一棵二叉树的先序和中序遍历序列
D. 给定先序、中序和后序遍历序列中的任意一个即可
解析:
已知中序遍历、以及前、后、层其中一种均可确定一颗二叉树
拓展:知道树的前序遍历、和树得后序遍历,可以确定一棵树(树与二叉树的转换)
6.下面哪些是使用分治法的特征(A B D)
A. 该问题可以分解为若干个规模较小的相同问题
B. 子问题的解可以合并为该问题的解
C. 子问题必须是一样的
D. 子问题之间不包含公共的子问题
解析:
分治法所能解决的问题一般具有以下几个特征:
1、该问题的规模缩小到一定的程度就可以容易地解决
2、该问题可以分解为若干个规模较小的相同问题,即该问题具有最优子结构性质。
3、 利用该问题分解出的子问题的解可以合并为该问题的解;
4、 该问题所分解出的各个子问题是相互独立的,即子问题之间不包含公共的子子问题。
第一条特征是绝大多数问题都可以满足的,因为问题的计算复杂性一般是随着问题规模的增加而增加;
第二条特征是应用分治法的前提它也是大多数问题可以满足的,此特征反映了递归思想的应用;、
第三条特征是关键,能否利用分治法完全取决于问题是否具有第三条特征,如果具备了第一条和第二条特征,而不具备第三条特征,则可以考虑用贪心法或动态规划法。
第四条特征涉及到分治法的效率,如果各子问题是不独立的则分治法要做许多不必要的工作,重复地解公共的子问题,此时虽然可用分治法,但一般用动态规划法较好。
参考链接:https://www.cnblogs.com/butter-fly/archive/2016/07/03/5636514.html
7. 同一个进程的多个线程堆栈共享状况哪个描述正确 (A)
A. 堆共享,栈私有
B. 堆私有,栈共享
C. 堆共享,栈共享
D. 堆私有,栈私有
解析:
参考链接:https://blog.csdn.net/sinat_21026543/article/details/81912378
8. 有12个外观相同的小球,已知其中一个重量与其他的不同,给一个只能比较无法称重的天平,最少几次比较可以找出重量不同的小球 (D)
A. 6
B. 5
C. 4
D. 3
解析:
二分查找
9. 若外部存储上有3110400个记录,做6路平衡归并排序,计算机内存工作区能容纳400个记录,则排序好所有记录,需要作几趟归并排序(C)
A. 6
B. 3
C. 5
D. 4
解析:
log(6,3110400/400) = 5 设归并趟数为s次,对n个记录进行排序,有m个归并段,要进行k路归并排序,则归并趟数s=log(k,m);(k为底数,m为真数)
10. 75的阶乘末尾有(B)个零
A. 15
B. 18
C. 12
D. 20
解析:
计算 能被5整除的数的个数 + 能被25整除的个数
75 / 5 + 75 / 25 = 18
至于5的倍数和25的倍数重复:
5的倍数是增加1个零,25的倍数是增加2个零,重复的是1个零,所以只要加3个25的而不是6个
11. 在局域网内的某台主机用ping命令测试网络连接时,发现网络内的主机都可以连通,而不能与公网连通,问题可能是 (C)
A. 主机IP设置有误
B. 局域网的网关或路由器
C. 局域网DNS服务器设置有误
D. 没有设置连接局域网的网关
解析:
emmmmmm…我其实选的B…网上答案也都不一样…
A. 主机IP如果错误的话内网不能连通
C. 我觉得DNS设置有误的话,只是域名不能连通,但是IP可以连通
D. 没有设置局域网的网关,局域网间不会连通…
12. 不可能所有的花都结果。下列哪项最接近上述判定的含义(D)
A. 所有的花必然都不结果
B. 所有的花可能都不结果
C. 有的花可能不结果
D. 有的花必然不结果
解析:
不可能所有的花都结果。那必然是存在不结果的花的。
如果是有的花可能不结果,那有可能所有的花都结果。
13. 如果将固定文件块大小的文件系统中的文件块大小调大,会导致(B)
A. 更快的磁盘读写性能和更高的空间利用率
B. 更快的磁盘读写性能和更低的空间利用率
C. 更慢的磁盘读写性能和更高的空间利用率
D. 更慢的磁盘读写性能和更低的空间利用率
解析:
文件块大小变大会导致和其他没有变的文件块不能完美契合,降低空间利用率。而读写性能会提高。
14. 平面内有11个点,由它们连成48条不同的直线,由这些点可连成多少个三角形(A)
A. 160
B. 150
C. 165
D. 161
解析:
首先你要分析,平面中有11个点,如果这些点中任意三点都没有共线的,那么一共应该有C(11)2=55,可是,题目中说可以连接成48条直线,那么这11个点中必定有三个点共线的.55-48=7,从7来分析,
①假设有一组三个点共线,那么可以组成的直线在55的基础上应该减去C(3)2-1=2,因此,可以断定不仅有三点共线的,也可能有四个点共线的可能.
②假设有一组四个点共线,那么可以组成的直线在55的基础上应该减去C(4)2-1=5
【备注,五个点共线的可能不存在,因为,C(5)2-1=9>7,故,不可能有五条直线共线】
C(3)2-1+C(4)2-1=7,
因此,综上分析,这11个点中,必定有一组三个点共线,并且还有一组四个点共线.那么,这11个点能组成的三角形的个数为,C(11)3-C(3)3-C(4)3=165-1-4=160 【备注,三个点共线不能组成三角形】
15. 一个包含M个节点的三叉树,共有3M个指针,这些指针中有(C)个空指针
A. 2M-1
B. 2M
C. 2M+1
D. M
解析:
一个节点有3个指针,每添加一个增加3个指针,并消耗父节点的一个,所以有2M+1,1是因为根节点没有父节点。
16. 单向链表不满足的描述是(A D)
A. 可以随机访问任意结点
B. 删除头节点的时间复杂性是O(1)
C. 空间开销与链表长度成正比
D. 插入数据的时间开销比数组更大
解析:
A,链表只能进行按照顺序依次访问节点,无法做到随机访问。
B,因为链表删除元素不需要做元素移动,所以时间复杂度为O(1)。
C,链表是由节点构成,自然链表长度越大空间开销越大。
D,链表插入和删除元素因为不需要移动节点,所以相比较于数组而言,链表的时间复杂度为O(1),数组的时间复杂度O(n)。
17. A B两个主机之间建立了一个TCP链接,A主机发给B主机两个TCP报文,大小分别是500和300,第一个报文的序列号是200,那么B主机接受两个报文后,返回的确认号是(D)
A. 200
B. 700
C. 800
D. 1000
解析:
确认号为服务器发送的上一个数据包中的序列号+所该数据包中所带数据的大小。
第一个 200+500=700
第二个 700+300=1000
18. 符合数据库设计第三范式(3NF)的数据表设计是(A)
A. 学生{id, name, age},学科{course’s name, course’s id},分数{id, course’s id, score}
B. 学生{id, name, age},分数{id, course’s name, score}
C. 分数{student’s name,
score, course’s name}
D. 学科{id, name},分数{student’s name, id, score}
解析:
3NF 非主属性无传递依赖
19. 以下哪些算法可以检测一个有向图中是否存在环(A C)
A. 深度优先遍历
B. 广度优先遍历
C. 拓扑排序
D. 关键路径算法
解析:
DFS的时候,如果要访问的元素已经访问过,它在当前的栈内还没出栈,那么就是有环。BFS不行是因为可能有多个节点指向该节点,不一定是因为有环。
拓扑排序会循环执行以下两步:
(1) 选择一个入度为0的顶点,输出
(2) 从图中删除此顶点以及所有的出边
循环结束后,若输出的顶点数小于网中的顶点数,则说明有回路
20. 路由器工作在网络模型中的哪一层(C)
A. 物理层
B. 数据链路层
C. 网络层
D. 应用层
解析:
第一层:物理层,主要设备:中继器、集线器。
第二层:数据链路层,主要设备:二层交换机、网桥。
第三层:网络层,主要设备:路由器。
后四层依次为:传输层、会话层、表示层、应用层。后四层主要是计算机软件控制。
21. 某产品由甲乙两个工厂提供,甲工厂提供40%,乙工厂提供60%,甲工厂的次品率是1%,乙公司是2%,现在检测出一个次品,是甲工厂生产的概率是 25%
解析:
(40%*1%)/(40%*1%+60%*2%)=0.25
22. 对于满足SQL92标准的SQL语句:select foo,count(foo) from pokes where foo>10 group by foo having count(*)>5 order by foo,各关键字(select, from, where, group by, having, order by)的执行顺序应该是 FROM ->WHERE -> GROUP BY -> HAVING -> SELECT ->ORDER BY
解析:
因为查询的时候是先去找某表from,再在某表里面筛选条件where,然后对筛选完的进行分组group by,分组完就在分组的每一个组进行筛选条件having,然后取出来想要的列select,最后进行排序order by。
23. 给1,2,3,4,5按照顺序放入一个栈中(stack),同时随机的从栈中弹出,一共有 42 种弹栈组合
解析:
出栈问题的方案数满足卡特兰数公式C(2n,n)/(n+1)
卡特兰数参考链接:https://www.cnblogs.com/slp0622/p/9141936.html
https://blog.csdn.net/wentong_Xu/article/details/81428630
24. IPV6地址的长度是 128 位
解析:
IPv6的地址长度是128位。
IPv4和IPv6分别是互联网协议的第四版和第六版。它们是构成现今互联网技术的最基础的协议。
IPv4:IP地址由4个字节(0~255)构成,共32位。
IPv6:IP地址由16个字节(0~255)构成,共128位。
25. 10粒糖,每天至少吃一颗(数量不限),吃完为止,有 512 种吃法组合
解析:
10粒糖,并排放,中间有9个间隔 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 (1代表糖,0代表间隔) 现在在9个间隔里面选0到9个(表示10粒糖在1天到10天里吃完 那么就有 C(9,0)+C(9,1)+C(9,2)+C(9,3)+C(9,4)+C(9,5)+C(9,6)+C(9,7)+C(9,8)+C(9,9)=2^9 种吃法
26. 列举三种稳定的排序算法 冒泡排序、基数排序、归并排序、插入排序
解析:
参考连接:https://zhidao.baidu.com/question/549055758.html
27. 已知某二叉树的后序遍历是DFBEGCA,中序遍历的顺序是DBFACEG,其前序遍历顺序是 ABDFCGE
解析:
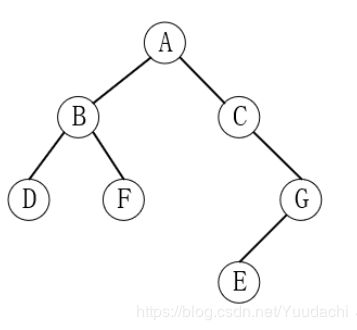
28. 已知函数如下
int foo(int N) {
return (1==N) ? 1 :N + foo(N-1);
}
foo(100) = ( )
括号的值是 5050
解析:
递归计算100 + … + 1
29. 我们常说的32位CPU是指CPU的 数据 总线是32位的
解析:
总线按功能和规范可分为五大类型:
数据总线(Data Bus):在CPU与RAM之间来回传送需要处理或是需要储存的数据。
地址总线(Address Bus):用来指定在RAM(Random Access Memory)之中储存的数据的地址。
控制总线(Control Bus):将微处理器控制单元(Control Unit)的信号,传送到周边设备。
扩展总线(Expansion Bus):外部设备和计算机主机进行数据通信的总线,例如ISA总线,PCI总线。
局部总线(Local Bus):取代更高速数据传输的扩展总线。
例如Intel 8086微处理器字长16位,其数据总线宽度也是16位。
30. 列举三种进程间通讯的方式 管道、消息队列、共享内存、信号量、网络通讯
解析:
参考资料:https://blog.csdn.net/qq_38880380/article/details/78527115
31. 为什么B+树适合数据库索引?(问答题)
解析:
参考链接:
https://www.cnblogs.com/tiancai/p/9024351.html
https://www.cnblogs.com/kkbill/p/11381783.html
32. 给定一个整数数组,判断其中是否有3个数和为N
时间限制:1秒
空间限制:131072K
输入描述:
输入为一行
逗号前为一个整数数组,每个元素间用空格隔开;逗号后为N
输出描述:
输出bool值
True表示存在3个和为N的数
False表示不存在3个和为N的数
输入样例:
1 2 3 4 5,10
输出样例:
True
代码(Java)
import java.util.*;
public class Main {
public static void main(String[] args) {
String input = new Scanner(System.in).nextLine();
int finalresult = Integer.parseInt(input.split(",")[1]);
String[] s = input.split(",")[0].split(" ");
List<Double> list = new ArrayList<>();
for (String tmp : s) {
list.add(Double.parseDouble(tmp));
}
Collections.sort(list);
boolean flag = true;
for (int i = 1; i < list.size()-1; i++) {
int left = i-1;
int right = i+1;
while (left >= 0 && right < list.size()){
if(list.get(i) + list.get(left) + list.get(right) == Double.parseDouble(String.valueOf(finalresult))){
System.out.println("True");
flag = false;
break;
}
if(list.get(i) + list.get(left) + list.get(right) < Double.parseDouble(String.valueOf(finalresult))){
right ++;
}else{
left --;
}
}
if(!flag){
break;
}
}
if(flag){
System.out.println("False");
}
}
}