面试记录与知识点复习20180814
电话面试与知识点复习:20180813
目录:
- 在线分屏编程:写一个函数判断一个单向列表是否有环?(进一步问环的入口)。
- 数据结构:哈希表:冲突处理有哪几种方法?其中链地址法有什么缺点吗?怎么改进?
- linux的IO多路复用知道吗?(貌似很爱考)select、poll方法?参考圣经:APUE
- linux 调试工具GDB用过吗?(gg:上次是腾讯的问过!,至少要去看了记住啊!)
- C++程序的内存模型怎样?(常考!)
- 接着问内存:堆栈的区别?new/delete 与C的malloc()/free()的区别?delete与delete[]的区别?(老生常谈!)
-
好了来个新生常态:在多线程编程中,一个进程中的各个子线程可以共享堆区中分配的内存空间吗?
- 操作系统:内存:怎么从逻辑地址映射到物理地址?
- 网络:详细问TCP的连接建立和断开!三次握手四次挥手!!各个阶段各个状态都要记住!如果连接双方都请求断开连接是怎么一个过程?
- linux网络编程中的accept()系统调用是TCP三次握手连接的哪一个阶段???
- 语言基础:指针与引用的区别?
- 在线分屏编程:写一个函数判断一个单向链表是否有环?(进一步问环的入口)。
用的是Eclipse Che:一个云IDE,linux下的g++编译语句要会,简单的MakeFile文件要看得懂!
如编译hello.cc的MakeFile文件:
all:
g++ -g hello.cc
g++的几个编译选项:
-o:指定生成可执行文件的名称。使用方法为:g++ -o outFile.o sourceFile.cpp file.h ... (可执行文件不可与待编译或链接文件同名,否则会生成相应可执行文件且覆盖原编译或链接文件),如果不使用-o选项,则会生成默认可执行文件a.out。
-c:只编译不链接,只生成目标文件。
-g:添加gdb调试选项。
判断单向列表是否有环:
1.链表结点类型的定义:(要写得规范!)
//预定义常量则用
#define TRUE 1
#define FALSE 0
#define OK 1
typedef int ElemType;
//注意定义新的用户自定义类型是用typedef
typedef struct LNode{
ElemType data;
struct LNode* next;
}LNode,*Linklist;
/*这里用C结构体的方式定义了节点类型LNode,
和指向节点的指针类型LinkList.*/C知识点:
用typedef声明新的类型名
typedef的两个用处:
1.简单地用一个新的类型名代替原有的类型名
typedef int Integer;
typedef float Real;这里用Integer代表int类型,用Real代表float类型!
所有下面两行代码等价:
int i,j; float a,b;
Integer i,j; Real a,b;先看一下下面这堆复杂的难以区分的C语言的概念:
float* PointerArray[10];//指针数组:每个元素存一个float* 指针
float floatArray[10];
float(*ArrayPointer)[10];/*指向一个含有10个float元素的一维度数组的数组指针。
相当于是一个行指针:指向整个数组,而不是列指针(指向数组的某个元素)*/
ArrayPointer = &floatArray;
double* func(double*);//函数声明;
double(*functionalPointer)(double*);//functionalPointer是函数指针!
int*(*(*PointerTo_functionalPointerArray)[10])(void);//
//PointerTo_functionalPointerArray是指向(函数指针一维数组)的指针
/*
先看懂float(*ArrayPointer)[10];/*指向一个含有10个float元素的一维度数组的数组指针。
结合下面的注释就可与看懂了:
这个没看懂:
int*(*(*functionalPointerArray)[10])(void);
(指向包含10个元素的一维数组的指针,数组元素的类型为函数指针(函数的地址),
这些函数没有参数,函数返回值是int*)*/
2.命名一个简单的类型名代替复杂的类型表示方法
2.1
typedef用法:
1)命名一个新的类型名代表结构体类型:
typedef struct DataStruct{
int mouth;
int day;
int year;
}Data;这样就可以用新的类型名Data去定义变量(包括普通变量和指针变量!)
Data birthday;//等价于 struct DataStruct birthday
Data* p;//等价于 struct DataStruct* p
2)命名一个新的类型名代表数组类型:
typedef int Num[100];//声明Num为含有100个元素的整型数组类型名
Num a;//等价于int a[100];
3 )命名一个新的类型名代表指针类型:
typedef char* String//声明String为字符指针类型
String p,s[10];//定义p为字符指针变量,s为字符指针数组!
//等价于 char* p;char* s[10];
4)命名一个新的类型名代表函数指针:
typedef int(*Pointer)();//声明Pointer为指向函数的指针类型,该函数返回值为int
Pointer p1,p2;//p1,p2为Pointer类型的指针变量4.typedef与#define 的区别:
#define Count int//在预编译时做简单的替换
typedef int Count;//而typedef是在编译阶段处理的!有编译时类型检查!
从表面上看,上面两行代码的作用都是用Count代替int。但事实上,他们是不同的:
#define是在预编译时处理(编译预处理),它只做简单的字符串替换,
而typedef是在编译阶段处理的, typedef并不做简单的替换,并不是用Num[10]去替换int,而是采用如同定义变量的方法那样先生成一个类型名(就是前面介绍过的将原来的变量名替换成类型名),然后再用该类型名去定义变量!
参考
[1]typedef和#define的用法与区别https://www.cnblogs.com/kerwinshaw/archive/2009/02/02/1382428.html
[2]谭浩强. C程序设计(第四版)[J]. 计算机教育, 2010, No.128(20):113-113.
回到上面的判断单向链表有无环:
方法1:
/*方法1:最土的方法:将链表的每一个结点的地址存到一个向量里,
每次来一个新的节点时,在原先的向量里查找,如找到,则说明有重复节点,即
链表有环!缺点是时间复杂度为O(N*N)*/
/*方法1:最土的方法:将链表的每一个结点的地址存到一个向量里,
每次来一个新的节点时,在原先的向量里查找,如找到,则说明有重复节点,即
链表有环!缺点是时间复杂度为O(N*N)*/
bool hasLoop(Linklist head)
{
Linklist p = head;
if (!p)//空链表
return false;
if (p->next = nullptr)//只有一个结点
return false;
vector linkListVec;
vector::iterator iter;
while (p)
{
//刚进入循环的时候linkListVec为空
iter = find(linkListVec.begin(), linkListVec.end(), p);
if (iter == linkListVec.end())//没找到的情况
{
linkListVec.push_back(p);
p = p->next;
continue;
}
else//找到相同的地址!
{
return true;
}
}
return false;//所有结点都检查完了,正常退出循环的话p=nullptr,即该链表无环。
} /*方法二:参考《剑指Offer》面试题23:快慢指针法:
定义两个指针,同时从链表的第一个结点出发,一个指针每次走一步,一个指针每次走两步,
如果走得快的指针反而追上了走的慢的指针,那么链表就有环,
如果走的快的指针走到了链表的末尾(p=null)都没有追上走得慢的指针,那么该链表无环。
*/
/*方法二:参考《剑指Offer》面试题23:快慢指针法:
定义两个指针,同时从链表的第一个结点出发,一个指针每次走一步,一个指针每次走两步,
如果走得快的指针反而追上了走的慢的指针,那么链表就有环,
如果走的快的指针走到了链表的末尾(p=null)都没有追上走得慢的指针,那么该链表无环。
*/
bool hasLoop2(Linklist head)
{
Linklist pf, ps; //pfast 和pslow
pf = ps = head;
if (!pf)//空链表
return false;
if (pf->next = nullptr)//只有一个结点
return false;
while (pf)
{
pf = pf->next->next;
ps = ps->next;
if (pf == ps)
{
return true;
}
else
{
continue;
}
}
return false;
}
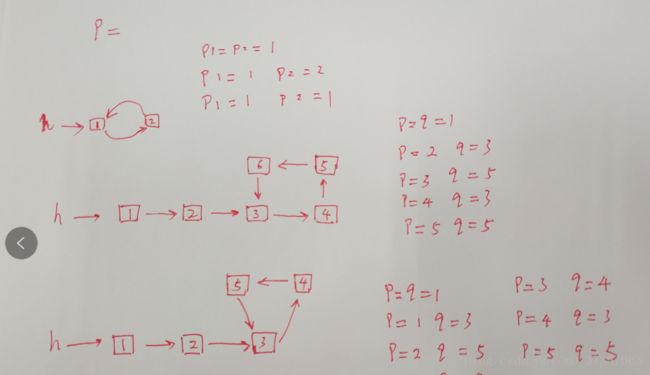
1.2求单向有环列表中环的入口结点!
参考《剑指offer面试题23》
这个题目分成三个小问题:
1.会判断一个单向链表是否有环
2.会求环中结点的个数
3.再求环的入口结点
下面依次解决:
1.判断单向链表是否有环:
/*方法二:参考《剑指Offer》面试题23:快慢指针法:
定义两个指针,同时从链表的第一个结点出发,慢指针每次走一步,快指针每次走两步,
如果走得快的指针反而追上了走的慢的指针,那么链表就有环,
如果走的快的指针走到了链表的末尾(p->next=null)都没有追上走得慢的指针,那么该链表无环。
*/
bool hasLoop2(Linklist head)
{
Linklist pf, ps; //pfast 和pslow
pf = ps = head;
if (!pf)//空链表
return false;
if (pf->next = nullptr)//只有一个结点
return false;
while (pf)
{
/*这里有个小小的bug,快指针不能一次性走两步,
得走一步判断一次!再走第二步!*/
//pf = pf->next->next;
pf = pf->next;
if (!pf)
{
pf = pf->next;
}
ps = ps->next;
if (pf == ps)
{
return true;
}
else
{
continue;
}
}
return false;
}
2.求环中的某一个结点:
/*《剑指offer》23题:链表中环的入口结点
第一步骤:先用上面的hasLoop2()判断链表有环吗?
第二步骤:想办法统计环中的结点个数!
如果知道了链表的环中有n个结点,那么先让快指针先从链表
头走n步,然后与慢指针一同每次一步向前遍历链表,
当他们再次相遇时就都指向了环的入口结点了!
那么我如何计算环中的结点个数呢?
在hasLoop2()函数中,是以快慢指针相遇作为有环的判据的!
那么如果他们相遇,一定是在环中相遇。
这是只要把相遇的结点地址记录下来,再
用一个指针顺着环遍历,边走边计结点数,当又回到起点是就
可以知道环中的结点个数了!
*/
/*
meetingNode()函数在链表中存在环的前提下返回快慢指针
在链表中相遇时的结点指针,
如链表无环,则返回nullptr
在找到环中的任意节点后,就能得出环中的节点数目,并且找到环的入口节点。
特例:(边界条件)
只有一个结点会不会形成环啊?
自身的next指针指向了自身!可成环啊!
*/
Linklist meetingNode(Linklist phead)
{
if (phead == nullptr)
{
return nullptr;
}
Linklist pSlow = phead->next;//慢指针指向了第2个结点
if (pSlow == nullptr)
{//若第二个结点为空,即只有一个结点,
return nullptr;
}
Linklist pFast = pSlow->next;
while (pFast != nullptr&&pSlow != nullptr)
{
if (pFast == pSlow)
{
return pFast;
}
pSlow = pSlow->next;
pFast = pFast->next;
if (pFast != nullptr)
{
pFast = pFast->next;
}
}
return nullptr;
}
3.最后求环的入口结点:
Linklist entryNodeOfLoop(Linklist phead)
{
Linklist meetedNode = meetingNode(phead);
if (meetedNode == nullptr)
{
return nullptr;
}
int nodesInLoop = 1;
//得到环中的节点数目nodesInLoop
Linklist pNode = meetedNode;
while (pNode->next != meetedNode)
{
nodesInLoop++;
pNode = pNode->next;
}
//pNode指向头结点
pNode = phead;
//让pNode先走nodesInLoop步
for (int i = 0; i < nodesInLoop; i++)
{
pNode = pNode->next;
}
Linklist pNode2 = phead;
while (pNode!= pNode2)
{
pNode = pNode->next;
pNode2 = pNode2->next;
}
return pNode;//返回指向入口结点的指针!
}
- 数据结构:哈希表:冲突处理有哪几种方法?其中链地址法有什么缺点吗?怎么改进?
链地址法缺点:1.时间复杂度较其他的高(因为可能要遍历链表)2.有的关键字得到的哈希地址频次交高,则该节点对于的链表就非常长?怎么改进?(再哈希法!)
首先你要知道哈希表是干嘛的啊?!
哈希表是一种查找表!哈希函数、地址冲突、平均查找长度、装填因子等概念!
一旦哈希表建立好了,一来一个关键字,我用哈希函数一算就可与算出其在表中的地址,就可与直接去该地址处看这个关键字对应的元素存在吗?如果存在就找到了,如果不存在则查找失败!
哈希函数表的定义:
根据设定的哈希函数H(key)和一种冲突处理方法将一组关键字映像到一个有限连续的地址集(区间)上,并以关键字在地址集中的“像”作为记录在表中的存储位置,这种表便是哈希表,这一映像过程称为哈希造表或散列,所得存储位置成为哈希地址或散列地址!
-
- 哈希函数的构造方法
- 直接定址法
- 数字分析法
- 平方取中法
- 折叠法
- 除留余数法
- 随机数法
选择哈希函数要考虑的因素:
- 哈希函数的复杂度(计算哈希函数所需要时间)
- 关键字的长度
- 哈希表的大小
- 关键字的分布情况
- 记录的查找频率
2.哈希表是一个压缩映像,所有会出现冲突。
假设哈希表的地址集为0~(n-1),冲突是指由关键字得到的哈希地址为j(0<=k<=n-1)的位置上已经存在有记录,则“处理冲突“就是为该关键字的记录找到另外一个”空“的哈希地址。在处理冲突的过程中可能得到一个地址序列Hi,i=1,2,...,k,(Hi属于[0,n-1]),依次类推,直到Hk不发生冲突为止,则Hk为记录在表中的地址。
处理冲突的方法:
1)开发定址法
Hi=(H(key)+di)MODm i=1,2,...,k(k<=m-1)
H()为哈希函数,k为哈希表长度,di为增量序列:
di=1,2,3,...,m-1,成为线性探测再散列法
di=12,-12,22,...,+-k2(k<=m/2)称为二次探测再散列法
di=伪随机数序列,则称为随机探测再散列法。
线性探测再散列法容易引起“二次聚集“现象。
2)再哈希法
Hi=RHi(key) i=1,2,...,k
RHi均是不同的哈希函数。
3)链地址法
将所有关键字为同义词的记录(具有相同函数值的关键字对该哈希函数来说称为同义词synonym)存储在同一线性链表中。假设某个哈希函数产生的哈希地址在区间[0,m-1]上,则设立一个指针型向量
Chain ChainHash[m];
其每个分量的初始状态都为空指针。凡哈希地址为i的记录都插入到头指针为ChainHash[i]的链表中,在链表中插入的位置要保证同义词在同一线性列表中按关键字有序(以便进行二分查找)
4)建立公共溢出区
HashTable[0..m-1]为基本表
OverTable[0...v]为溢出表
参考
[1] 严蔚敏, 吴伟民. 数据结构(C语言版)[J]. 计算机教育, 2012, No.168(12):62-62.
[2]STL的map、hash_map的使用https://blog.csdn.net/q_l_s/article/details/52416583
3.linux的IO多路复用知道吗?(貌似很爱考)select、poll方法?
4.linux 调试工具GDB用过吗?(gg:上次是腾讯的问过!,至少要去看了记住啊!)
5.C++程序的内存模型怎样?(常考!)
看下这篇博文https://www.cnblogs.com/Stultz-Lee/p/6751522.html
最好记住啊!
C程序内存模型:
1)C的内存分4个区:C分为四个区:堆,栈,静态全局变量区,常量区
C++程序内存模型:
2)C++内存分为5个区域(堆栈全常代 ):
Linux系统程序的内存模型:
3)在linux系统中,程序在内存中的分布如下所示:
低地址
.text---> .data --->.bss
--->heap(堆) --> unused <-- stack(栈)
-->env
高地址
6.接着问内存:堆栈的区别?new/delete 与C的malloc()/free()的区别?delete与delete[]的区别?(老生常谈!)
好了来个新生常态:在多线程编程中,一个进程中的各个子线程可与共享堆区中分配的内存空间吗?
7.操作系统:内存:怎么从逻辑地址映射到物理地址?
参考这篇博文:[2] https://www.cnblogs.com/felixfang/p/3420462.html
8.网络:详细问TCP的连接建立和断开!三次握手四次挥手!!各个阶段各个状态都要记住!如果连接双方都请求断开连接是怎么一个过程?
9.linux网络编程中的accept()系统调用是TCP三次握手连接的哪一个阶段???
软件开发面试 编程语言 数据结构 网络 操作系统