大数据之Kylin入门——第五章Kylin之cube构建优化
前面说过构建一个n维的cube有多少种情况了,2^n-1种。构建一个10维的是1023种情况,一个20维的是1048576。那如果有30维甚至100维的了?这对于集群来说压力非常大,所以我们应该想想到底有没有必要构建这么多种情况了。
举个例子,年,月,日三个字段总共可以构建7种可能。但是年,日构建起来有必要吗?单独一个日构建有必要吗?真正有价值的组合是 年月日、年月、年,这3种可能。计算的可能性直接从7变为3,是不是节省了很多时间。
所以我们有必要对我们构建的cube进行优化。
1.使用衍生维度。
衍生维度用于在有效维度内将维度表上的非主键维度排除掉,并使用维度表的主键(其实是事实表上相应的外键)来替代它们。Kylin会在底层记录维度表主键与维度表其他维度之间的映射关系,以便在查询时能够动态地将维度表的主键“翻译”成这些非主键维度,并进行实时聚合。
举个例子,还是以员工表和部门表举例,如下job来自员工表,dname是员工表和部门表都有的,local是部门表的,sal为度量,构建一个三维的表,下面给了4条数据。
job dname local sal
1 111 a 10000
2 222 b 20000
3 333 c 30000
4 444 a 20000
本来总共有7中情况要构建,但是我觉得job和local之间有某种关系。所以我将local这个维度设成衍生变量,并保存job和lcal之间的映射关系。这样我只用构建job,dname这两个维度,总共就只有3种情况了(job,dname,job_dname)。表变成如下:
job dname sal
1 111 10000
2 222 20000
3 333 30000
4 444 20000
那如果我想通过local求sum(sal)该怎么做了?先找到job和sal的关系,然后通过job和local之间的映射转化成local和sal的关系,再求和。
job sal local sal
1 10000 a 10000
2 20000 =====》 b 20000
3 30000 c 30000
4 20000 a 20000
但是我们发现,job和sal转化为local和sal之后不一定是最终的结果,比如有两条数据local都是a,还要再聚合一次,local和sal的最终结果如下。
local sal
a 30000
b 20000
c 30000
所以这里你就发现了衍生维度的好处和坏处了吧,好处是构建cube的情况变少了(最终的数据量少,占用空间少),坏处就是实时查询的时候还要做聚合操作(多花费一些时间),以空间换时间,所以到底用不用衍生维度只能权衡。如果最终某个维度要聚合的数据量很大,那还是不要把这个维度设成衍生维度了。
衍生维度设置如下,将你需要的维度选择derived,而不是normal。


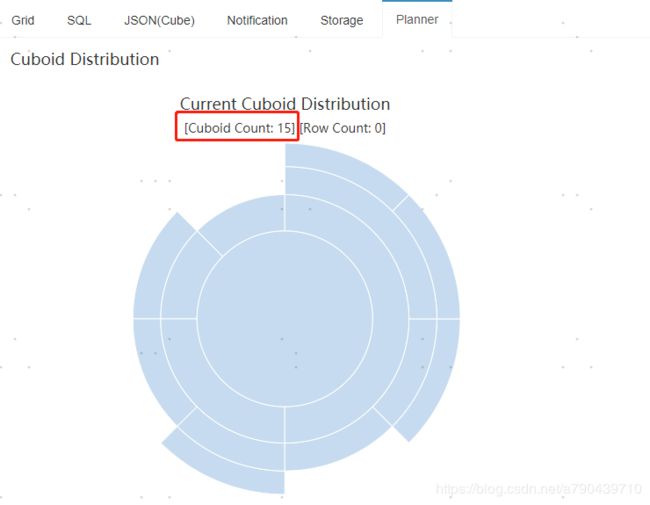
设置完成后我们看看cube和以前有哪些不同,查看cuboid发现只有15个了,说明衍生维度生效了。
2.使用聚合组
聚合组可以把我们的所有维度情况分为几个组,比如最开始举例的年月日。只可能有3种情况(年,年月,年月日),我们发现年是肯定有的,那我们是不是只需要计算和年有关的情况就行了,其他情况忽略掉就可以了。
有3种方法给我们来分组。
1.强制维度。
把A设成强制维度,所有情况中必须包换A。年月日的例子用年作为强制维度是不是就可以少计算几种情况。

2.层级维度
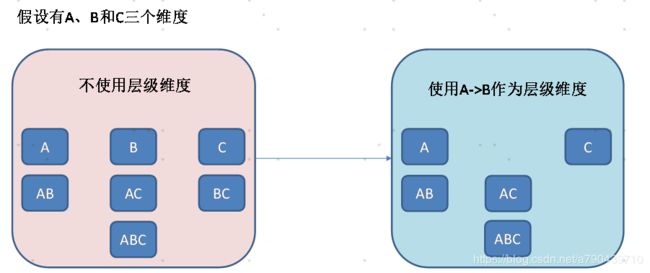
使用A->B作为层级维度,不可能出现以B开头的可能。
3.联合维度

使用AB作为联合维度,结果中有A,B的,必须同时包含AB。
聚合维度的设置在如下图所示位置:
3.RowKey优化
这里的rowkey就是hbase的rowkey,Kylin会把所有的维度按照顺序组合成一个完整的Rowkey,并且按照这个Rowkey升序排列Cuboid中所有的行。设计良好的Rowkey将更有效地完成数据的查询过滤和定位,减少IO次数,提高查询速度,维度在rowkey中的次序,对查询性能有显著的影响。
1.被用作where过滤条件的维度放在前面。

考虑如上的sql情况,左边的hbase表需要扫描3次位置,右边的表只需要扫描一次。(hbase以字典排序,当然上面3个字段存在hbase里面组合起来是一个rowkey)
2.把基数大的维度放在基数小的维度前面。

基数的意思就是维度去重后的个数,比如月维度去重后是12,日去重后是31,所以日维度放在月维度前面。
以上图说明这样做的好处,一开始的四维1111分解为三维的时候有四种情况,这里列出两种情况1110和1101。当分解为二维的情况1100的时候,这个二维的1100的数据既可以从三维1110取也可以从三维1101取。Kylin内部的机制是从id小的取,也就是从1101取。1101的D有3条数据,而1110的C有6条数据。所以从1101取数据聚合的数据量更小,效率更好。为什么C的数据量比D大了?这就是因为我们一开始对四维的维度排序的时候是按照基数大小ABCD排序的,而不是按照ABDC来排序的。
rowkey设置在如图所示位置:
4.并发粒度优化
当Segment中某一个Cuboid的大小超出一定的阈值时,系统会将该Cuboid的数据分片到多个分区中,以实现Cuboid数据读取的并行化,从而优化Cube的查询速度。具体的实现方式如下:构建引擎根据Segment估计的大小,以及参数“kylin.hbase.region.cut”的设置决定Segment在存储引擎中总共需要几个分区来存储,如果存储引擎是HBase,那么分区的数量就对应于HBase中的Region数量。kylin.hbase.region.cut的默认值是5.0,单位是GB,也就是说对于一个大小估计是50GB的Segment,构建引擎会给它分配10个分区。用户还可以通过设置kylin.hbase.region.count.min(默认为1)和kylin.hbase.region.count.max(默认为500)两个配置来决定每个Segment最少或最多被划分成多少个分区。由于每个Cube的并发粒度控制不尽相同,因此建议在Cube Designer 的Configuration Overwrites中为每个Cube量身定制控制并发粒度的参数。
并发粒度优化在如图所示位置:
