机器学习工程师福音:超好用的Streamlit简介!
全文共4706字,预计学习时长9分钟
本文将介绍一个机器学习工程师专用的应用程序框架Streamlit。

用300行Python代码中的实时神经网络推理生成语义搜索引擎。
根据自身经验,每一个非平凡机器学习项目最终都布满漏洞,其内部工具均难以维护。这些工具通常是由Jupyter Notebook和Flask应用程序拼凑而成,故很难部署,需要对主从式架构进行推理,并且不能很好地与TensorFlow GPU会话等机器学习架构整合。
卡耐基·梅隆大学、伯克利大学、Google X实验室、Zoox的自动机器人都出现了这一特点。这些工具起初通常是小的Jupyter notebook,包括传感器校准工具,模拟比较应用程序,激光雷达对准应用程序,场景回放工具等等。
工具越来越重要,也就需要项目管理。进程推进,需求也越来越多,这些单独的项目催生了脚本,最后维护将变成人们的噩梦。
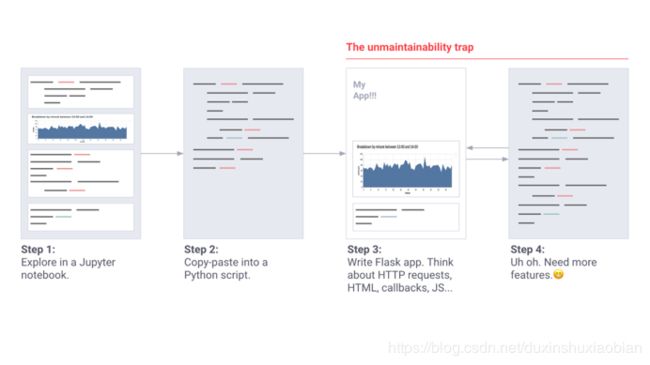 机器学习工程师的特殊应用程序构建流。
机器学习工程师的特殊应用程序构建流。
如果工具成为主角,就需要组建工具团队。他们可以编写绝佳的Vue和React代码,在笔记本电脑上贴满声明性框架的标签。他们有这样的一个设计流程:
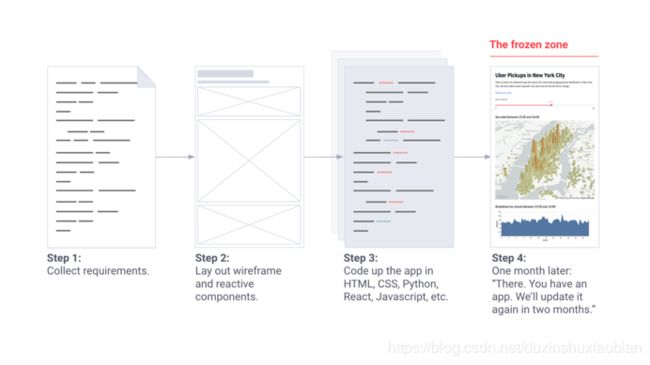
工具团队的电脑保护软件应用程序构建流。
这流程真是太棒了。但是这些工具都需要新性能,比如每周更新。工具团队当时还有另外十个项目,他们会说:“两个月后我们会再次更新你的工具。”
因此需要重新开始构建自己的工具,部署Flask应用程序,编写HTML、CSS和JavaScript代码,并对从笔记本到样式表的所有内容进行版本控制。因此,我和我的Google X老朋友Thiago Teixeira开始思考一个问题:如果可以让构建工具像编写Python脚本一样简单,会怎么样?
我们希望机器学习工程师能够在不需要工具团队的情况下创建极佳的应用程序。这些内部工具应该是机器学习工作流的自然副产物。创建这样的工具应该感觉像是训练一个神经网络或执行一个特殊的Jupyter分析!同时,我们希望保留一个强大应用程序框架应有的灵活性。我们想要创造出工程师们可以炫耀的、漂亮的、高性能的工具。基本上,我们的想法是这样的:

Streamlit应用程序构建流
我们拥有一个绝佳的测试社区,其中包括来自Uber、Twitter、Stitch Fix和Dropbox的工程师,我们花了一年时间为机器学习工程师创建了Streamlit,这是一个完全免费的开源应用程序框架。每一个原型中,Streamlit的核心原理都更加简单纯粹。分别是:
#1: 涵括Python脚本。Streamlit应用程序实际上只是自上而下运行的脚本,没有隐藏状态。可以使用函数调用对代码进行分解。知道如何编写Python脚本,就可以编写Streamlit应用程序。例如,可以输入以下代码:
import streamlit as st
st.write('Hello, world!')

很高兴遇见你
#2:将微件视为变量。Streamlit中没有回调函数!每个交互只是自上而下重新运行脚本。这种方法产生了真正整洁的代码:
import streamlit as st
x = st.slider('x')
st.write(x, 'squared is', x * x)
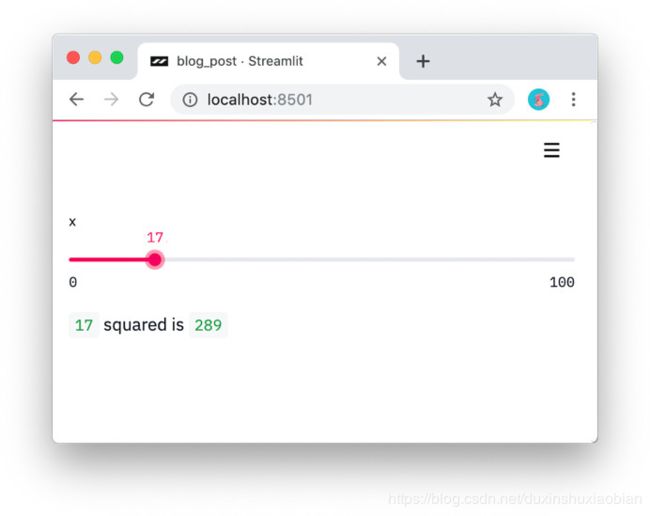
三行代码的交互式Streamlit应用程序。
#3: 重用数据和计算。如果下载了大量数据或执行了复杂的计算怎么办?关键是在运行中安全地重用信息。Streamlit引入了一个缓存原语,它就像一个持久的,默认情况下不变的数据存储区,可以让Streamlit应用程序安全地、轻松地重用信息。例如,此代码仅从Udacity自动驾驶汽车项目(https://github.com/udacity/self-driving-car)下载一次数据,从而生成一个简单快速的应用程序:
import streamlit as st
import pandas as pd
# Reuse this data across runs!
read_and_cache_csv = st.cache(pd.read_csv)
BUCKET = "https://streamlit-self-driving.s3-us-west-2.amazonaws.com/"
data = read_and_cache_csv(BUCKET + "labels.csv.gz", nrows=1000)
desired_label = st.selectbox('Filter to:', ['car', 'truck'])
st.write(data[data.label == desired_label])
使用st.cache在Streamlit运行中持久化数据。若要运行此代码,请按照说明操作::https://gist.github.com/treuille/c633dc8bc86efaa98eb8abe76478aa81
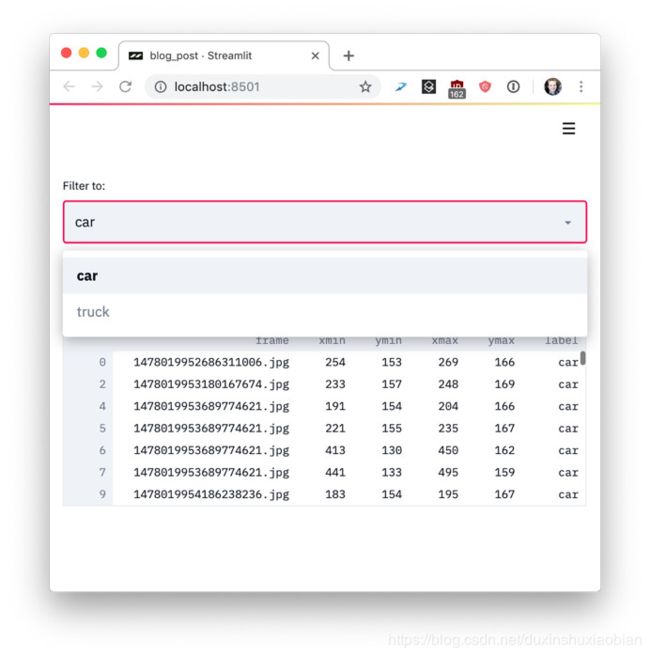
运行上例的st.cache输出。
总而言之,Streamlit是这样工作的:
1. 为每个用户交互从头开始运行整个脚本。
2. Streamlit为每个变量配置指定微件状态的最新值。
3. 缓存允许Streamlit跳过冗余的数据提取和计算步骤。
图示:
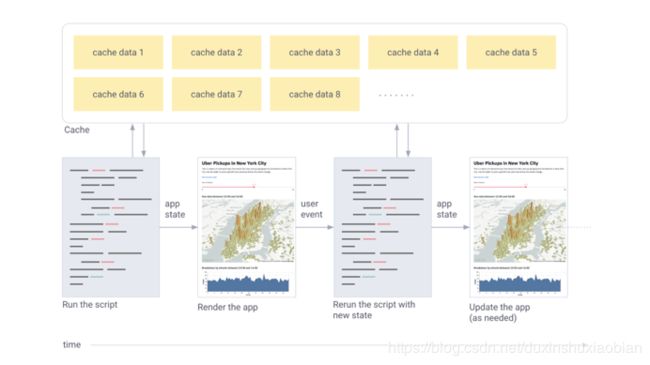
用户事件触发Streamlit从头开始重新运行脚本。只有缓存在整个运行过程中保持不变。
如果听起来不错,现在就可以试试!只需运行:
$ pip install --upgrade streamlit $ streamlit hello
现在可以在浏览器中查看Streamlit应用程序。
本地URL: http://localhost:8501
网络URL: http://10.0.1.29:8501
届时会自动弹出一个链接到本地Streamlit应用程序的Web浏览器。如果没有弹出,就单击链接。
查看更多类似此分形动画的示例,请从命令行运行Streamlit hello。
对于分形还意犹未尽吗吗?这可能很迷人。
这些想法很简单,但并不妨碍使用Streamlit创建非常丰富和有用的应用程序。在Zoox和Google X工作期间,我经历了无人驾驶汽车项目迅速扩充成几千兆字节的视觉数据,这些数据需要搜索和分析,包括在图像上运行模型以比较性能。笔者了解的每一个无人驾驶汽车项目最终都会有整个团队专攻这个工具。
在Streamlit中构建这样的工具很容易。这个Streamlit演示可以在整个Udacity自动驾驶汽车图像数据集中进行语义搜索,可视化基于人工标注的地面实况标记,并在应用程序[1]中实时运行完整的神经网络(YOLO)。
这个300行的Streamlit演示包括语义视觉搜索和交互式神经网络推理。
整个应用程序是一个完全独立的300行Python脚本,其中大部分是机器学习代码。但事实上,整个应用程序中只有23个Streamlit调用。现在就来亲自操作吧!
$ pip install --upgrade streamlit opencv-python $ streamlit run https://raw.githubusercontent.com/streamlit/demo-self- driving/master/app.py
在与机器学习团队合作进行他们的项目时,我们意识到这些简单的想法有许多明显的优势:
Streamlit应用程序是纯Python文件。因此可以同时使用自己最喜欢的编辑器和调试器。
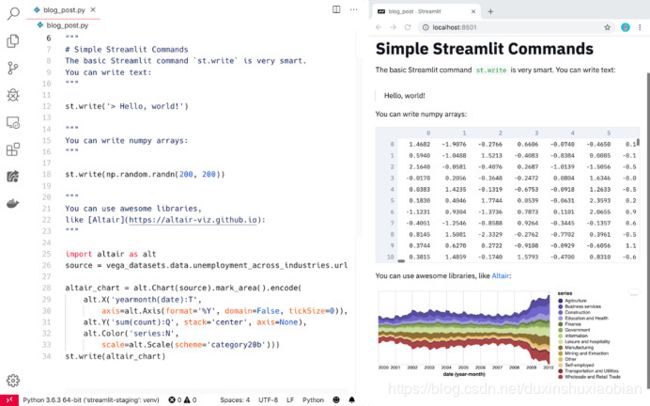
我最喜欢的Streamlit应用程序布局是VSCode(左图)和Chrome(右图)。
纯Python脚本可以与Git以及其他源代码管理软件协同,包括提交、拉拽请求、问题和注释。因为Streamlit的底层语言是纯Python,所以可以免费享受这些协作工具的带来的优质体验。
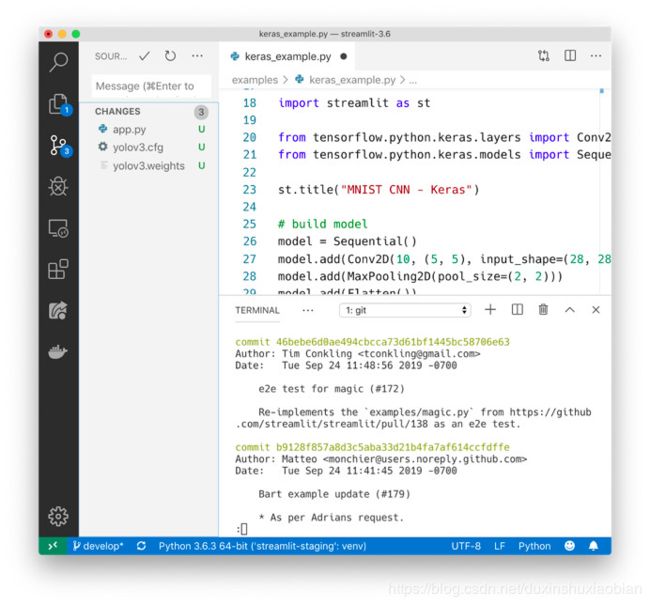
因为Streamlit应用程序只是Python脚本,所以可以使用Git轻松地进行版本控制。
Streamlit提供立即模式实时编码环境。只需在Streamlit检测到源文件更改时单击“始终重新运行”。

单击“始终重新运行”以启用实时编码。
缓存简化了计算流程的设置。令人惊讶的是,链接缓存函数会自动创建高效的计算流程!以下是从Udacity演示中改编的代码:
import streamlit as st
import pandas as pd
@st.cache
def load_metadata():
DATA_URL = "https://streamlit-self-driving.s3-us-west-
2.amazonaws.com/labels.csv.gz"
return pd.read_csv(DATA_URL, nrows=1000)
@st.cache
def create_summary(metadata, summary_type):
one_hot_encoded = pd.get_dummies(metadata[["frame", "label"]],
columns=["label"])
return getattr(one_hot_encoded.groupby(["frame"]), summary_type)()
# Piping one st.cache function into another forms a computation DAG.
summary_type = st.selectbox("Type of summary:", ["sum", "any"])
metadata = load_metadata()
summary = create_summary(metadata, summary_type)
st.write('## Metadata', metadata, '## Summary', summary)
Streamlit中的一个简单计算流程。若要运行此代码,请按照说明操作:https://gist.github.com/treuille/ac7755eb37c63a78fac7dfef89f3517e。
一般的程序是load_metadata→create_summary。每次运行脚本时,Streamlit只重新计算所需流程的任何子集,以获得准确信息。
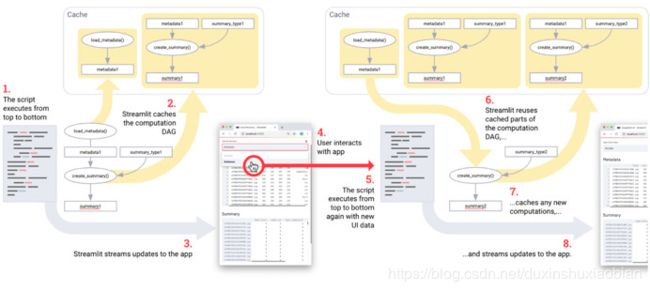
为了提高应用程序的性能,Streamlit只重新计算更新UI所需的一切。
Streamlit是为GPU构建的。Streamlit允许直接访问机器原语(如TensorFlow和Pytorch),并对这些库进行补充。例如,在此演示中,Streamlit的缓存存储了所有英伟达名人的照片GAN[2]。当用户更新滑块时,这种方法几乎可以即时进行推理。

这款Streamlit应用程序演示了英伟达的名人照片GAN[2]模型,该模型使用了关少波的TL-GAN[3]。
Streamlit是一个免费的开源库,而不是一个专营的Web应用程序。可以在不与我们联系的情况下在使用Streamlit应用程序的预置软件,甚至可以在没有互联网连接的笔记本电脑上本地运行Streamlit!此外,现有项目也可以采用Streamlit。
 有几种采用Streamlit的方法。(图标由fullvector / Freepik提供。)
有几种采用Streamlit的方法。(图标由fullvector / Freepik提供。)
这只是对Streamlit功能的一个粗浅的描述。Streamlit最令人兴奋的是如何将这些原语轻松地组合,实现脚本形式的复杂应用程序。
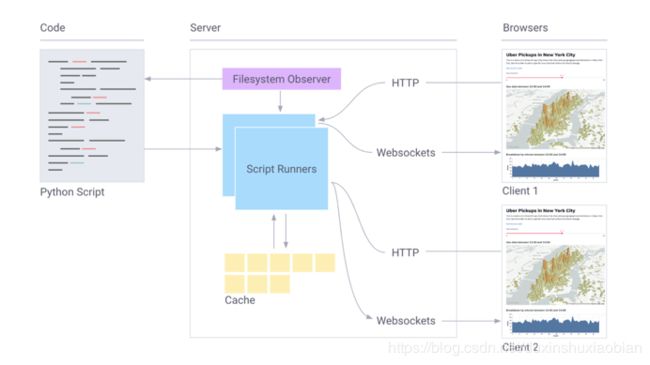
Streamlit组件框图。更多新功能即将上新!

留言 点赞 关注
我们一起分享AI学习与发展的干货
欢迎关注全平台AI垂类自媒体 “读芯术”

加小编微信:dxsxbb,加入读者圈,一起讨论最新鲜的人工智能科技哦~)