深度学习下的目标检测算法——TensorFlow 2.0下的YOLOv3实践
本文主要包含如下内容:
- 修改qqwweee/keras-yolo3(目标检测算法YOLOv3的一个Keras版本的优秀实现),将其修改为tf.keras为主导的,并修订不兼容的接口和逻辑,使其支持TensorFlow 2.0版本
- 实践修改后的YOLOv3算法
- 对实践结果的简单分析
修改后的项目 GitHub:
tf2-keras-yolo3 (https://github.com/AaronJny/tf2-keras-yolo3)
转载请注明来源:https://blog.csdn.net/aaronjny/article/details/103658254
前言
说到目标检测,YOLO系列算法可以算是颇负盛名。目标检测相关的算法有不少,而YOLO因其识别速度快而出名,常被用于实时目标检测场景中。今天,我们就来实践一下YOLOv3算法。
因为YOLO原理我是清楚的,又觉得实现起来太麻烦了,所以本来想着就不自己造轮子了,直接从GitHub上找一个优秀的开源实现,拜读一下代码,然后调试跑通结束。但没想到,最后还是得动手写(或者说改?)代码……

因为我主要使用的深度学习框架是TensorFlow和Keras,所以直接去找了算法的Keras实现。然后就找了qqwweee/keras-yolo3,GitHub上4928 star。先来读一下它的README文件:
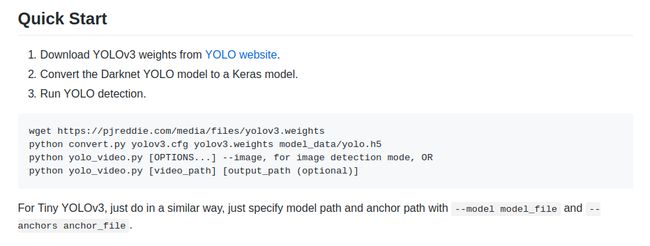
文档上说的很清楚,那就跟着Quick Start来,首先下载预训练好的权重文件,然后通过convert.py脚本构建模型,并将权重转成Keras版本的。到这里都没什么问题,然而当尝试执行测试脚本yolo_video.py时,问题出现了:

为了测试算法,我随便从网上下载了一个视频,然后调用脚本进行测试。根据错误提示来看,是因为我用的是TensorFlow 2.0,而TensorFlow 2.0与1.x版本的差别很大,删减、调整了很多接口,并且由于Eager execution的出现,编码习惯和逻辑也有所变更,故无法兼容。看了一下README后面的内容,能看到作者当时的测试环境如下:

这个项目是很久之前写的了,上一次更新已经是一年前了,所以与新版本的框架无法兼容也在意料之中。我使用了一个和作者相同的虚拟环境进行测试,是没有问题的,正常可用。但大家毕竟要往前走嘛,我也不能换TensorFlow 1.6进行开发,于是就萌生了修改这个项目,让它支持TensorFlow 2.0的想法,顺便也能对YOLOv3的实现有更深的理解。
修改qqwweee/keras-yolo3 源码
那就搞吧,我先fork了项目,然后通读了一遍项目源码,确定修改应该是没什么问题的,毕竟Keras是使用TensorFlow做计算引擎的,并且TensorFlow 2.0中的tf.keras与最新版本的Keras的接口是保持一致的。把代码clone下来,开始改代码,主要的修改如下:
- 使用tf.keras系列接口,代替keras下的系列接口
- 使用tf下的系列接口、和tf.keras.backend下的系列接口,替代keras.backend下的系列接口
- 修改部分基于TensorFlow 1.x版本的接口和逻辑,使项目支持TensorFlow 2.0(比如删除tf.get_session、sess.run、tf.placeholder之类的写法,使用eager execution的写法替代)
- 修改原项目部分命令行参数错误
修改后的代码已经push到GitHub上,更多信息请参见tf2-keras-yolo3 (https://github.com/AaronJny/tf2-keras-yolo3)。因为是fork过来的,所以修改细节可以直接参考commit记录。
已经修改完毕,让我们测试一下代码能否正常运行。下面使用tf2-keras-yolo3做实践演示。
演示使用tf-keras-yolo3进行目标检测
- 从GitHub上clone tf2-keras-yolo3 的代码。
git clone https://github.com/AaronJny/tf2-keras-yolo3
等待clone完成:
正克隆到 'tf2-keras-yolo3'...
remote: Enumerating objects: 5, done.
remote: Counting objects: 100% (5/5), done.
remote: Compressing objects: 100% (4/4), done.
remote: Total 161 (delta 1), reused 4 (delta 1), pack-reused 156
接收对象中: 100% (161/161), 158.13 KiB | 0 bytes/s, 完成.
处理 delta 中: 100% (75/75), 完成.
- 切换到项目目录下,并下载预训练好的权重。
cd tf2-keras-yolo3/
wget https://pjreddie.com/media/files/yolov3.weights
模型大小为237M,等待下载完成:
--2019-12-22 20:40:20-- https://pjreddie.com/media/files/yolov3.weights
正在解析主机 pjreddie.com (pjreddie.com)... 128.208.4.108
正在连接 pjreddie.com (pjreddie.com)|128.208.4.108|:443... 已连接。
已发出 HTTP 请求,正在等待回应... 200 OK
长度:248007048 (237M) [application/octet-stream]
正在保存至: “yolov3.weights”
yolov3.weights 100%[================================================>] 236.52M 3.61MB/s in 63s
2019-12-22 20:41:24 (3.74 MB/s) - 已保存 “yolov3.weights” [248007048/248007048])
- 然后通过
convert.py脚本构建模型,并将权重转成Keras版本的。
python convert.py yolov3.cfg yolov3.weights model_data/yolo.h5
等待转换:
...
Saved Keras model to model_data/model.h5
Read 62001757 of 62001757.0 from Darknet weights.
- 使用
yolo_video.py脚本进行验证。
首先,获取一个视频,任何渠道不限,从网上下载或者自己拍摄都行,把它复制到项目目录下。为了方便,我把它重命名为video.mp4。然后使用yolo_video.py脚本进行验证:
python yolo_video.py --input video.mp4
脚本运行后,开始对视频逐帧进行识别和输出,形成了一个加上了标记框的新视频。我从输出结果里面截了张图片:

能够发现,FPS只有4,很低,后面我会分析原因,这里先跳过。这个脚本除了对视频进行目标检测外,也可以直接对图片进行处理,我从网上找了一张常用在目标检测演示里的图片:

为了演示方便,也把它放到了项目目录下,重命名为demo.jpg。先输入如下命令,进入图片检测模式:
python yolo_video.py --image
然后等待模型加载。当模型加载成功后,会出现提示,要求输入待检测的图片名称:
Input image filename:
这时,我们输入demo.jpg,并回车。程序会输出加了标记框的demo图片:

OK,演示部分到此为止。这些都是建立在预训练好的权重上进行的,可能你想训练自己的目标检测模型,去检测其他的东西,自然也是可以的。参考README中的Training部分说明即可,训练耗时,这里我就不演示了,有兴趣的可以自行尝试。
下面补上刚才没有展开的结果分析。
对识别结果的分析
前面对视频进行目标检测时,我们发现输出的视频FPS很低,只有4,这是远远达不到实时目标检测的水平的。
观察算法执行时的控制台输出,能够发现,对一帧图片进行目标检测约需要260ms左右(硬件环境:笔记本 GTX 1060),有点慢了。看了原项目的README,原作者qqwweee大佬认为,可能是PIL拖慢了速度,原内容如下:
4. The speed is slower than Darknet. Replacing PIL with opencv may help a little.
但我不这么觉得,我进行了测试,PIL在整个过程中并没有明显的长耗时。我对一次目标检测过程中的各个代码块分别进行了耗时统计,发现主要耗时在如下代码块,耗时约170ms左右:
for c in range(num_classes):
class_boxes = tf.boolean_mask(boxes, mask[:, c])
class_box_scores = tf.boolean_mask(box_scores[:, c], mask[:, c])
nms_index = tf.image.non_max_suppression(
class_boxes, class_box_scores, max_boxes_tensor, iou_threshold=iou_threshold)
class_boxes = K.gather(class_boxes, nms_index)
class_box_scores = K.gather(class_box_scores, nms_index)
classes = K.ones_like(class_box_scores, 'int32') * c
boxes_.append(class_boxes)
scores_.append(class_box_scores)
classes_.append(classes)
根据代码来看,这段主要是对于每一种class,分别进行非极大值抑制。训练的可检测类别为80种,也就是说循环体要计算80次。后面有时间了,可以考虑能否将此段代码改写为并行计算形式,以提高速度(计算时显卡使用率只有25%左右,说明并行计算不充分)。
当然了,毕竟我用的只是笔记本上的GTX 1060这种弱鸡显卡,换用更好的显卡也可以进一步提升检测效率(从单个计算单元的性能考虑,如果单个计算单元的计算性能提高了,哪怕只使用了25%的计算单元,整体性能可能也是有提升的,但不如并行更有效)。
除了提高算法效率和显卡性能外,想要达到实时目标检测的目的,还有一种取巧的方法——对视频进行采样。
举个例子来说,假设是对摄像头输入的视频进行目标检测,如果视频的每一帧都进行检测,算法的性能无法满足要求。但我们可以每隔若干帧进行一次检测,比如10帧或20帧(这取决实际应用场景,当视频中目标的变化速度越慢,采样的频率就可以越低,间隔的帧数就可以越多。比如视频中只有行人,和视频中只有行驶中的汽车,采样的频率肯定是不相同的),中间的帧数忽略。只要采样的频率设置的合适,对实际的应用场景影响其实不大,进而在满足计算时间的限制的同时,尽量减少甚至消除对实际任务的不良影响。
结语
好了,如上就是本篇文章的全部内容,希望对你有所帮助。
如果你喜欢这篇文章的话,麻烦给点个赞呗~
菜鸟一只,如有纰漏之处,请大佬们指正,欢迎各位大佬拍砖~
参考
qqwweee/keras-yolo3