搭建ELK集群
一、ELK介绍:
- Elasticsearch是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等
- Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。
- Kibana 也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
- Beats在这里是一个轻量级日志采集器,其实Beats家族有6个成员,早期的ELK架构中使用Logstash收集、解析日志,但是Logstash对内存、cpu、io等资源消耗比较高。相比 Logstash,Beats所占系统的CPU和内存几乎可以忽略不计
ELK Stack (5.0版本之后)--> Elastic Stack == (ELK Stack + Beats)。目前Beats包含六种工具:
- Packetbeat: 网络数据(收集网络流量数据)
- Metricbeat: 指标 (收集系统、进程和文件系统级别的 CPU 和内存使用情况等数据)
- Filebeat: 日志文件(收集文件数据)
- Winlogbeat: windows事件日志(收集 Windows 事件日志数据)
- Auditbeat:审计数据 (收集审计日志)
- Heartbeat:运行时间监控 (收集系统运行时的数据)
二、搭建ELK集群
1、准备工作:
(1)下载ELK软件包:
elasticsearch-6.5.4.tar.gz、filebeat-6.5.4-linux-x86_64.tar.gz、jdk-8u121-linux-x64.tar.gz、kibana-6.5.4-linux-x86_64.tar.gz、Kibana_Hanization-master.zip、logstash-6.5.4.tar.gz
(2)三台主机:
192.168.209.149(master-node 主节点)
192.168.209.150(data-node1 node节点1)
192.168.209.151(data-node2 node节点2)
- 设置host 在/etc/host中新增以下配置
192.168.209.149 master-node
192.168.209.150 data-node1
192.168.209.151 data-node2
(4)关闭防火墙:
Systemctl stop firewalld
Systemctl disable firewalld
(5)关闭selinux
Vim /etc/selinux/config
修改SELINUX=disabled
2、搭建elasticsearch
- 创建elk用户和组
groupadd elk
useradd -g elk elk
- 配置jdk
- 创建目录/opt/app/elk,将ELK软件包放在这个目录下
- 改/opt/app/elk的属主属组为elk:chown -R elk:elk /opt/app/elk
- 解压jdk、配置jdk环境变量
Vim .bash_profile
增加如下配置:
JAVA_HOME="/opt/app/ELK/jdk1.8.0_121"
PATH="$JAVA_HOME/bin:$PATH"
CLASSPATH=".:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar"
export JAVA_HOME
export PATH
export CLASSPATH
Source一下
使用java -version查看jdk环境变量是否设置成功
- 配置elasticsearch
- 切换到elk用户,解压elasticsearch-6.5.4.tar.gz
- 依次配置主节点与node节点elasticsearch,主节点与node节点设置是不一样的,具体看以下解释

elasticsearch.yml配置文件
cluster.name: chenkya # 集群中的名称node.name: master-node # 该节点名称node.master:true# 意思是该节点为主节点 (主节点设置为true,node节点设置为false)
node.data:false# 表示这不是数据节点 (主节点设置为false,node节点设置为true)
network.host: 0.0.0.0 # 监听全部ip,在实际环境中应设置为一个安全的iphttp.port: 9200 # es服务的端口号discovery.zen.ping.unicast.hosts: ["192.168.209.149","192.168.209.150","192.168.209.151"]# 配置自动发现
- 启动elastiicsearch
进入bin目录,./elasticsearch
这个时候可能会报错,这个问题是因为elk用户拥有的内存较小,至少需要262144

这个时候需要改vm.max_map_count值
切换到root用户,在/etc/sysctl.conf文件最后添加一行
vm.max_map_count=262144
再执行这条命令
sysctl -w vm.max_map_count=262144
报错max file descriptors [65535] for elasticsearch process is too low
解决办法:修改/etc/security/limits.d/20-nproc.conf 加入如下配置
* soft nofile 65536
* hard nofile 131072
* soft memlock unlimited
* hard memlock unlimited
报错max number of threads [3812] for user [els] is too low, increase to at least [4096]
解决方法3
修改/etc/security/limits.d/20-nproc.conf,做以下配置
* soft nproc 4096
root soft nproc unlimited
- 重新切回elk用户,再启动。查看端口9200是否起来,是的话就表示启动成功了
- 查看集群状态
curl '192.168.209.149:9200/_cluster/health?pretty'

curl '192.168.209.149:9200/_cluster/state?pretty'可以查看集群的详细信息
三、搭建logstash
logstash是ELK中负责收集和过滤日志的,我们在192.168.209.150上搭建logstash
- 解压logstash。配置logstash配置文件

也可以自己写.conf的配置文件,在启动的时候加-f选项指向你写的配置文件即可
logstash的配置文件须包含三个内容:
input{}:此模块是负责收集日志,可以从文件读取、从redis读取或者开启端口让产生日志的业务系统直接写入到logstash
filter{}:此模块是负责过滤收集到的日志,并根据过滤后对日志定义显示字段
output{}:此模块是负责将过滤后的日志输出到elasticsearch或者文件、redis等。Output直接输出到Elasticsearch

Input模块有如下参数:
- type:代表类型,其实就是将这个类型推送到Elasticsearch,方便后面的kibana进行分类搜索,一般直接命名业务系统的项目名称
- path:读取文件的路径
- start_position => “beginning”是代表从文件头部开始读取

- filter{}中的grok是采用正则表达式来过滤日志,其中%{TIMESTAMP_ISO8601}代表一个内置获取2016-11-05 00:00:03,731时间的正则表达式的函数,%{TIMESTAMP_ISO8601:date1}代表将获取的值赋给date1,在kibana中可以体现出来
上图有两条grok,第一条不符合将执行第二条
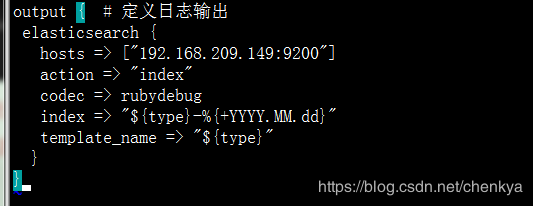
其中index是定义将过滤后的日志推送到Elasticsearch后存储的名字
%{type}是调用input中的type变量
Hosts指向elasticsearch的IP加端口
- 启动logstash
命令 ./logstash -f /opt/app/ELK/logstash-6.5.4/config/logstash-test.conf
也可以加-t 选项先测试一下 logstash-test.conf是否正确

- 搭建kibana
我们在192.168.209.149上搭建kibana
刚才我们已经上传kibana的软件包到/opt/app/ELK目录下了,解压后cd 到/opt/app/ELK/kibana-6.5.4-linux-x86_64/config
配置kibana.yml。修改如下参数

保存后启动kibana
cd /opt/app/ELK/kibana-6.5.4-linux-x86_64/bin
nohup ./kibana&
可以通过http://192.168.209.149:5601访问kibana
五、Logstash filter参数学习:
上面说过,filter中的grok是采用正则表达式来过滤日志的。我们可以使用grok自带的正则表达式参数来写正则过滤日志,也可以将grok自带的正则表达式参数拼接成为我们需要的参数来供我们调用写正则
Grok自带的正则表达式参数可以参考下面的网址
https://www.cnblogs.com/stozen/p/5638369.html
我们可以在kibana上来测试我们写的正则表达式是否正确
我们来演示一下:
假如我们有这样一条日志,需要写正则表达式。我们可以在kibana上进行验证
Apr 04 10:37:59] [557580441] INFO [ajp-10.220.45.117-8109-294] [A35F4C076A7A79DC819BDA2DC7A132C0.HXIBEServer1] - |223.221.201.123|http://new.hongkongairlines.com/hxair/ibe/air/spinnerCalendar.do|?spinner=FromFlightCalendar&Search/calendarOutboundDate=2019-09-29&Search/calendarInboundDate=2019-10-16&Search/calendarSearch=false|||||||||281
首先登陆kibana,选择Dev Tools,点击Grok Debugger
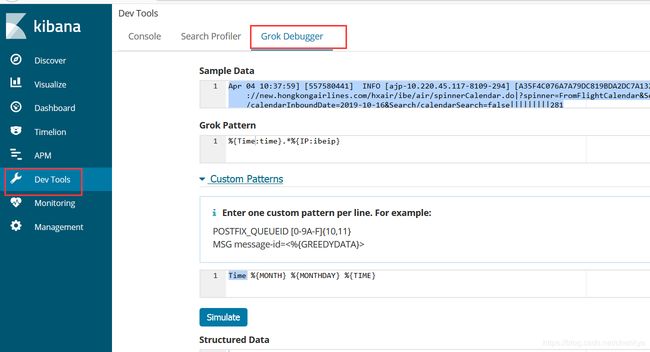
将日志粘贴到Sample Data中,我们就可以在Grok Pattern中通过grok自带的正则参数写正则表达式,点击Simulate来验证写的正则表达式是否能满足我们的需求
我们也可以在Custom Patterns中使用grok自带的正则参数拼接成自定义参数,然后在Simulate中调用自定义的参数来写正则表达式
假如我们要过滤这个日志访问的时间及访问的IP地址
首先我们看一下这个日志的时间及IP地址,时间是Apr 04 10:37:59,中间还有一些我们不想要的参数,后面是我们要的IP地址
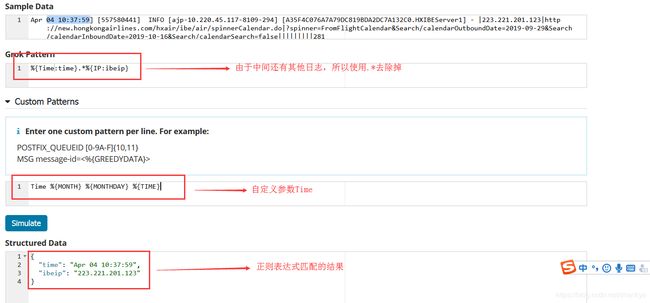
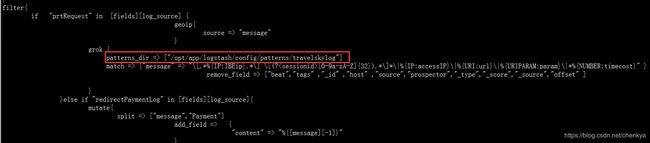
在logstash的filter中也可以写自定义参数,然后使用patterns_dir指向自定义参数的文件,如下图
六、参考文档
由于第一次搭建,本文参考了网上一些比较好的博客并进行了修改,参考的博客如下:
感谢各位博主
https://blog.51cto.com/zero01/2082794
https://www.cnblogs.com/onetwo/p/6059231.html