java8
ch1 java概览
1.java历史和新特性
java自从1998年发布版本1.0后经历了很多次新版本的更新,其中具有里程碑意义的版本是jdk5和jdk8,其中jdk5引入了泛型、增强for循环等对如今开发有着深远影响的特性,随着时代的进步,动态语言中的函数式编程、类型推断等特性越来越流行,为了不被其他动态语言所替代,java必须跟随时代的脚步升级,jdk8便是时代的产物,它首次尝试在静态语言中引入动态语言的特性,可以预见java8将会对未来的java开发产生深远的影响,此次java包含了lambda表达式、stream、optional、默认方法、新日期与时间api等特性。
流处理Stream
java8主要新特性之一,它的思想是将数据看做流,对每个数据依次进行一直多个中间操作,最后生成想要的结果,是对java8以前集合的一种升级,类似于linux中管道命令一样,比如 cat file1.txt | tr | sort | tail 命令,每个命令的输出都是后一个命令的输入,直至最后一个命令产生结果。
行为参数化
java8中引入的一个重要概念,以前java只接受将普通值或对象作为参数传递给方法,现在可以将一个方法作为参数传递给另一个方法,被当做参数的方法也被称为行为,在动态语言中称为函数,函数是动态语言中的一等公民,不需要依托任何类即可存在。
并行
java8以前想要实现并行必须要自己写业务逻辑,手动开启多线程,现在依赖于Stream可以很方便的将执行方法并行化,用户会将stream中每个节点需要做的事情以函数的方式传递过来,stream内部可以通过机制决定开启几个线程同时执行此函数。
2.函数
java中的值
此处的值指的是传递给方法的参数,可以是普通值,比如1.2、"abc"等,也可以是个对象引用,比如ArrayList list, 也可以是匿名函数,本质上也是一个对象。
方法引用作为值
通过类名.静态方法名的方式将方法作为值传递给方法,java8中的写法为File::isHidden,这是java8引入的一种新写法,表达的意思是调用File类中的静态方法isHidden。
lambda(匿名函数)做为值
java8中新引入的lambda本质上就是一个简写的匿名函数,java8提供了一种编写匿名函数更简单的写法,这种写法就叫做lambda,因为匿名函数是java中的值,可以作为参数传递给方法,所以lambda也可以作为参数传递给方法。
例子
普通值和对象引用作为参数进行传递是每个学习java语言的人必会的技能,此处主要看下方法引用和lambda的写法,需求假设需要查找某个目录下所有隐藏的文件
首先是普通的写法:

接着是lambda的写法:

最后是方法引用的写法:

可以看到在此例子中方法引用其实是lambda的一种简写形式。
3.流
外部迭代和内部迭代
用户可以看到的迭代称为外部迭代,比如使用foreach循环遍历集合,在对每个对象进行操作;用户看不到的迭代称为内部迭代,比如stream中的方法,你只需要指定方法即可,stream内部会帮你完成循环并按照你指定的方法处理每个元素。
流对并行的支持
因为stream使用内部迭代的方式遍历元素,因此该如何使用并行提高元素迭代效率在stream内部可以做到完全控制,如果是外部迭代则只能自己在循环中开启并分配线程,难度极大。
4.默认方法
默认方法出现的原因
java8新增了stream的概念,stream是对集合的一种增强,创建流的其中一个方式是list.stream(),但是这种方式存在一个问题,原先的设计中并没有考虑到后续版本会使用此方法,因此并没有提供该方法,现在java8为了让所有的集合都可以使用此方法,则必须将该方法加入到List接口中,这样做会导致所有实现了java集合的类都必须实现此方法,这种方式并不可以保持兼容性,因此提出了默认方法的概念,即通过default关键字在接口中实现该方法,不需要实现类做任何改动便可以使用stream方法。
5.函数式编程的新思想
Optional
java以前的版本存在一个很重大的设计失误,该设计因为使用方便而没有修正,此设计是null,即经常遇到的NPE问题,java8决定修正该失误,因此它提供了Optional类,该对象会包含所有的值,包括普通值、对象引用等等,你可以通过调用它的get方法获取包含的值,如果此值为空可以强迫用户处理值不存在的问题,不会出现NPE问题了。
模式匹配
模式匹配可以看做是switch的一种扩展形式,是动态语言中特有的概念,对java的设计产生了一些影响。
ch2 行为参数化
本章主要讲了行为参数化的概念以及如何使用它,将筛选苹果的需求作为例子进行实践
1.行为参数化的含义和使用
首先要搞清楚行为的含义,简单来说行为=方法=函数,行为参数化指的就是将一个方法或函数作为参数传递给另一个方法,假设现在要根据颜色筛选苹果,首先假设需要找出所有绿苹果:
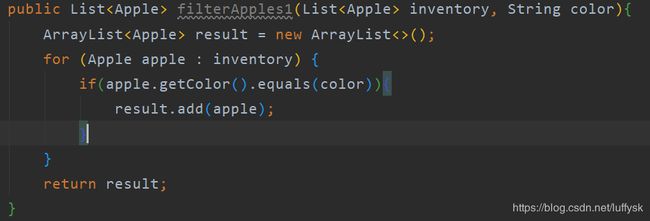
通过调用此方法,指定color等于blue即可实现,此时需求变了,要求筛选出所有红色的苹果,那么你需要将color改变为red来完成,到目前为止一切开起来都很美好,此时需求又变了,要求筛选出所有重量大于100的苹果,此时用此方法就没办法实现了,必须重新写一个实现方法:

通过调用此方法,指定weight为100即可实现,假设现在需求又又又又变了,需要筛选所有产地为北京的苹果,用户当前可以在写一个方法,通过参数的方式将产地传入,假设需求想要即是红色由大于100的苹果怎么办,总不可能在写一个方法吧,为了解决这个问题,java8引入了行为参数化的概念。
通过上面的方法可以发现需求中总是在变的只有输入的参数和具体的判断逻辑不同,因此我们可以将判断逻辑抽象为一个方法,该方法存在于接口中,参数即为遍历中的对象类型,具体的判断逻辑由实现类编写,抽象以后的代码就会变为这样:
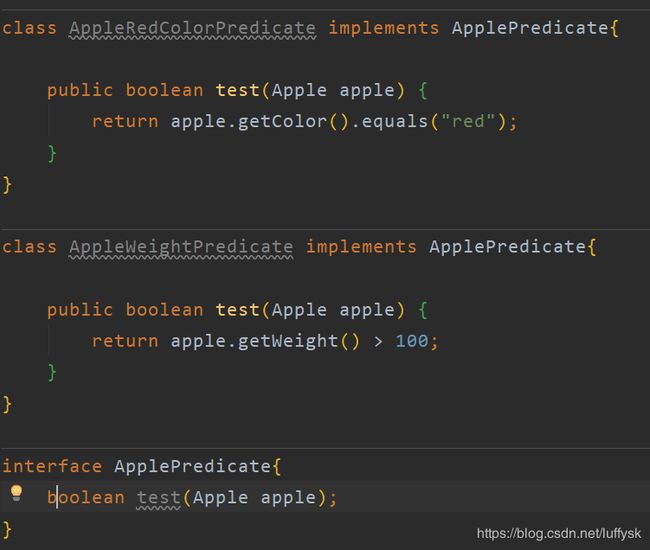
每个条件被抽象为了一个类,这些类实现了同一个接口,此时用于过滤的方法便可写为:

此方法写好以后可以进行复用,比如此时要实现筛选颜色为red且重量大于100的苹果,只需创建一个类实现接口中的方法,在该方法中编写具体的判断逻辑即可,筛选方法完全不需要做改变,具体实现类中的test方法即称为一种行为,我们通过将行为包装在接口中传递给方法从而实现了行为的参数化。
2.和策略模式的联系
上面这种方式和策略模式非常相似,筛选方法只要面向ApplePredicate接口即可,我们可以实现多个该接口的实现类,具体使用哪个依赖于所传入的具体实现类,实际上这既是策略模式的一种实现。
3.实现自定义的行为参数化例子
假设现在需要按照不同格式打印每个苹果的属性,重新设计一个接口:
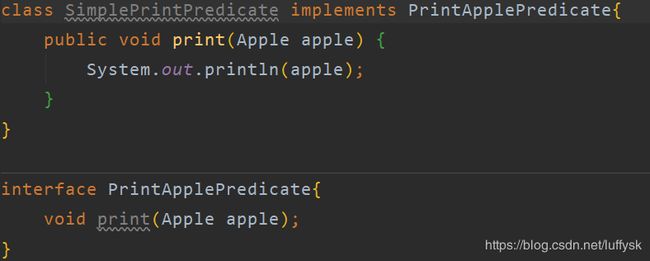
可以通过实现该接口定义不同的打印方式,使用该接口的方式同filterApple一样,只需要将接口和调用的方法换掉即可。
4.减少代码量,使用匿名类重写
到目前为止功能已经实现了,但是为每一个需求编写一个实现类然后将它传入到方法中太麻烦了,我们可以使用java提供的匿名类减少代码量:
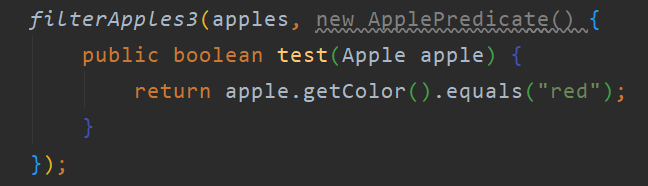
可以看到使用匿名类的方式调用我们不必在编写实现类了,代码简化了很多。
5.再进一步,使用Lambda重写
使用匿名类优点过于笨重,而且不够友好,因此java8提供了lambda取代匿名类,将上面的例子使用lambda重写:

可以看到使用lambda相比之前的代码简化了非常多。
6.继续抽象
如果将上面的filterApple方法和接口继续抽象,将Apple替换为泛型T,则此套路可以用作任何类型的筛选,此接口和方法即是java8内置的filter方法和Predicate方法,实现原理同上面例子一样。
ch3 lambda
1.lambda是什么和它的作用
通过前面的介绍可以很清楚的知道lambda实际上是匿名函数的一种简写形式,使用lambda可以使得代码变得更加精简,它非常适合用来表示 ‘将行为传递给方法参数’ 这个概念。
2.lambda的组成
既然lambda本质上是一个匿名函数,那么它的定义和普通方法类似,lambda主要由参数列表,箭头符号,方法体组成
具体表示为(parameter) -> expression 或者 (parameter) -> {statement;}
如果不带花括号一定是一个表达式不可以是语句,因为lambda默认会将最后执行的代码的结果作为返回值返回(借鉴scala语言的思想)。
3.lambda的使用位置
我们可以使用匿名函数是因为在接口中定义了那个方法,如果接口中没有对应的方法,那么匿名函数也就不会存在,同样的道理,现在lanmbda代表了匿名函数,那么一定有一个接口声明了lambda代表的抽象函数,就像在前面抽象出来的ApplePredicate接口一样,只有在接口中声明了test方法,我们才可以使用lambda的方式为test方法编写实现行为
函数式接口
为了区分普通接口和lambda所使用的接口,java8引入了一个新注解@FunctionalInterface,被该注解标记的接口称为函数式接口,如果是函数式接口,那么就应该满足指定的规则:接口中只有一个抽象方法(没有参数或通过继承导致存在多个方法的接口都不符合要求)。
函数描述符
和方法描述符类似,因为lambda没有名字,为了更清楚的区分各个函数式接口中的抽象方法,为lambda定义一种描述符,比如()-> {} lambda表达式可以表示为 ()-> void,即代表其不接受任何参数,不返回任何值,前面定义的ApplePredicate接口中的test方法的lambda实现可表示为(Apple)-> boolean,即接收一个Apple对象,返回一个boolean值
4.lambda使用示例
以处理文件为例
初始实现:
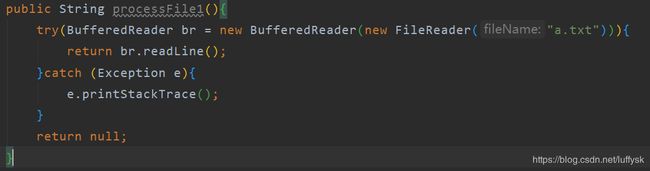
此时读取一行没问题,如果想要读取两行呢,三行呢,每行中间加数字呢,总不可能每次都写一大堆重复的代码吧,此时就要使用lambda把变化的行为抽取出来作为参数传递
首先确认参数,在这个方法里我们只需要别人传入br对象引用,然后调用readLine方法即可,因此参数即为BufferedReader br
其次确定返回值,此方法需要返回一个String对象,由此可以得到lambda的函数描述符:(BufferedReader)-> String
函数实现已经确定了,接着就要把它和函数式接口关联起来,只有在使用该函数式接口作为参数的地方才可以将此lambda的实现作为参数传入方法
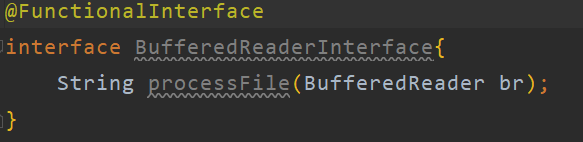
定义一个函数式接口,起名为BufferedReaderInterface,其中的抽象方法为processFile
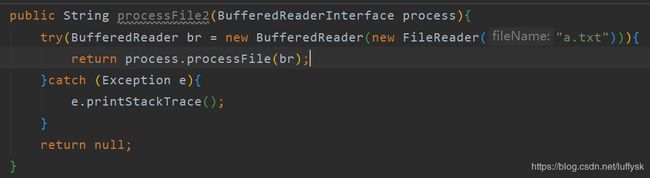
接着编写该lambda的通用方法,在此方法中将具体行为转交给lambda表达式实现
接着就可以给这个通用方法传递任意符合类型的lambda表达式了,具体实现行为由自己决定
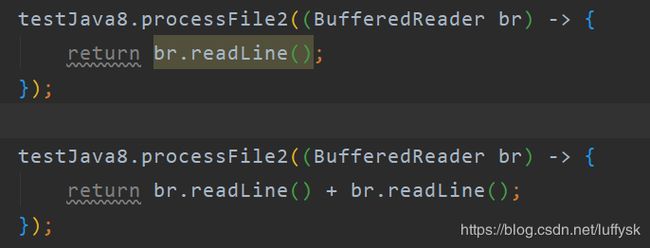
此处的br对象是由通用方法传递过来的。
5.java8自带的函数式接口
通过前面可以看出如果要使用lambda表达式则必须先定义函数式接口,声明唯一的抽象方法才行,为了方便java开发人员编写lambda,设计者们抽象出来多个行为,并定义好了这些行为的函数式接口,因此只要是以这些接口作为参数的地方就可以直接编写lambda表达式了,这些接口称为java内置的函数式接口
Predicate
此接口中方法对应的函数描述符为T -> boolean, 正如前面的例子中传入一个Apple对象返回结果为true或者false
Consumer
此接口就像消费者一样,它的函数描述符为T -> void, 即传入T类型对象,不返回值,传入的对象被它消费了
Function
此接口和数学中的函数类似,它的函数描述符为 T -> R, 即传入T类型对象,返回R类型对象
原始类型和引用类型的函数式接口
这种类型的函数式接口本质上和前三种一样,唯一的区别在于它们的类型为引用类型或原始类型,比如IntPredicate代表传入int值,返回boolean值,其他的和此类似,提供这些接口的目的是因为使用这些接口可以避免拆箱和装箱操作
java提供的所有函数式接口列表

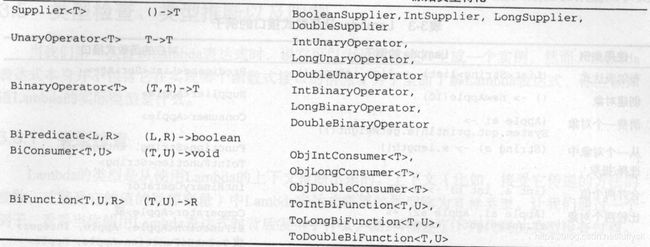
如果java提供的不能满足需求,那么可以自己重新实现
6.类型检查、推断和限制
首先要明确一点,讨论lambda是在特定的上下文中讨论的,因为一个lambda表达式可以对应多个函数式接口,只有先确定了函数式接口,才有类型检查和推断的问题
使用ApplePredicate举例来说,该接口中唯一的抽象方法需要的参数为Apple对象,如果对应的lambda表达式的参数不是Apple,那么java就会抛出异常
类型推断指的是在lambda中你不需要显示的声明参数的类型,因为lambda只可能对应一个函数式接口中的一个抽象方法,因此当你不写参数类型时java会根据抽象方法的参数类型确定lambda参数的类型
lambda中的限制和匿名函数一样,即函数中只能使用被final修饰的外部变量
7.方法引用
方法引用的含义、写法和作用
方法引用是java8新提出来的概念,目的是简化lambda的代码,它使用 类名或对象引用名::方法或关键字 表示,它只适合简化那种函数体内只有一行代码,并且是调用其他方法的lambda,比如(Apple a) -> a.getWeight() 可以简写为 Apple::getWeight
方法引用的三种分类
分为静态方法引用, 写法为 类名::静态方法名
参数类型实例方法引用, 写法为 参数类型所对应的类::参数类型所对应的类中的实例方法
对象实例方法引用, 写法为 变量名::变量对应的对象中的实例方法名
用一幅图总结:

构造函数引用
写法为 类名::new,它返回的是类名所对应的新对象,对应函数式接口的函数描述符为()-> T, 对应java提供的Supplier函数接口
8.表达式复用
在java提供的函数式接口中除了提供一个抽象方法外还提供了多个默认方法,这些方法的作用就是复用表达式,比如and方法,接收一个Predicate返回一个Predicate,那么只有在两个lambda都为true时才会返回true,还有andThen和compose,假设调用关系是f.andThen(g)和f.compose(g),则类似于数学中的g(f(x))和f(g(x)),即哪个先执行哪个后执行的问题
ch4 流的介绍
1.流带来的好处
流可以使开发者更方便的处理集合,它可以看做集合的一种增强,使用了lambda中行为参数化的思想,将对集合中元素的行为抽取为各种类型的抽象方法,底层类库只需要编写通用的实现,具体对集合中元素的处理操作由lambda表达式决定,因此流的出现改变了以前只能以命令的方式操作集合,使用流可以通过声明式编程操作集合,因为通用的方法由jdk底层提供,与用户完全解耦,因此jdk可以很方便的在处理流时使用并行化
2.流的定义
标准定义是:从支持数据处理操作的源生成的元素序列
由定义可知流是由多个元素组成的元素序列,而元素是来自于各种可以处理数据的容器,比如ArrayList、数组对象等等,每一种容器java8都为其提供了转换为流的默认方法
流在处理数据时具有流水线和内部迭代的特性
具体使用示例如下:
首先定义Dish类
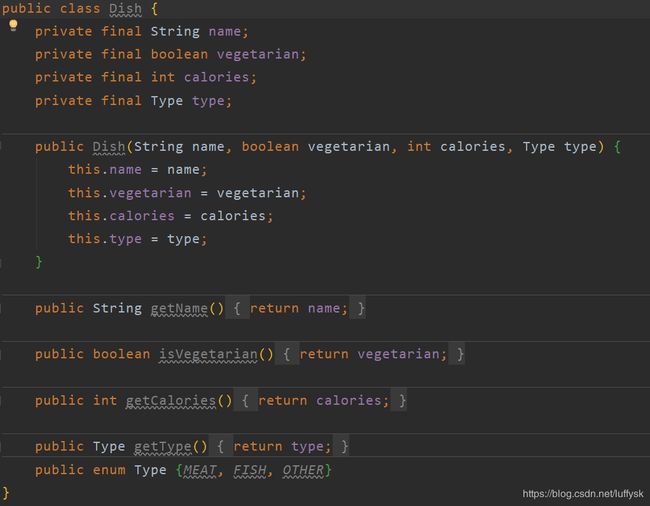
构造数据

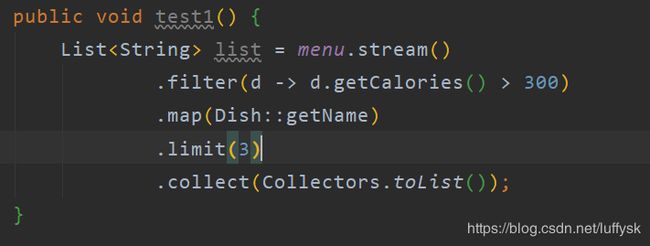
这个方法做的操作是获取食物列表中卡路里大于300的食物,只取前三条记录的名字,如果使用传统的方式实现需要很多行代码,由此可以看到流对集合能力的扩展效果
3.流的特性
遍历一次
将集合或容器转为流以后只能使用一次,就像menu.stream() 一样,调用该方法会生成一个代表流的Steam对象,当collect方法执行完毕后该对象便消失了,如果想重新使用此流对象,则必须重新调用menu.stream() 方法,因此说流只能遍历一次
外部迭代和内部迭代
外部迭代指的是用户可以看到迭代语句的迭代过程,内部迭代指的是用户看不到迭代语句的迭代过程
比如使用Iterator遍历时就是外部迭代,因为必须手动调用hasNext方法进行判断,而foreach语句也是外部迭代
stream为内部迭代,因为用户只需要指定流中每个元素需要执行的操作,Stream内部会挨个遍历元素并执行相应的操作,对用户完全透明

4.流定义的操作
流内置了很多方法(操作),根据对元素序列的影响主要分为中间操作和终端操作
中间操作
这类方法不会导致流开始收集元素,流只有在遇到终端操作时才会开始执行方法并生成结果,中间方法具有延迟特性,每个中间操作返回的都是Stream对象
终端操作
顾名思义,终端操作就是使流结束的方法,当指定终端方法后流就会开始遍历元素序列,依次执行中间操作,最后通过终端操作返回计算后的结果,之后该流对象便会被回收
使用流
有上面可知,流的使用有三部分组成:数据源、中间操作、终端操作,流的这种使用方式类似于构建器模式
ch5 流的用法
和lambda的函数式接口类似,java也为通用的集合处理操作封装了一系列方法,只有在详细理解了这些方法的作用之后才可以正确的使用它们
1.中间操作方法之筛选和切片
filter
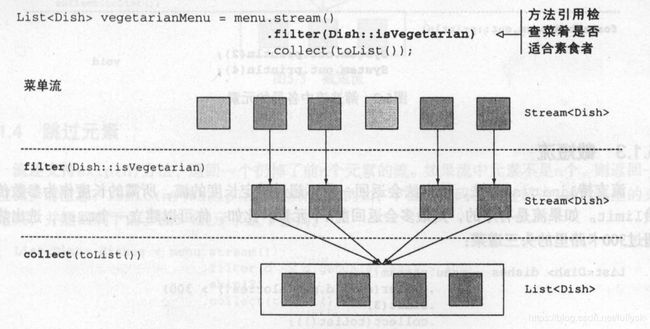
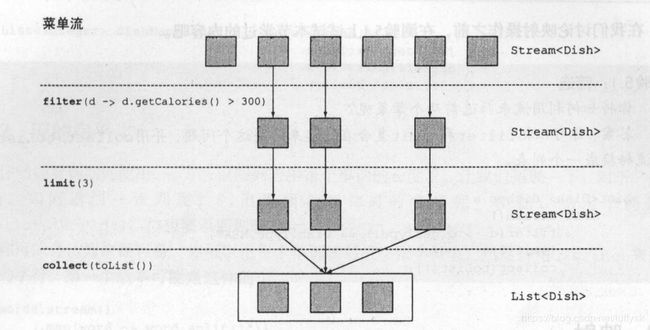
filter方法的作用是过滤数据,它的参数是Predicate predicate,函数描述符为 T -> boolean,大概的实现流程为Stream遍历元素,调用每个元素的predicate,该参数是由用户指定的lambda表达式,如果返回结果为true,则将其加入下一个处理流中,如果为false,则过滤掉该元素

执行流程为:
distinct
distinct方法的作用是去除流中重复的元素,它的判断依据是hashcode和equals方法


limit
limit方法的作用是获取前n个元素,其中n由用户指定
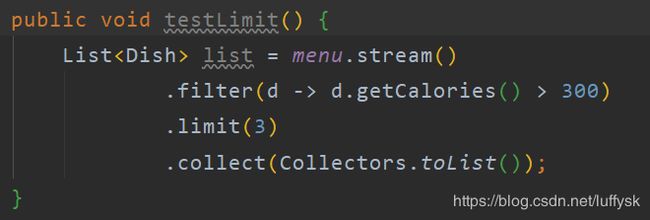
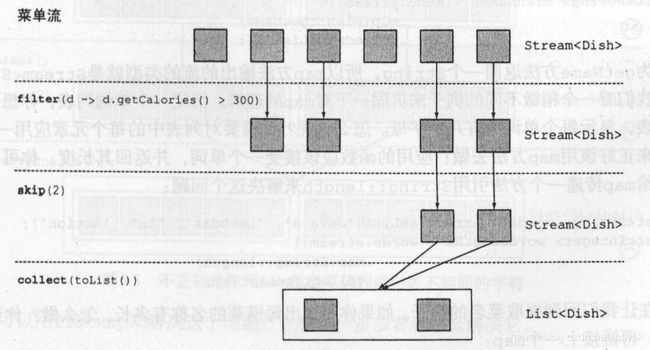
skip
skip方法的作用是跳过指定个数的元素

2.中间操作方法之映射
map
map方法的作用是将元素映射为另一种类型,就像前面获取菜名一样,本来集合中存放的是Dish类型对象,但是最后生成的却变成了String类型对象,因为给map中传入了Dish::getName
flatmap
flatmap方法和map类似,只不过它是在映射的同时将多个流压成一个流输出,即首先通过map方法向值映射为流,然后将多个流输出到同一个流中返回
3.终端操作方法之查找和匹配
anyMatch
anyMatch方法接收的参数和filter方法一样,它的作用是在经过中间操作后的流中应用指定的lambda行为,只要流中有一个满足条件则返回true
allMatch
allMatch方法和anyMatch方法类似,只有流中所有的元素都满足指定条件后才返回true
noneMatch
noneMatch方法可以看做allMatch方法的反义词,即只有流中所有的元素都不满足指定条件时返回true
findAny
findAny方法的作用是在流中随意找一个元素返回, 该返回类型为Optional,即有可能找到也有可能找不到,避免空指针异常
findFirst
findFirst方法查找流中的第一个元素并返回,返回类型为Optional
4.终端操作方法之求和
reduce
reduce方法的作用是对元素进行一些归约操作,归约操作的含义是指在流生成的元素上执行一些查询或操作,然后返回执行后的结果
首先介绍它两个参数的方法,第一个参数为初始值,第二个参数为BinaryOperator类型的lambda表达式,它的大概含义是依次遍历元素,以初始值作为基础,将每个元素和初始值传入lambda中,然后将计算的结果作为下一次lambda的参数,最后返回计算结果
使用reduce进行累计求和的执行流程如下
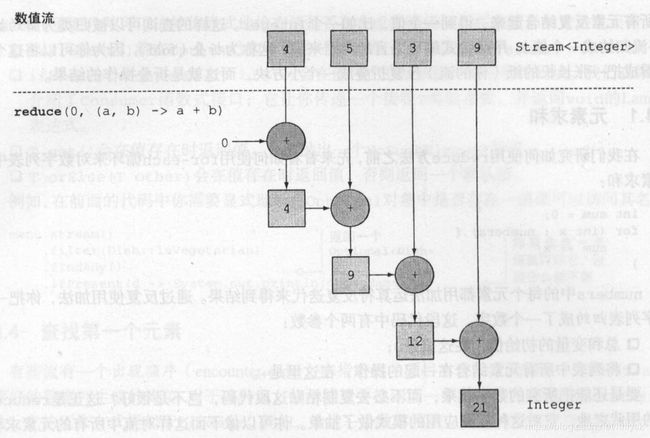
reduce还有一个只接受一个参数的方法,该方法的返回值为Optional,使用该方法还可以实现最大值和最小值的计算
无状态和有状态
无状态指操作不需要依赖历史生成的结果即可进行,比如map和filter
有状态指操作必须依赖历史生成的结果才可进行,比如sort和count
目前为止接触到的所有stream方法
5.数值流
出现的意义
为了避免流中每次拆箱和装箱的性能损耗,java定义了专门用于处理普通类型的流
特化流
该流的方法和普通流中的方法类似,只是在每个方法后添加To基本类型
特化流转为普通流
需要转换时只要调用boxed方法即可
6.生成流的方式
从前面已经了解了流的使用方式和常见的一些方法,本节主要讲解如何创建流,流本质上是一个个元素组成的元素序列,因此只要对象的内容满足此定义就可以通过方法转为流,java8提供了5种流的来源
集合
在java8中为集合接口添加了一个stream的默认方法,通过此方法可以将集合中的元素转为流
值
最典型的应用是通过Arrays的静态方法asList指定多个元素生成集合,然后调用集合的stream方法
数组
java8给Arrays提供了stream方法
文件
Files中的静态方法list、lines等都可以将文件转为流
函数
调用Stream的静态方法iterate可以生成无限流
ch6 收集数据
1.收集器的作用
收集器collect可以看做是reduce的一种扩展,使用reduce时只能做求最大值、最小值、计算总和等简单的数据操作,而collect支持分区、分组、排序和各种汇总函数等功能
2.归约和汇总
归约和汇总函数的种类和使用方式
java8提供的collect功能放在了Collectors类里,比如toList、toMap、groupingBy等方法,这些方法大致可以分为三类:将流元素归约和汇总为一个值、元素分区、元素分组
基本使用方式为:集合容器.stream().多个中间方法.collect(Collectors.指定的函数)
比如求最大值的方法maxBy,它会接受一个比较器,最后返回集合中指定值最大的那个对象

其他的方法都是类似的,唯一的不同就是它们的参数根据方法的定义而改变
归约和汇总函数的本质实现
上面介绍的Collectors中的各种归约方法其实都是Collectors.reducing()方法的特殊实现,只是用来方便使用的,底层都是通过reducing实现的
3.分组
顾名思义,就是将流中的数据按照指定的方式分成多组,最后返回分组后的map集合,它允许进行多级分组和统计
4.分区
和分组的区别
如果分组的参数改为Predicate,那么此时就是分区了,因此分区为接受一个谓词,将流中结果为true的分为一组,为false的分为另一组,最后返回的也是一个map,它也允许进行多级分区
Collectors方法列表

5.Collector
Collector是一个接口,其中有五个方法,它是所有归约和汇总方法的抽象,通过实现它的方法可以定义自己的收集器,Collectors中通过静态内部类的方式实现该接口
函数介绍
实现toList方法
6.自定义收集器
需要先理解Collector接口中每个方法的作用才可以自定义收集器
ch7 在流中使用并行
1.并行流
将顺序流转为并行流的方式
因为流使用的内部迭代的方式,因此在流中使用并行非常简单,只需要将转为流的方法stream替换为parallelStream即可,或者调用parallel方法
顺序流和并行流性能测试
并不是说使用并行的方式一定比串行快,有时因为任务难以分割、装箱和拆箱等因素会导致并行比串行还慢,因此在正确的地方使用并行是很有必要的
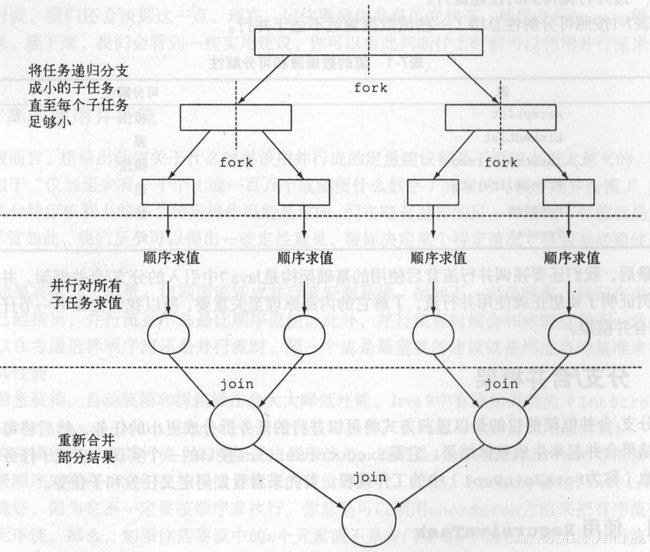
2.fork/join框架
fork、join原理
如同名字一样,该框架首先将任务fork,即将任务拆分成多个最小单元,然后使用并行执行各个单元,最后将执行结果通过join收集起来,充分利用多处理器的优势提高运算速度
工作窃取
在将任务分为多个小任务后,由于每个处理器处理速度可能不同,就会出现1号处理器已经处理完任务了,2号、3号、4号处理器还有任务没有处理完成,此时1号处理器就会帮助任务堆积最多个处理器共同处理任务,为了不发生冲突,它会从任务队列的尾部获取任务,这种方式就像偷走任务一样,因此称为工作窃取
3.流拆分机制Spliterator
作用
当使用并行方式时指定流该如何切分任务,比如流中序号为奇数的分为一组、序号为偶数的分为一组等等,而Spliterator就是java对这些拆分机制的一种抽象
接口方法介绍
接口中最重要的方法即为 trySplit(),它定义了具体的拆分规则,它返回的还是Spliterator,因此可以继续调用trySplit方法进行切分直至返回null,此时代表已经不可再分
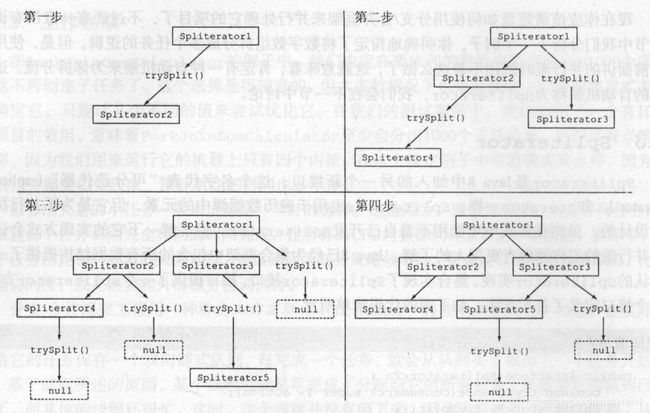
自定义拆分类
只需要实现Spliterator接口,实现其中的方法即可,它除了由trySplit之外,还提供了一些辅助方法
ch8 重构、测试和调试

ch9 默认方法
1.默认方法出现的原因
思考一个很实际的问题,比如将ArrayList转换为Stream的方式为调用stream方法,但是在java8以前集合中并没有定义stream方法,如果将该方法加入集合类中,那么用户实现的所有集合类都要重新实现stream方法, 这导致java8不具备向前兼容的特性,此时默认方法就出现了,它允许在接口中实现方法,通过将方法标记为default即可,这样接口的实现类不需要做任何改动就可以使用该方法了
2.默认方法的定义
默认方法和普通方法有着同样的定义,唯一的区别是它的标识符为default,并且只能写在接口里
3.默认方法带来的问题及解决方式
如果在多个接口中定义了同名的默认方法,比如A接口定义了stream默认方法,B接口也定义了stream方法,同时它继承A接口,此时C类实现了A、B接口并调用stream方法,那么根据就近原则它调用的是B接口的stream方法,如果向明确的调用A接口中的stream方法,可以使用A.super.stream的方式调用
如果出现了C++中菱形继承的调用方式,那么编译器会报错,你必须通过A.super.stream的方式手动指定调用哪个接口中的方法
ch10 Optional
1.Optional出现的原因
Optional类最主要的作用就是用来避免空指针异常,在java8中当返回对象时不是直接返回对象,而是返回一个Optional类,该类中包含了返回的对象,这样做的好处是如果用户需要获取返回的对象,那么必须手动的调用方法进行获取,此时就必须考虑该值为空的情况

2.Optional类


3.创建Optional对象的方式
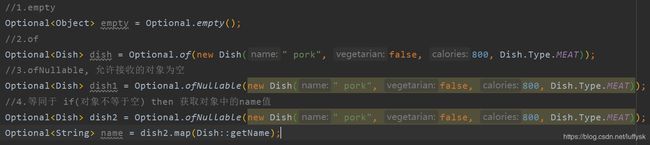
使用Optional的方式是如果某个值可能为空,那么使用ofNullalbe的方式将它包装成Optional,比如在map中根据键获取值时: Optional.ofNullable(map.get(key))
ch11 CompletableFuture
1.Future接口
Future代表了任务执行时将来会生成的结果,executorService执行后会返回该对象,通过该接口可以实现异步的操作,只有在需要获取任务执行的结果时调用get方法才会阻塞当前线程

2.CompletableFuture
completableFuture是java8对Future的一种增强,它使用了java8中的新概念提供了比Future更多的特性,包括异常管理机制、将多个异步任务合并为一个等等
3.completion事件
在completableFuture中注册了该事件后,当任务执行完毕或者结果可用时会回调注册的方法,由此用户可以不需要等待直接获取到执行结果
ch12 日期和时间
java8提供了一套全新的日期和时间API,解决了以前版本中遗留的问题
1.日期和时间间隔
LocalDate、LocalTime、LocalDateTime
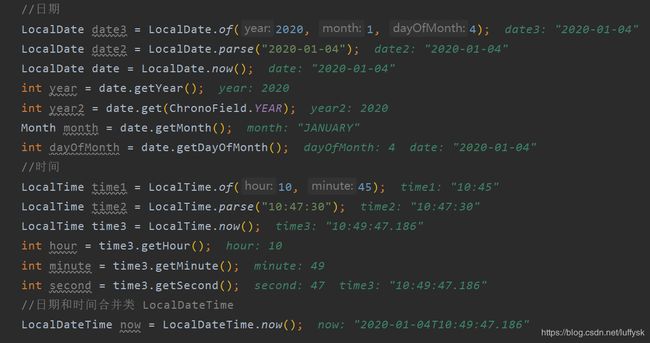
Duration、Period
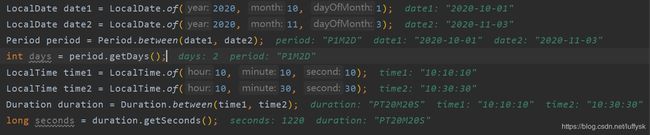
通用方法
表示日期或时间间隔
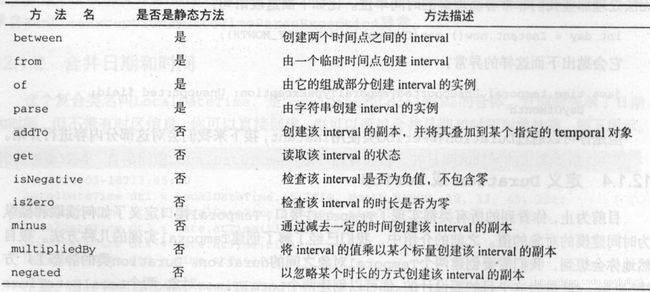
表示日期或时间点

2.日期操作
TemporalAdjuster
主要用来获取各种需求的日期,它是一个接口,如果提供的方法不能满足要求,可以自己提供专门的实现类
3.时间操作
主要改动是通过ZoneId替换了TimeZone,可以处理不同的时区, 还提供了4中其他的日历系统