kylin 重点介绍
Kylin是ebay开发的一套OLAP系统,它是一个MOLAP系统,主要用于支持大数据生态圈的数据分析业务,采用多维立方体(Cube)预计算技术,它主要是通过预计算的方式将用户设定的多维立方体缓存到HBase中,通过预计算的方式缓存了所有需要查询的的数据结果,需要大量的存储空间(原数据量的10+倍),可以将某些场景下的大数据 SQL 查询速度提升到亚秒级别。
Kylin系统架构
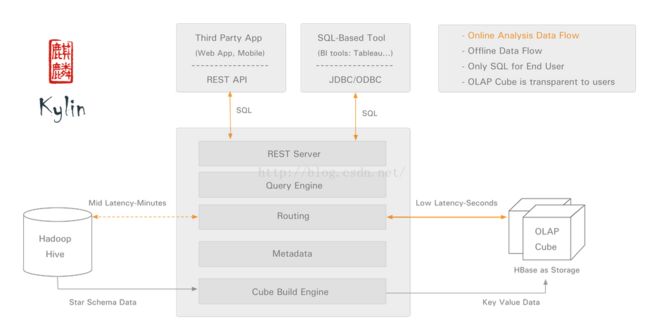
kylin由以下几部分组成:
· REST Server:提供一些restful接口,例如创建cube、构建cube、刷新cube、合并cube等cube的操作,project、table、cube等元数据管理、用户访问权限、系统配置动态修改等。除此之外还可以通过该接口实现SQL的查询,这些接口一方面可以通过第三方程序的调用,另一方也被kylin的web界面使用。
· jdbc/odbc接口:kylin提供了jdbc的驱动,驱动的classname为org.apache.kylin.jdbc.Driver,使用的url的前缀jdbc:kylin:,使用jdbc接口的查询走的流程和使用RESTFul接口查询走的内部流程是相同的。这类接口也使得kylin很好的兼容tebleau甚至mondrian。
· Query引擎:kylin使用一个开源的Calcite框架实现SQL的解析,相当于SQL引擎层。
· Routing:该模块负责将解析SQL生成的执行计划转换成cube缓存的查询,cube是通过预计算缓存在hbase中,这部分查询是可以再秒级甚至毫秒级完成,而还有一些操作使用过查询原始数据(存储在hadoop上通过hive上查询),这部分查询的延迟比较高。
· Metadata:kylin中有大量的元数据信息,包括cube的定义,星状模型的定义、job的信息、job的输出信息、维度的directory信息等等,元数据和cube都存储在hbase中,存储的格式是json字符串,除此之外,还可以选择将元数据存储在本地文件系统。
· Cube构建引擎:这个模块是所有模块的基础,它负责预计算创建cube,创建的过程是通过hive读取原始数据然后通过一些mapreduce计算生成Htable然后load到hbase中。
Kylin涉及的基础概念
星型模型
星形模式是多维的数据关系,它由事实表(Fact Table)和维表(Dimension Table)组成。每个维表中都会有一个维作为主键,所有这些维的主键结合成事实表的主键。事实表的非主键属性称为事实,它们一般都是数值或其他可以进行计算的数据。
维度和度量
维度代表着我们审视数据的角度
通常是数据记录的一个属性,时间是一种维度,地点是一种维度,状态是一种维度。
度量代表着基于数据所计算出来的考量值
通常是一个数值,比如这个月份的销售额,购买某产品的客户量。
维度基数
维度基数:指的是该维度在数据集中出现的不同值的 个数。
个别维度如“用 户ID”的基数会超过百万甚至千万。基数超过一百万的维度通常被称为超高基数维度(Ultra High Cardinality,UHC),需要引起设计者的注意。
Cube中所有维度的基数都可以体现出Cube的复杂度,如果一个Cube 中有好几个超高基数维度,那么这个Cube膨胀的概率就会很高。
在创建 Cube前需要对所有维度的基数做一个了解,这样就可以帮助设计合理的 Cube。
Cube、Cuboid和Cube Segment
Cube(或Data Cube),即数据立方体,是一种常用于数据分析与索引 的技术;它可以对原始数据建立多维度索引。通过Cube对数据进行分析,
可以大大加快数据的查询效率。
Cuboid在Kylin中特指在某一种维度组合下所计算的数据。
Cube Segment是指针对源数据中的某一个片段,计算出来的Cube数 据。通常数据仓库中的数据数量会随着时间的增长而增长,而Cube Segment也是按时间顺序来构建的。
kylin 优化
Cube的优化目的始终有两个:空间优化和查询时间优化。
1,Cuboid剪枝优化
Kylin会对每一种维度的组合进行预计算,每种维度的组合的预计算结果 被称为Cuboid。假设有4个维度,结合简单的数学知识,我们可能最终会 有2^4 =16个Cuboid需要计算。
Cube的剪枝优化则是一种试图减少 额外空间占用的方法,这种方法的前提是不会明显影响查询时间的缩减。
优化工具如下:
(1)使用衍生维度
衍生维度用于在有效维度内将维度表上的非主键维度排除掉,并使用维度表的主键(其实是事实表上相应的外键)来替代它们。
Kylin会在底层记 录维度表主键与维度表其他维度之间的映射关系,以便在查询时能够动 态地将维度表的主键“翻译”成这些非主键维度,并进行实时聚合
比如时间维度类,日维度作为普通维度,周和月维度作为衍生维度,以更高的粒度(比如按周、 按月)来聚合时,如果在查询时获取按日聚合的Cuboid数据,并在查询引擎中实时地进行上卷操作,那么就达到了使用牺牲一部分运行时性能来节省Cube空间占用的目的。
(2)使用聚合组
聚合组(Aggregation Group)是一种更为强大的剪枝工具。
聚合组假设 一个Cube的所有维度均可以根据业务需求划分成若干组(当然也可以是 一个组),由于同一个组内的维度更可能同时被同一个查询用到,因此会表现出更加紧密的内在关联。
每个分组的维度集合均是Cube所有维度的 一个子集,不同的分组各自拥有一套维度集合,它们可能与其他分组有 相同的维度,也可能没有相同的维度。
每个分组各自独立地根据自身的 规则贡献出一批需要被物化的Cuboid,所有分组贡献的Cuboid的并集就 成为了当前Cube中所有需要物化的Cuboid的集合。
不同的分组有可能会 贡献出相同的Cuboid,构建引擎会察觉到这点,并且保证每一个Cuboid无 论在多少个分组中出现,它都只会被物化一次。
(3)强制维度(Mandatory)
如果一个维度被定义为强制维度,那么这个分组产生的所有Cuboid中每一个Cuboid都会包含该维度。这种维度意味着每次查询的group by中都会携带的,将某一个dimension设置为mandatory可以将cuboid的个数减少一半。

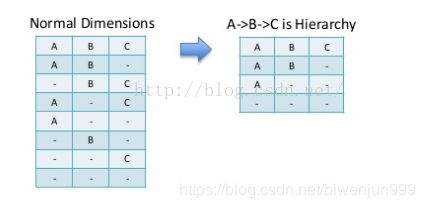
(4)层级维度(Hierarchy),每个层级包含两个或更多个维度。
我们对于多维数据的操作经常会有上卷下钻之类的操作,这也就需要要求维度之间有层级关系,例如国家、省、城市,年、季度、月等。有层级关系的维度也可以大大减少cuboid的个数。
(5)联合维度(Joint),每个联合中包含两个或更多个维度,如果某些列 形成一个联合,那么在该分组产生的任何Cuboid中,这些联合维度要么一 起出现,要么都不出现.
检查Cube大小检查Cube大小
在Web GUI的Model页面选择一个READY状态的Cube,当我们把光标 移到该Cube的Cube Size列时,Web GUI会提示Cube的源数据大小,以及当 前Cube的大小除以源数据大小的比例,称为膨胀率(Expansion Rate)
一般来说,Cube的膨胀率应该在0%~1000%之间。
2,并发粒度优化
当Segment中某一个Cuboid的大小超出一定的阈值时,系统会将该 Cuboid的数据分片到多个分区中,以实现Cuboid数据读取的并行化,从而 优化Cube的查询速度.
如果存储引擎是HBase,那么分区的数量就 对应于HBase中的Region数量。
由于每个Cube的并发粒度控制不尽相同,因此建议在Cube Designer 的Configuration Overwrites中为每个Cube量身定制控制并发粒度的参数。
用户还可以通过设置kylin.hbase.region.count.min(默认为 1)和kylin.hbase.region.count.max(默认为500)两个配置来决定每个Segment 最少或最多被划分成多少个分区。
3,Rowkeys优化
kylin的cube数据是作为key-value结构存储在hbase中的,key是每一个维度成员的组合值,不同的cuboid下面的key的结构是不一样的,例如cuboid={brand,product,year}下面的一个key可能是brand='Nike',product='shoe',year=2015,那么这个key就可以写成Nike:shoe:2015,但是如果使用这种方式的话会出现很多重复,所以一般情况下我们会把一个维度下的所有成员取出来,然后保存在一个数组里面,使用数组的下标组合成为一个key,这样可以大大节省key的存储空间,kylin也使用了相同的方法,只不过使用了字典树(Trie树),每一个维度的字典树作为cube的元数据以二进制的方式存储在hbase中,内存中也会一直保持一份。
(1)编码
编码(Encoding)代表了该维度的值应使用何种方式进行编码,合适 的编码能够减少维度对空间的占用.
(2)按维度分片
如果按照维度划分分片,假设按照一个基数比较高的维度进行分片,那么在这种情况下,每个分片将会承担一部分的高级维度的数据,且各个分片不会有相同的数据。
(3)调整Rowkeys顺序
1)在查询中被用作过滤条件的维度有可能放在其他维度的前面.
2)将经常出现在查询中的维度放在不经常出现的维度的前面.
3)对于基数较高的维度,如果查询会有这个维度上的过滤条件,那么将它往前调整;如果没有,则向后调整.
cube 高级设置
New Aggregation Group+:Kylin默认会把所有维度都放在同一个聚合组中;如果维度数较多(例 如>10),那么建议用户根据查询的习惯和模式,单击“New Aggregation Group+”,
将维度分为多个聚合组。通过使用多个聚合组,可以大大降低 Cube中的Cuboid数量。下面来举例说明,如果一个Cube有(M+N)个维度, 那么默认它会有2^m+n 个Cuboid;
如果把这些维度分为两个不相交的聚合 组,那么Cuboid的数量将被减少为2^m +2^n 。
Mandatory Dimensions: 必要维度,用于总是出现的维度。例如,如果你的查询中总是会带有 “ORDER_DATE” 做为 group by 或 过滤条件, 那么它可以被声明为必要维度。
这样一来,所有不含此维度的 cuboid 就可以被跳过计算。
Hierarchy Dimensions: 层级维度,例如 “国家” -> “省” -> “市” 是一个层级;不符合此层级关系的 cuboid 可以被跳过计算,例如 [“省”], [“市”]. 定义层级维度时,将父级别维度放在子维度的左边。
Joint Dimensions:联合维度,有些维度往往一起出现,或者它们的基数非常接近(有1:1映射关系)。例如 “user_id” 和 “email”。把多个维度定义为组合关系后,所有不符合此关系的 cuboids 会被跳过计算。
rowkeys: 是由维度编码值组成。”Dictionary” (字典)是默认的编码方式; 字典只能处理中低基数(少于一千万)的维度;如果维度基数很高(如大于1千万), 选择 “false” 然后为维度输入合适的长度,
通常是那列的最大长度值; 如果超过最大值,会被截断。请注意,如果没有字典编码,cube 的大小可能会非常大。
你可以拖拽维度列去调整其在 rowkey 中位置; 位于rowkey前面的列,将可以用来大幅缩小查询的范围。
通常建议将 mandantory 维度放在开头, 然后是在过滤 ( where 条件)中起到很大作用的维度;
如果多个列都会被用于过滤,将高基数的维度(如 user_id)放在低基数的维度(如 age)的前面。
Mandatory Cuboids: 维度组合白名单。确保你想要构建的 cuboid 能被构建。
Cube Engine: cube 构建引擎。有两种:MapReduce 和 Spark。如果你的 cube 只有简单度量(SUM, MIN, MAX),建议使用 Spark。如果 cube 中有复杂类型度量(COUNT DISTINCT, TOP_N),建议使用 MapReduce。
Advanced Dictionaries: “Global Dictionary” 是用于精确计算 COUNT DISTINCT 的字典, 它会将一个非 integer的值转成 integer,以便于 bitmap 进行去重。
如果你要计算 COUNT DISTINCT 的列本身已经是 integer 类型,那么不需要定义 Global Dictionary。
Global Dictionary 会被所有 segment 共享,因此支持在跨 segments 之间做上卷去重操作。
请注意,Global Dictionary 随着数据的加载,可能会不断变大。
“Segment Dictionary” 是另一个用于精确计算 COUNT DISTINCT 的字典,与 Global Dictionary 不同的是,它是基于一个 segment 的值构建的,因此不支持跨 segments 的汇总计算。
如果你的 cube 不是分区的或者能保证你的所有 SQL 按照 partition_column 进行 group by, 那么你应该使用 “Segment Dictionary” 而不是 “Global Dictionary”,这样可以避免单个字典过大的问题。
请注意:”Global Dictionary” 和 “Segment Dictionary” 都是单向编码的字典,仅用于 COUNT DISTINCT 计算(将非 integer 类型转成 integer 用于 bitmap计算),他们不支持解码,因此不能为普通维度编码。
Advanced Snapshot Table: 为全局 lookup 表而设计,提供不同的存储类型。
Advanced ColumnFamily: 如果有超过一个的COUNT DISTINCT 或 TopN 度量, 你可以将它们放在更多列簇中,以优化与HBase 的I/O。