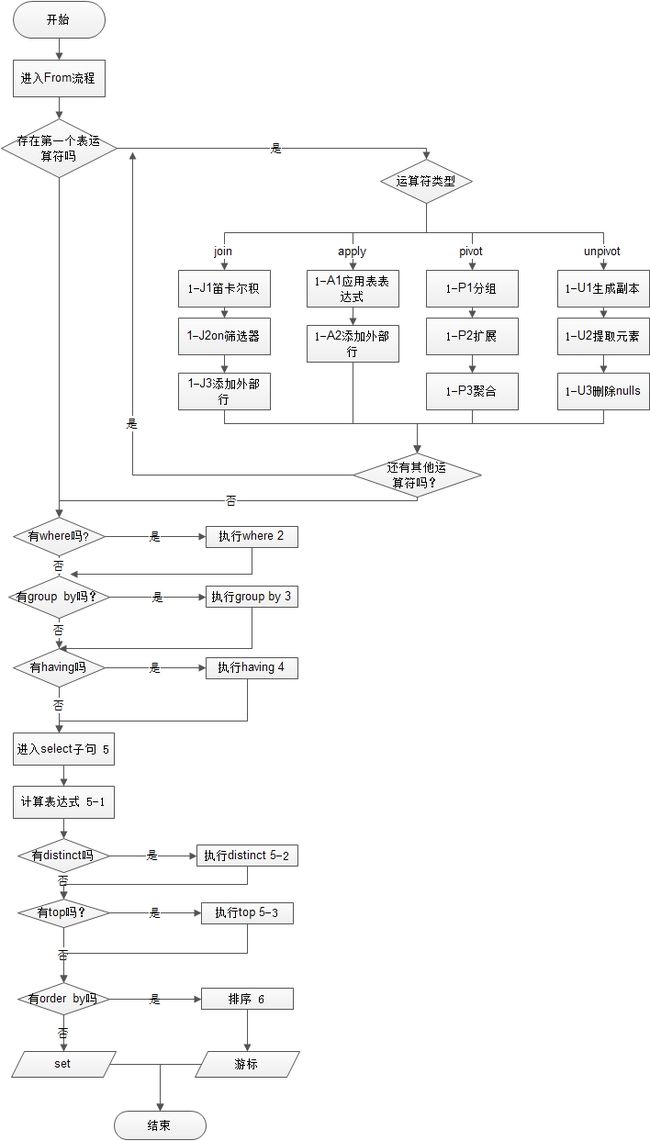
数据库系统实验二(查询)
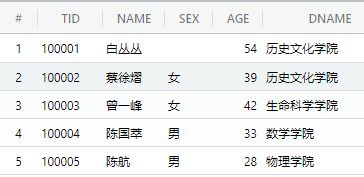
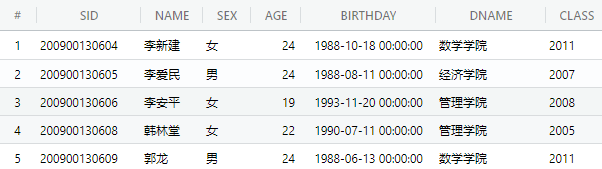
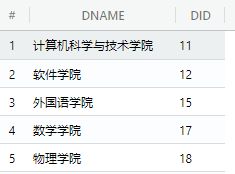
本次实验所用表
①pub.student_course ②pub.teacher

③pub.student
④pub.course ⑤pub.department

1.找出没有选修任何课程的学生的学号、姓名(即没有选课记录的学生)。自己认为查询语句正确后,通过下面语句将查询语句创建成视图test2_01,Create or replace view test2_01 as select
create or replace view test2_01 as select sid,name from pub.student
where sid not in (select sid from pub.student_course);从学生表中选出学号没有出现在选课表中的学号和姓名,注意not in 表示集合间关系。
2. 找出至少选修了学号为"200900130417"的学生所选修的一门课的学生的学号、姓名。
自己认为查询语句正确后,通过下面语句将查询语句创建成视图test2_02,Create or replace view test2_02 as select ……
create or replace view test2_02 as
select sid,sname from pub.student
where sid in (select sid from pub.student_course
where cid in (select cid from pub.student_courese where sid = '200900130417'))3.找出至少选修了一门其先行课程号为"300002"号课程的学生的学号、姓名
create or replace view test2_03 as
select pub.student.sid,pub.student.name from pub.student,pub.student_course,pub.course
where pub.student_course.sid = pub.student.sid
and pub.student_course.cid = pub.course.cid
and Fcid = '300002';注意事项(重要):
①from子句列出查询对象的表,当目标列来自多个表时,在不至于混淆的时候不用显式知名来自哪个关系,会混淆时用pub.student.sid这样显示指明。
②from子句中的多个查询表相当于构成 笛卡尔积 不是自然连接,所以加入pub.student_course.sid = pub.student.sid 这类约束保证一个类似于自然连接。
4.找出选修了"操作系统"并且也选修了"数据结构"的学生的学号、姓名。
create or replace view test2_04 as
( select pub.student.sid,pub.student.name from pub.student,pub.student_course,pub.course
where pub.student.sid = pub.student_course.sid and
pub.student_course.cid = pub.course.cid and
pub.course.name = '操作系统'
)
intersect
( select pub.student.sid,pub.student.name from pub.student,pub.student_course,pub.course
where pub.student.sid = pub.student_course.sid and
pub.student_course.cid = pub.course.cid and
pub.course.name = '数据结构'
);注意事项:intersect取交集,适合于即......又......的查询规则。
5. 查询20岁的所有有选课的学生的学号、姓名、平均成绩(avg_score,此为列名,下同)(平均成绩四舍五入到个位)、
总成绩(sum_score),Test2_05有四个列,并且列名必须是:sid、name、avg_score、sum_score。通过下面方式实现列名定义:create or replace view test2_05 as select sid,name,(表达式) avg_score,(表达式) sum_score from ……
create or replace view test2_05 as
(
select pub.student.sid,pub.student.name,round(AVG(score),0) avg_score,SUM(score) sum_score
from pub.student,pub.student_course
where pub.student.sid = pub.student_course.sid and
pub.student.age = 20
group by pub.student.sid,pub.student.name
)注意事项:
①更名运算,old_name as new name ,as可选。
②当select字句中出现可聚集函数和其他属性名,其他属性名一定是用来分组的,不然没法显示,聚集函数就返回一行信息,其他属性可能是多行的。
③having对象是分组,where对象是元组。
④round四舍五入到个位。
6. 查询所有课的最高成绩、次高成绩(次高成绩一定小于最高成绩)、最高成绩人数,test2_06有四个列:课程号cid、课程名称name、最高成绩max_score、次高成绩max_score2、最高成绩人数max_score_count(一个学生同一门课成绩都是第一,只计一次)。如果没有学生选课,则最高成绩为空值,最高成绩人数为零。如果没有次高成绩,则次高成绩为空值。
提示1:任何select 确保只返回一个结果 from …… where ……t1.xx=t2.xx (条件中还可以出现主表的列来限制每行结果的不同)可以是另外一个select的一个输出表达式。格式如:select sid,(select……) 列别名 from …… where ……。
提示2:任何select 确保只返回一个结果 from …… where ……(不能引用主表来)可以出现在另外一个sql的条件表达式中。格式如:select …… from …… where xx=(select……)。
提示3:任何select …… from …… where ……可以是另外一个sql的表,即派生表。格式如:select …… from student,(select……)表别名 where ……。
???7.查询所有不姓张、不姓李、也不姓王的学生的学号sid、姓名name
create or replace view test2_07 as
(
select sid,name from pub.student
where name not like '张%' and name not like '李%' and name not like '王%'
);%匹配任意多个字符,_匹配任意单个字符。
8.查询学生表中每一个姓氏及其人数(不考虑复姓),test2_08有两个列:second_name、p_count
create or replace view test2_08 as
( select substr(name,1,1) second_name ,count(*) p_count from pub.student
group by substr(name,1,1)
);①substr(1,2)从第一个字符开始,截取长度为2,如substr(“hello”,1,2)为“he”
②如文章末尾sql语句执行顺序表所示,sql首先from,然后where,group,having,之后才执行select语句,所以在group by 中不能选择rename后的属性second_name
https://www.cnblogs.com/yyjie/p/7788428.html sql顺序
③group自带distinct功能
9.查询选修了300003号课程的学生的sid、name、score
create or replace view test2_09 as
( select pub.student.sid,pub.student.name,pub.student_course.score
from pub.student,pub.student_course
where pub.student.sid = pub.student_course.sid
and pub.student_course.cid = '300003'
);10.找出同一个同学同一门课程有两次或以上不及格的所有学生的学号、姓名(即一门课程需要补考两次或以上的学生的学号、姓名
create or replace view test2_10 as
select sid,name from pub.student where sid in
(select sid from ( select pub.student_course.sid, pub.student_course.cid ,count(*) count from pub.student_course
where score<60
group by pub.student_course.sid, pub.student_course.cid
)
where count>=2);当group不和聚集函数一起用的时候就相当于distinct去重一样,除此之外别无它用。
select name from student group by name
等价于 select distinct name from student