唯品会Redis大规模生产实践
很高兴有机会在Redis中国用户组给大家分享redis cluster的生产实践。目前在唯品会主要负责redis/hbase的运维和开发支持工作,也参与工具开发工作。
Outline
一、生产应用场景
二、存储架构演变
三、应用最佳实践
四、运维经验总结
第1、2节:介绍redis cluster在唯品会的生产应用场景,以及存储架构的演变。
第3节:redis cluster的稳定性,应用成熟度,踩到过那些坑,如何解决这些问题?这部分是大家比较关心的内容。
第4节:简单介绍大规模运营的一些经验,包括部署、监控、管理以及redis工具开发。
一、生产应用场景
1、业务范围
redis cluster在唯品会主要应用于后端业务,用作内存存储服务。主要大数据实时推荐/ETL、风控、营销三大业使用。cluster用于取代当前twemproxy三层架构,作为通用的存储架构。redis cluster可以大幅度简化我们的存储架构,也解决twemproxy架构无法在线扩容节点的问题。目前我们在线有生产几十个cluster集群,约2千个instances,单个集群最大达到250+instances。
这是我们的生产应用场景,主要是后端业务的存储,目前没有作为cache使用的场景。
2、大数据、风控、营销系统的特征
-
cluster作为数据量大, 单个cluster集群在几十个GB到上TB级别内存存储量。
-
作为后端应用的存储,数据来源主要以下三种方式:
- Kafka --> Redis Cluster,Storm/Spark实时
- Hive --> Redis Cluster, MapReduce程序
- MySQL --> Redis Cluster,Java/C++程序。
-
数据由离线/实时job生成, 读写请求量大, 对读写性能也要求高。
-
业务高峰期请求量急剧上升,几倍的读写量增加,需要多个redis实例承担业务的读写压力。
-
业务需求变化快, schema变化频繁。如果使用MySQL作为存储,那么将会是频繁的DLL变更,而且需要做online schema change。
-
大促销活动时扩容频繁。
3、为什么选择redis cluster
3.1 cluster适合我们后端生产应用场景
- 在线水平扩展能力,能够解决我们大量的扩容需求。
- Failover能力和高可用性。
- 虽然cluster不保证主从数据强一致性,但是后端业务能够容忍failover后少量的数据丢失。
3.2 架构简单
- 无中心架构,各个节点度等。slave节点提供数据冗余,master节点异常时提升为master。
- 取代twemproxy三层架构,系统复杂性降低。
- 可以节约大量的硬件资源,我们的Lvs + Twemproxy层 使用了近上千台物理机器。
- 少了lvs和twemproxy层,读写性能提升明显。响应时间从100-200us减少到50-100us。
- 系统瓶颈更少。lvs层网卡和pps吞吐量瓶颈;对于请求长度较大的业务,twemproxy单节点性能低。
总结下,我们选择redis cluster主要这两点原因:简单、扩展性。另外,我们用cluster取代twemproxy集群,三层架构实在是很令人头疼,复杂、瓶颈多、管理不方面。
二、存储架构演变
1、架构演变

在2014年7月,为了准备当时的814撒娇节大促销活动,我们把单个redis的服务迁移到twemproxy上。twemproxy在后端快速完成数据分片和扩容。为了避免再次扩容,我们静态分配足够多的资源。
之后,twemproxy暴露出来的系统瓶颈很多,资源使用很多,也存在一定的浪费。我们决定用redis cluster取代这种复杂的三层架构。
redis cluster GA之后,我们就开始上线使用。最初是3.0.2 版本,后面大量使用3.0.3 ,上个月开始使用3.0.7版本。
下面简单对比下两种架构,解析下他们的优缺点。
2、Twemproxy架构
优点
- sharding逻辑对开发透明,读写方式和单个redis一致。
- 可以作为cache和storage的proxy(by auto-eject)。
缺点
- 架构复杂,层次多。包括lvs、twemproxy、redis、sentinel和其控制层程序。
- 管理成本和硬件成本很高。
- 2 * 1Gbps 网卡的lvs机器,最大能支撑140万pps。
- 流量高的系统,proxy节点数和redis个数接近。
- Redis层仍然扩容能力差,预分配足够的redis存储节点。
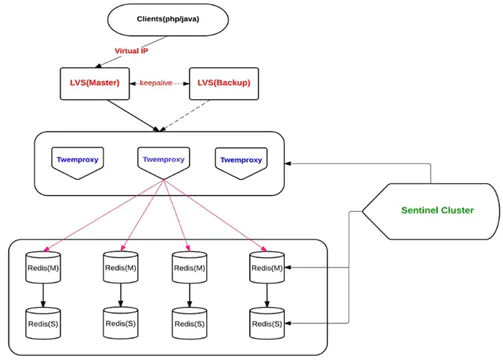
twemproxy.png
这是twemproxy的架构,客户端直接连接最上面的lvs(LB),第二层是同构的twemproxy节点,下面的redis master节点以及热备的slave节点,另外还有独立的sentinel集群和切换控制程序,twemproxy先介绍到这里。
3、Redis Cluster架构
优点
- 无中心 架构。
- 数据按照slot存储分布在多个redis实例上。
- 增加slave做standby数据副本,用于failover,使集群快速恢复。
- 实现故障auto failover。节点之间通过gossip协议交换状态信息;投票机制完成slave到master角色的提升。
- 亦可manual failover,为升级和迁移提供可操作方案。
- 降低硬件成本和运维成本,提高系统的扩展性和可用性。
缺点
- client实现复杂,驱动要求实现smart client,缓存slots mapping信息并及时更新。
- 目前仅JedisCluster相对成熟,异常处理部分还不完善,比如常见的“max redirect exception”。
- 客户端的不成熟,影响应用的稳定性,提高开发难度。
- 节点会因为某些原因发生阻塞(阻塞时间大于clutser-node-timeout),被判断下线。这种failover是没有必要,sentinel也存在这种切换场景。
cluster的架构如下:
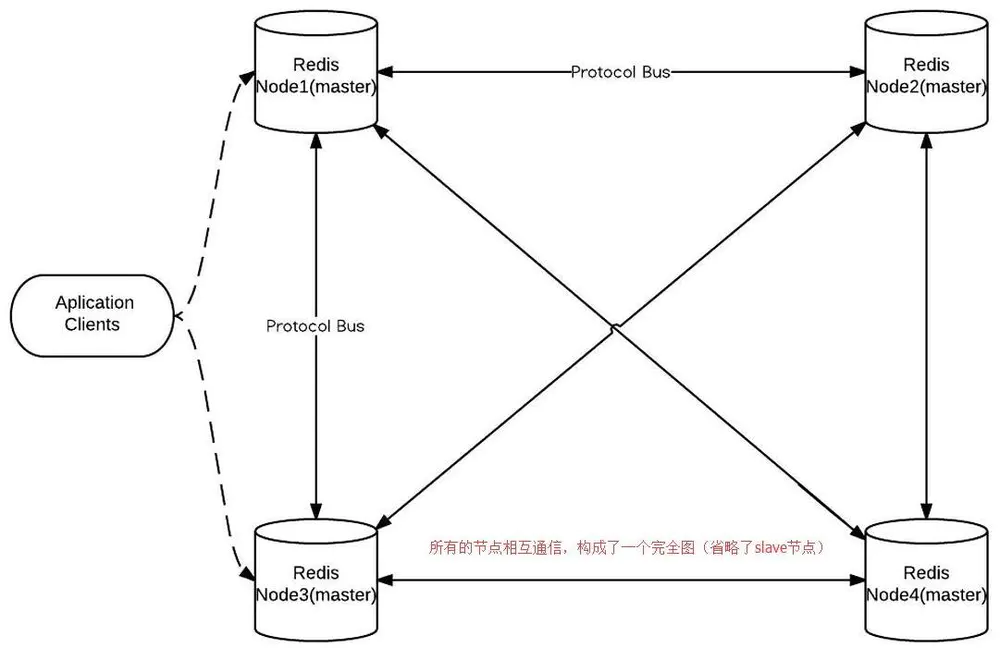
cluster.jpg
图上只有master节点(slave略去),所有节点构成一个完全图,slave节点在集群中与master只有角色和功能的区别。
架构演变讲完了,开始讲第三部分,也是大家最感兴趣的一部分.
三、应用最佳实践
- redis cluster的稳定性如何?
- 存在哪些坑?
- develop guideline & best practice
1、稳定性
- 不扩容时集群非常稳定。
- 扩容resharding时候,早期版本的Jedis端有时会出现“max-redirect”异常。
分析Jedis源码,请求重试次数达到了上限,仍然没有请求成功。两方面分析:redis连接不上?还是集群节点信息不一致? - 存活检测机制缺陷
redis 存活检测机制可能因为master 节点上慢查询、阻塞式命令、或者其它的性能问题导致长时间没有响应,这个节点会认为处于failed状态,并进行切换。这种切换是没必要的。优化策略:
a) 默认的cluster-node-timeout为15s,可以适当增大;
b) 避免使用会引起长时间阻塞的命令,比如save/flushdb等阻塞操作,或者keys pattern这种慢查询。
总体来说,redis cluster已经非常稳定了,但是要注意一些应用中的小问题,下面是5个坑,大家注意了.
2、有哪些坑?
2.1 迁移过程中Jedis“Max Redirect”异常。
- github上讨论的结果是程序retry。
- max redirt issues:https://github.com/xetorthio/jedis/issues/1238
- retry时间应该大于failover 时间。
- Jedis参数优化调整:增大jedis中的‘DEFAULT_MAX_REDIRECTIONS’参数,默认值是5.
- 避免使用multi-keys操作,比如mset/mget. multi-key操作有些客户端没有支持实现。
2.2 长时间阻塞引起的不必要的failover
- 阻塞的命令。比如save/flushall/flushdb
- 慢查询。keys *、大key的操作、O(N)操作
- rename危险操作:
- rename-command FLUSHDB REDIS_FLUSHDB
- rename-command FLUSHALL REDIS_FLUSHALL
- rename-command KEYS REDIS_KEYS
2.3 同时支持ipv4和ipv6侦听服务埋下的坑
具体现象:redis启动正常,节点的协议端口只有ipv6 socket创建正常。异常节点也无法加入到集群中,也无法获取epoch。
解决方法:启动时指定网卡ipv4地址,也可以是0.0.0.0,配置文件中添加:bind 0.0.0.0
这个是在setup集群的时候发生过的一个问题,bind 0.0.0.0虽然存在一些安全性问题,但是是比较简单通用的解决方法。
2.4 数据迁移速度较慢
- 主要使用的redis-trib.rb reshard来完成数据迁移。
- redis-3.0.6版本以前migrate操作是单个key逐一操作。从redis-3.0.6开始,支持单次迁移多个key。
- redis集群内部最多只允许一个slot处于迁移状态,不能并发的迁移slots。
- redis-trib.rb reshard如果执行中断,用redis-trib.rb fix修复集群状态。
2.5 版本选择/升级建议
- 我们已经开始使用3.0.7版本,很多3.2.0修复的bug已经backport到这个版本。
- 另外我们也开始测试3.2.0版本,内存空间优化很大。
- Tips
- redis-trib.rb支持resharding/rebalance,分配权重。
- redis-trib.rb支持从单个redis迁移数据到cluster集群中。
后面2点不算坑把,算是不足,tips也很实用.开始分享下最佳实践。
3、最佳实践
3.1 应用做好容错机制
- 连接或者请求异常,进行连接retry和reconnect。
- 重试时间应该大于cluster-node-time时间
还是强调容错,这个不是针对cluster,所有的应用设计都适用。
3.2 制定开发规范
- 慢查询,进程cpu 100%、客户端请求变慢,甚至超时。
- 避免产生hot-key,导致节点成为系统的短板。
- 避免产生big-key,导致网卡打爆、慢查询。
- TTL, 设置合理的ttl,释放内存。避免大量key在同一时间段过期,虽然redis已经做了很多优化,仍然会导致请求变慢。
- key命名规则。
- 避免使用阻塞操作,不建议使用事务。
�开发规范,使你们的开发按照最优的方式使用nosql。
3.3 优化连接池使用
- 主要避免server端维持大量的连接。
- 合理的连接池大小。
- 合理的心跳检测时间。
- 快速释放使用完的连接。
- Jedis一个连接创建异常问题(fixed):
https://github.com/xetorthio/jedis/issues/1252
连接问题是redis开发使用中最常见的问题,connection timeout/read timeout,还有borrow connection的问题。
3.4 区分redis/twemproxy和cluster的使用
- redis建议使用pipeline和multi-keys操作,减少RTT次数,提高请求效率。
- twemproxy也支持pipeline, 支持部分的multi-key可以操作。
- redis cluster不建议使用pipeline和multi-keys操作,减少max redirect产生的场景。
区分redis 和 cluster的使用,一方面是数据分片引起的;另一方面,与client的实现支持相关。
3.5 几个需要调整的参数
1)设置系统参数vm.overcommit_memory=1,可以避免bgsave/aofrewrite失败。
2)设置timeout值大于0,可以使redis主动释放空闲连接。
3)设置repl-backlog-size 64mb。默认值是1M,当写入量很大时,backlog溢出会导致增量复制不成功。
4)client buffer参数调整
client-output-buffer-limit normal 256mb 128mb 60
client-output-buffer-limit slave 512mb 256mb 180
四、运维经验总结
1、自动化管理
- CMDB管理所有的资源信息。
- Agent方式上报硬软件信息。
- 标准化基础设置。机型、OS内核参数、软件版本。
- Puppet管理和下发标准化的配置文件、公用的任务计划、软件包、运维工具。
- 资源申请自助服务。
2、自动化监控
- zabbix作为主要的监控数据收集工具。
- 开发实时性能dashboard,对开发提供查询。
- 单机部署多个redis,借助于zabbix discovery。
- 开发DB响应时间监控工具Titan。
- 基本思想来源于pt-query-degest,通过分析tcp应答报文产生日志。flume agent + kafka收集,spark实时计算,hbase作为存储。最终得到hotquery/slowquery,request source等性能数据。
3、自动化运维
- 资源申请自助服务化。
- 如果申请合理,一键即可完成cluster集群部署。
能不动手的,就坚决不动手,另外,监控数据对开发开发很重要,让他们了解自己服务性能,有时候开发会更早发现集群的一些异常行为,比如数据不过期这种问题,运维就讲这么多了,后面是干货中的干货,由deep同学开发的几个实用工具。
4、redis开源工具介绍
4.1 redis实时数据迁移工具
1) 在线实时迁移
2) redis/twemproxy/cluster 异构集群之间相互迁移。
3)github:https://github.com/vipshop/redis-migrate-tool
4.2 redis cluster管理工具
1)批量更改集群参数
2)clusterrebalance
3)很多功能,具体看github :
https://github.com/deep011/redis-cluster-tool
4.3 多线程版本Twemproxy
1)大幅度提升单个proxy的吞吐量,线程数可配置。
2)压测情况下,20线程达到50w+qps,最优6线程达到29w。
3)完全兼容twemproxy。
4)github:
https://github.com/vipshop/twemproxies
4.4 在开发的中的多线redis
1)Github:
https://github.com/vipshop/vire
2)欢迎一起参与协作开发,这是我们在开发中的项目,希望大家能够提出好的意见。
问答(陈群和申政解答):
问题1:版本更新,对数据有没有影响?
答:我们重启升级从2.8.17到3.0.3/3.0.7没有任何的异常。3.0到3.2我们目前还没有实际升级操作过。
问题2:请问下sentinel模式下有什么好的读写分离的方法吗
答:我们没有读写分离的使用,读写都在maste;集群太多,管理复杂;此外,我们也做了分片,没有做读写分离的必要;且我们几乎是一主一从节点配置
问题3:redis的fork主要是为了rdb吧,去掉是为了什么呢
答:fork不友好
问题4:如果不用fork,是怎么保证rdb快照是精确的,有其他cow机制么
答:可以通过其他方法,这个还在探究阶段,但目标是不用fork
问题5:就是redis cluster模式下批量操作会有很多问题,可是不批量操作又会降低业务系统的性能
答:确实存在这方面的问题,这方面支持需要客户端的支持,但是jedis的作者也不大愿意支持pipeline或者一些multi key操作。如果是大批量的操作,可以用多线程提高客户端的吞吐量。
转载来源:https://www.jianshu.com/p/ee2aa7fe341b