HDP YARN MapReduce参数调优建议
HDP平台参数调优建议
根据上面介绍的相关知识,我们就可以根据我们的实际情况作出相关参数的设置,当然还需要在运行测试过程中不断检验和调整。
以下是hortonworks给出的配置建议:
http://docs.hortonworks.com/HDPDocuments/HDP2/HDP-2.1.1/bk_installing_manually_book/content/rpm-chap1-11.html
1.1 RM的内存资源配置, 配置的是资源调度相关
RM1:yarn.scheduler.minimum-allocation-mb 分配给AM单个容器可申请的最小内存
RM2:yarn.scheduler.maximum-allocation-mb 分配给AM单个容器可申请的最大内存
注:
l 最小值可以计算一个节点最大Container数量
l 一旦设置,不可动态改变
1.2 NM的内存资源配置,配置的是硬件资源相关
NM1:yarn.nodemanager.resource.memory-mb 节点最大可用内存
NM2:yarn.nodemanager.vmem-pmem-ratio 虚拟内存率,默认2.1
注:
l RM1、RM2的值均不能大于NM1的值
l NM1可以计算节点最大最大Container数量,max(Container)=NM1/RM2
l 一旦设置,不可动态改变
1.3 AM内存配置相关参数,配置的是任务相关
AM1:mapreduce.map.memory.mb 分配给map Container的内存大小
AM2:mapreduce.reduce.memory.mb 分配给reduce Container的内存大小
l 这两个值应该在RM1和RM2这两个值之间
l AM2的值最好为AM1的两倍
l 这两个值可以在启动时改变
AM3:mapreduce.map.java.opts 运行map任务的jvm参数,如-Xmx,-Xms等选项
AM4:mapreduce.reduce.java.opts 运行reduce任务的jvm参数,如-Xmx,-Xms等选项
注:
1.这两个值应该在AM1和AM2之间
4.1 内存分配
Reserved Memory = Reserved for stack memory + Reserved for HBase Memory (If HBase is on the same node)
系统总内存126GB,预留给操作系统24GB,如果有Hbase再预留给Hbase24GB。
下面的计算假设Datanode节点部署了Hbase。
4.2containers 计算:
MIN_CONTAINER_SIZE = 2048 MB
containers = min (2*CORES, 1.8*DISKS, (Total available RAM) / MIN_CONTAINER_SIZE)
# of containers = min (2*12, 1.8*12, (78 * 1024) / 2048)
# of containers = min (24,21.6,39)
# of containers = 22
container 内存计算:
RAM-per-container = max(MIN_CONTAINER_SIZE, (Total Available RAM) / containers))
RAM-per-container = max(2048, (78 * 1024) / 22))
RAM-per-container = 3630 MB
4.3Yarn 和 Mapreduce 参数配置:
yarn.nodemanager.resource.memory-mb = containers * RAM-per-container
yarn.scheduler.minimum-allocation-mb = RAM-per-container
yarn.scheduler.maximum-allocation-mb = containers * RAM-per-container
mapreduce.map.memory.mb = RAM-per-container
mapreduce.reduce.memory.mb = 2 * RAM-per-container
mapreduce.map.java.opts = 0.8 * RAM-per-container
mapreduce.reduce.java.opts = 0.8 * 2 * RAM-per-container
yarn.nodemanager.resource.memory-mb = 22 * 3630 MB
yarn.scheduler.minimum-allocation-mb = 3630 MB
yarn.scheduler.maximum-allocation-mb = 22 * 3630 MB
mapreduce.map.memory.mb = 3630 MB
mapreduce.reduce.memory.mb = 22 * 3630 MB
mapreduce.map.java.opts = 0.8 * 3630 MB
mapreduce.reduce.java.opts = 0.8 * 2 * 3630 MB
附:规整化因子介绍
为了易于管理资源和调度资源,Hadoop YARN内置了资源规整化算法,它规定了最小可申请资源量、最大可申请资源量和资源规整化因子,如果应用程序申请的资源量小于最小可申请资源量,则YARN会将其大小改为最小可申请量,也就是说,应用程序获得资源不会小于自己申请的资源,但也不一定相等;如果应用程序申请的资源量大于最大可申请资源量,则会抛出异常,无法申请成功;规整化因子是用来规整化应用程序资源的,应用程序申请的资源如果不是该因子的整数倍,则将被修改为最小的整数倍对应的值,公式为ceil(a/b)*b,其中a是应用程序申请的资源,b为规整化因子。
比如,在yarn-site.xml中设置,相关参数如下:
yarn.scheduler.minimum-allocation-mb:最小可申请内存量,默认是1024
yarn.scheduler.minimum-allocation-vcores:最小可申请CPU数,默认是1
yarn.scheduler.maximum-allocation-mb:最大可申请内存量,默认是8096
yarn.scheduler.maximum-allocation-vcores:最大可申请CPU数,默认是4
对于规整化因子,不同调度器不同,具体如下:
FIFO和Capacity Scheduler,规整化因子等于最小可申请资源量,不可单独配置。
Fair Scheduler:规整化因子通过参数yarn.scheduler.increment-allocation-mb和yarn.scheduler.increment-allocation-vcores设置,默认是1024和1。


以下几个参数:
yarn.nodemanager.vmem-pmem-ratio:任务每使用1MB物理内存,最多可使用虚拟内存量,默认是2.1。yarn.nodemanager.pmem-check-enabled:是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true。yarn.nodemanager.vmem-pmem-ratio:是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true。
第一个参数的意思是当一个map任务总共分配的物理内存为2G的时候,该任务的container最多内分配的堆内存为1.6G,可以分配的虚拟内存上限为2*2.1=4.2G。另外,照这样算下去,每个节点上YARN可以启动的Map数为104/2=52个。
CPU配置
YARN中目前的CPU被划分成虚拟CPU(CPU virtual Core),这里的虚拟CPU是YARN自己引入的概念,初衷是,考虑到不同节点的CPU性能可能不同,每个CPU具有的计算能力也是不一样的,比如某个物理CPU的计算能力可能是另外一个物理CPU的2倍,这时候,你可以通过为第一个物理CPU多配置几个虚拟CPU弥补这种差异。用户提交作业时,可以指定每个任务需要的虚拟CPU个数。
在YARN中,CPU相关配置参数如下:
yarn.nodemanager.resource.cpu-vcores:表示该节点上YARN可使用的虚拟CPU个数,默认是8,注意,目前推荐将该值设值为与物理CPU核数数目相同。如果你的节点CPU核数不够8个,则需要调减小这个值,而YARN不会智能的探测节点的物理CPU总数。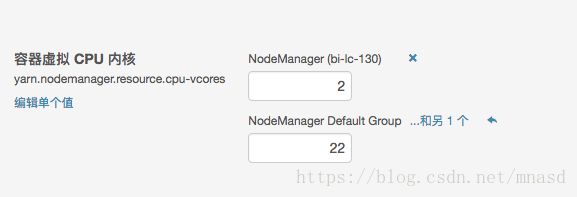
yarn.scheduler.minimum-allocation-vcores:单个任务可申请的最小虚拟CPU个数,默认是1,如果一个任务申请的CPU个数少于该数,则该对应的值改为这个数。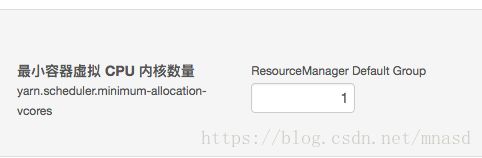
yarn.scheduler.maximum-allocation-vcores:单个任务可申请的最多虚拟CPU个数,默认是32。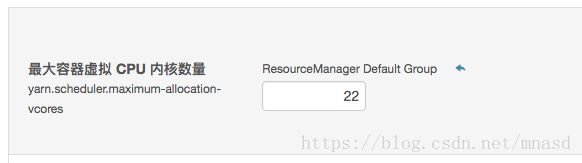
对于一个CPU核数较多的集群来说,上面的默认配置显然是不合适的,在我的测试集群中,4个节点每个机器CPU核数为31,留一个给操作系统,可以配置为:
-
-
yarn.nodemanager.resource.cpu-vcores -
31 -
-
-
yarn.scheduler.maximum-allocation-vcores -
124 -
Capacity Scheduler是YARN中默认的资源调度器。
想要了解Capacity Scheduler是什么,可阅读我的这篇文章“Hadoop Capacity Scheduler分析”。
在Capacity Scheduler的配置文件中,队列queueX的参数Y的配置名称为yarn.scheduler.capacity.queueX.Y,为了简单起见,我们记为Y,则每个队列可以配置的参数如下:
1. 资源分配相关参数
(1) capacity:队列的资源容量(百分比)。 当系统非常繁忙时,应保证每个队列的容量得到满足,而如果每个队列应用程序较少,可将剩余资源共享给其他队列。注意,所有队列的容量之和应小于100。
(2) maximum-capacity:队列的资源使用上限(百分比)。由于存在资源共享,因此一个队列使用的资源量可能超过其容量,而最多使用资源量可通过该参数限制。
m minimum-user-limit-percent:每个用户最低资源保障(百分比)。任何时刻,一个队列中每个用户可使用的资源量均有一定的限制。当一个队列中同时运行多个用户的应用程序时中,每个用户的使用资源量在一个最小值和最大值之间浮动,其中,最小值取决于正在运行的应用程序数目,而最大值则由minimum-user-limit-percent决定。比如,假设minimum-user-limit-percent为25。当两个用户向该队列提交应用程序时,每个用户可使用资源量不能超过50%,如果三个用户提交应用程序,则每个用户可使用资源量不能超多33%,如果四个或者更多用户提交应用程序,则每个用户可用资源量不能超过25%。
(3) user-limit-factor:每个用户最多可使用的资源量(百分比)。比如,假设该值为30,则任何时刻,每个用户使用的资源量不能超过该队列容量的30%。
2. 限制应用程序数目相关参数
(1) maximum-applications :集群或者队列中同时处于等待和运行状态的应用程序数目上限,这是一个强限制,一旦集群中应用程序数目超过该上限,后续提交的应用程序将被拒绝,默认值为10000。所有队列的数目上限可通过参数yarn.scheduler.capacity.maximum-applications设置(可看做默认值),而单个队列可通过参数yarn.scheduler.capacity.
(2) maximum-am-resource-percent:集群中用于运行应用程序ApplicationMaster的资源比例上限,该参数通常用于限制处于活动状态的应用程序数目。该参数类型为浮点型,默认是0.1,表示10%。所有队列的ApplicationMaster资源比例上限可通过参数yarn.scheduler.capacity. maximum-am-resource-percent设置(可看做默认值),而单个队列可通过参数yarn.scheduler.capacity.
3. 队列访问和权限控制参数
(1) state :队列状态可以为STOPPED或者RUNNING,如果一个队列处于STOPPED状态,用户不可以将应用程序提交到该队列或者它的子队列中,类似的,如果ROOT队列处于STOPPED状态,用户不可以向集群中提交应用程序,但正在运行的应用程序仍可以正常运行结束,以便队列可以优雅地退出。
(2) acl_submit_applications:限定哪些Linux用户/用户组可向给定队列中提交应用程序。需要注意的是,该属性具有继承性,即如果一个用户可以向某个队列中提交应用程序,则它可以向它的所有子队列中提交应用程序。配置该属性时,用户之间或用户组之间用“,”分割,用户和用户组之间用空格分割,比如“user1, user2 group1,group2”。
(3) acl_administer_queue:为队列指定一个管理员,该管理员可控制该队列的所有应用程序,比如杀死任意一个应用程序等。同样,该属性具有继承性,如果一个用户可以向某个队列中提交应用程序,则它可以向它的所有子队列中提交应用程序。
一个配置文件实例如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 |
<description
description>
<description
|
参考文章
- Determine HDP Memory Configuration Settings
- Hadoop YARN如何调度内存和CPU