SqlServer聚集索引原理
测试所用数据库:SQLSERVER2012
我们都知道索引能提高查询速度,那么索引到底是怎么提高查询速度的呢?这要从索引的数据结构说起
索引分为聚集索引和非聚集索引,这两种索引的数据结构都是B+树,这篇文章主要讲解聚集索引
首先我们创建一个测试表:
CREATE TABLE Department(
DepartmentID int IDENTITY(1,1) NOT NULL PRIMARY KEY,
Name NVARCHAR(200) NOT NULL,
GroupName NVARCHAR(200) NOT NULL,
Company NVARCHAR(300),
ModifiedDate datetime NOT NULL DEFAULT (getdate())
)再创建一个用来存储表对象内部存储信息的表:
CREATE TABLE DBCCResult (
PageFID NVARCHAR(200),
PagePID NVARCHAR(200),
IAMFID NVARCHAR(200),
IAMPID NVARCHAR(200),
ObjectID NVARCHAR(200),
IndexID NVARCHAR(200),
PartitionNumber NVARCHAR(200),
PartitionID NVARCHAR(200),
iam_chain_type NVARCHAR(200),
PageType NVARCHAR(200),
IndexLevel NVARCHAR(200),
NextPageFID NVARCHAR(200),
NextPagePID NVARCHAR(200),
PrevPageFID NVARCHAR(200),
PrevPagePID NVARCHAR(200)
)向表Department中插入测试数据
INSERT INTO Department(name,[Company],groupname) VALUES('销售部','中国你好有限公司XX分公司','销售组')
GO 100000将表Department的内部存储信息写入到表DBCCResult中:
INSERT INTO DBCCResult EXEC ('DBCC IND(indextest,Department,-1) ')DBCC ind:查询 indextest数据库中Department表的内部存储信息。然后将查询结果插入到表DBCCResult,关于DBCC IND的详细用法请参考MSDN.
查询表DBCCResult的内容:
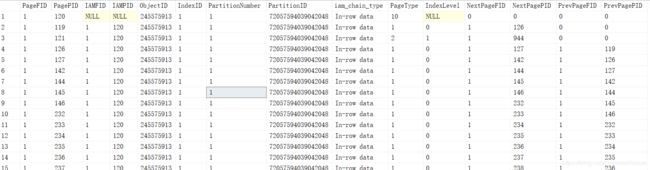
PageType 分页类型: 1:数据页面;2:索引页面;3:Lob_mixed_page;4:Lob_tree_page;10:IAM页面
IndexID 索引ID: 0 代表堆, 1 代表聚集索引, 2-250 代表非聚集索引 ,大于250就是text或image字段
IndexLevel 索引层次:0代表叶子节点,1代表叶子节点的上一层节点,以此类推,最大的那个数即是树的高度
为了更突出树的结构,我们查询索引页面:
select * from DBCCResult where PageType<>1
1、第一条数据PageType=10,表示这是一个IAM页面,IAM页不是只有堆表才有也不只是维护堆表中的数据页的连续,有索引的表都有,所以IAM页不只维护数据页,也维护索引页的连续
2、下面三条数据的PageType=2,表示索引页面。第3条数据的IndexLevel=2,表示这是根节点,第2条和第4条是它的子节点
3、每个数据页的IndexID都是1,不是说数据页变成了索引页,而是说现在数据页已经属于聚集索引的一部分,不在堆里了
4、每个数据页的IndexLevel都是0,就是说数据页在聚集索引的最下层。IndexID=1并且PageType=1的IndexLevel=0,这个表示聚集索引的叶子节点就是数据页。
下面我们来看一下索引页里的内容:
首先我们打开3604跟踪标志,将dbcc的输出返回到客户端;
dbcc traceon(3601,-1)查询索引页面的页面信息:
dbcc page('IndexTest',1,943,3)
dbcc page('IndexTest',1,121,3)
dbcc page('IndexTest',1,944,3)我的根页面的PageId是943,大家可查看自己的根页面ID是多少,替换943查询
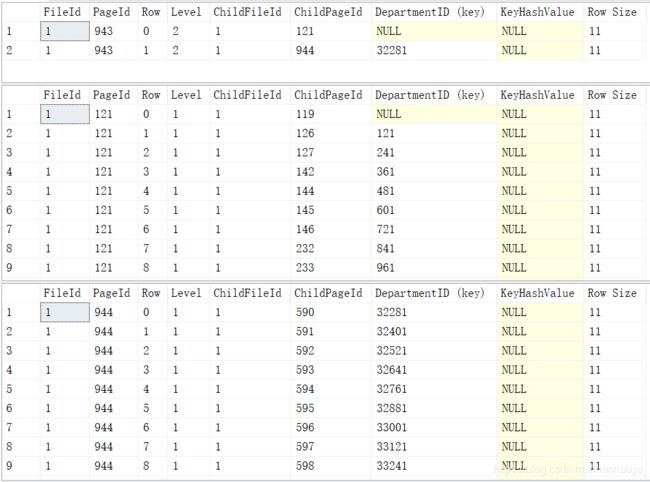
我们可以看到DepartmentID后面有一个key,表明这是一个索引列,这个值就是DepartmentID的值。还有两个列需要特别注意:ChildPageId和KeyHashValue。一个非叶级节点有3部分组成:主键值(DepartmentID)、指向下一个节点的指针(ChildPageId)、主键值的哈希值。但是目前我们的主键哈希值为空,这一点我现在也没弄明白。
我们可以看到每个部门ID和下一行的部门ID都相差了120条记录,这说明一个数据页只能容纳120条记录
使用聚集索引查找数据有2种方式:聚集索引查找和聚集索引扫描
聚集索引查找流程:先用二分法找到实际的数据页面,然后再从数据页面中把数据读出来。
需要特别注意的是:聚集索引查询并不能具体定位到某一条记录,而是定位到数据页,即PageID。数据库会把所有的数据页都加载到内存中,在内存中的一个数据页中查找一条记录,这个是很快的,几乎可以忽略不记。
对于聚集索引扫描,我们举个例子来看一下:
创建一个新的Department3表:
CREATE TABLE Department3(
DepartmentID int IDENTITY(1,1) NOT NULL PRIMARY KEY,
Name NVARCHAR(200) NOT NULL,
GroupName NVARCHAR(200) NOT NULL,
Company NVARCHAR(300),
ModifiedDate datetime NOT NULL DEFAULT (getdate())
)插入测试数据:
DECLARE @i INT
SET @i=1
WHILE @i <= 100000
BEGIN
INSERT INTO Department3 ( name, [Company], groupname )
VALUES ( '销售部', '中国你好有限公司XX分公司'+CAST(@i AS VARCHAR(200)), '销售组'+CAST(@i AS VARCHAR(200)) )
SET @i = @i + 1
END使用隔离级别为可重复读的事务读取数据,这个操作的目的是查看数据库锁的使用情况
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ
begin tran
SELECT * FROM [dbo].[Department3] WHERE [GroupName] ='销售组83421'
SELECT
[request_session_id],
c.[program_name],
DB_NAME(c.[dbid]) AS dbname,
[resource_type],
[request_status],
[request_mode],
[resource_description],OBJECT_NAME(p.[object_id]) AS objectname,
p.[index_id]
FROM sys.[dm_tran_locks] AS a LEFT JOIN sys.[partitions] AS p
ON a.[resource_associated_entity_id]=p.[hobt_id]
LEFT JOIN sys.[sysprocesses] AS c ON a.[request_session_id]=c.[spid]
WHERE c.[dbid]=DB_ID('indextest') and OBJECT_NAME(p.[object_id])='Department3'
ORDER BY [resource_type]
commit tran结果如下:
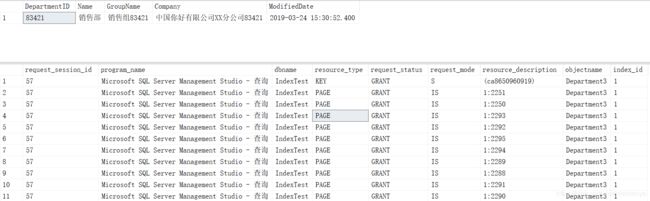
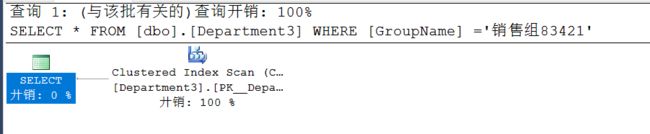
可以看到查询使用的聚集索引扫描。关于锁,我们看[resource_type]字段,有一个key(键锁)和大量的Page(页锁)。那这是为什么呢?因为聚集索引的数据页就是索引页,位于B+树的最底层。所以要扫描表里面的数据,即是扫描整个聚集索引。所以聚集索引扫描和整表扫描耗时是没有多大区别的。
加键锁是因为定位到那一条数据后,需要在记录所在的数据页上加一个键锁,防止其他人篡改。
因为聚集索引扫描等同于整表扫描,SQLSERVER要不停地扫描所有的数据页,所以所有的数据页都加上了页锁。
总结:
1、SQLSERVER索引采用B+树数据结构存储
2、聚集索引的数据页即是聚集索引的叶子节点,也就是说有聚集索引的表,表中的所有列的数据都存储在叶子节点中。索引页只起到导航的作用,每次查询都要查询到叶子节点为止。
3、叶子节点的每个相邻节点都有2个指针,一个指向前一个节点,一个指向下一个节点,按照键值从左到右排序,组成了一个有序的链表。排序的规则是按照聚集索引的第一列排序。
4、聚集索引查找并不能定位到数据页中的某一条记录,而是定位到某一个数据页,然后在数据页中查询。