使用 DolphinScheduler 调度 Kylin 构建
原创 史少锋@Kyligence apachekylin 前天
01 背景
Apache Kylin 是一个支持海量大数据的在线分析引擎,需要离线或流式地从Apache Hive, Apache Kafka加载数据。通常当上游数据准备好以后,用户需要使用Kylin的Web界面或API触发以生成数据加载的任务。为了让整个工作流自动化起来,需要结合一些任务调度平台,如Oozie,Linux crontab等。本文将介绍如何使用Apache DolphinScheduler这个新的开源平台跟Kylin进行集成完成数据构建。
02 什么是 Dolphin Scheduler
Apache DolphinScheduler(incubating)(简称 DS) 是一个Apache孵化器项目,是由国内企业易观开源的大数据项目,是一个面向大数据应用的分布式工作流任务调度系统,之前叫EasyScheduler。目前DS 在国内已经有一定规模的用户基础,包括美团、平安、雪球等。
官网:https://dolphinscheduler.apache.org/
这里我们引用一下DS刚开源时的介绍([1]):相信做过数据处理的伙伴们对开源的调度系统如Oozie、Azkaban、Airflow应该都不陌生,在使用这些调度系统中可能会有这样的体验:比如配置工作流任务不能可视化、任务的运行状态不能实时在线查看、 任务运行时不能暂停、不能支持参数传递、不能补数、不能多租户使用、调度系统不高可用等等问题所烦扰过。Easy Scheduler正是在这种背景下应运而生,其目标就是为使调度更加easy,更可以从其中文名“易调度”看出我们的初衷。
下图是一个跟Azkaban、Airflow的多方面对比:
从这个图上可以看出,DS 设计之初就考虑了高可用、多租户、可视化等高级功能,也支持扩展任务类型等,相比于其它工具来说,更适合企业内的复杂场景,可视化的操作界面也非常适合作为平台交给各部门自助使用。(注:Airflow 目前也有多租户的支持)
03 DS 的安装
为了验证 DS 的功能,我们决定先在一个单机上进行安装。参考文档后,发现它的安装配置步骤稍多,于是先尝试Docker 安装;可惜的是,它的Dockerfile 跟当前代码有一些不匹配,加上国内的网络条件,docker build 屡次失败,于是就放弃了,尝试单机从二进制包安装。
从官网[2]下载1.2.0版本的安装包,分前端和后端两个包;前端是一些静态文件,不到2MB;后端是主程序,较大127MB;前后端需要分别安装和配置。(据了解从1.2.1后,前后端将不再分离。)
参考前端安装文档[3],将资源放到某个目录,然后安装和配置Nginx,让其8888端口的静态资源从DS的前端目录获取,如果是API的调用,转给后端服务12345端口;了解Nginx配置的话这块不难。小注意一下,它的安装脚本 install-dolphinscheduler-ui.sh会自动安装Nginx,如果你的系统中已经有Nginx服务的话,需要手动修改脚本以避免重新安装。
后端的安装相对比较复杂一些。首先你需要准备前置条件:
- Linux服务器一台,CentOS 6/7 或Ubuntu;
- 创建一个dolphinscheduler的Linux账户,有sudo权限,且开启免密码登录;即便是单机安装也需要;
- MySQL 5.7;起初我的MySQL版本较低(5.1),遇到DB初始化脚本失败的问题,切换高版本MySQL后解决;
- Zookeeper,用于协调多个节点的状态。
安装的时候,需要仔细查看它的安装文档[4];文档中介绍了多节点的自动部署(为有自动化一键安装脚本点赞),但没有介绍单节点的手动部署。我先用了它的自动部署脚本install.sh,发现略有点复杂,在DS开发者的指导下改用手动部署。下面是一些注意事项:
- 安装和启动服务的时候,切换到 dolphinscheduler 用户,不要用 root;使用root会让一些新创建的目录权主是root,其它用户不可访问;
- 安装目录不要放到/root等高权限目录,最好放到 /opt 或 dolphinscheduler 的 home 目录下;
- MySQL JDBC 连接的配置,除了在 conf/application-dao.properties以外,还需要在conf/quartz.properties 也里配置一下;
- DS的安装目录,需要显式地在 conf/common/common.properties 里配置一下,默认的安装目录 /data1_1T/dolphinscheduler 很可能不是你的安装路径;
- 在 conf/config/run_config.conf 中配置各个节点的机器名;如果单机的话,配置本机的机器名;
- 在 conf/zookeeper.properties 中配置zk地址;
- 启动使用 scripts/start-all.sh和scripts/stop-all.sh 来启动和停止;如果不正常,检查在logs目录下的日志;
- 确保 Nginx 之前已经正常启动
04 DS 创建项目和进程
如果一切正常的话,浏览器打开 http://
按照使用操作手册,先创建项目,再创建一个租户(tenant);租户就是运行任务的Linux 用户。
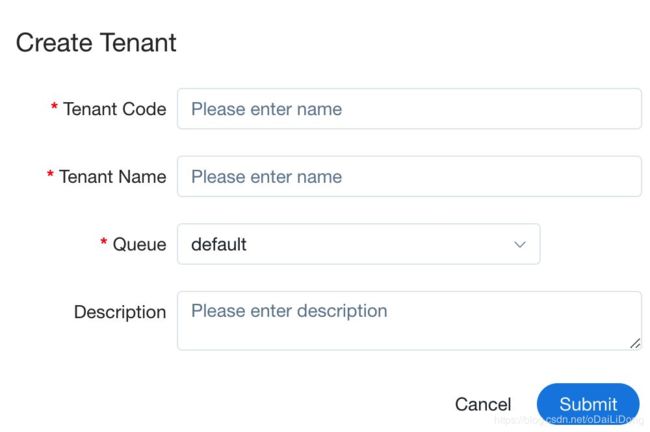
创建租户后,还要将DS的用户跟租户进行绑定,默认的admin用户初始是没有租户的,所以需要进行绑定后才可以执行任务;
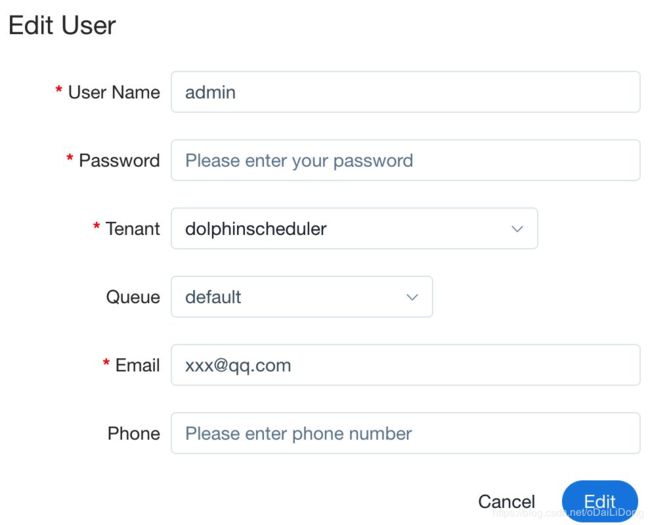
在这之后,你就可以进入项目,创建进程(process)了,DS 提供了可视化的界面,让你可以图形化拖拽地方式定义工作流DAG:

这里看到,DS 内置了若干种任务,例如Spark, Flink,MapReduce,Shell, HTTP,Python等,基本足够普通调度需求了。
05 DS 触发 Kylin构建任务
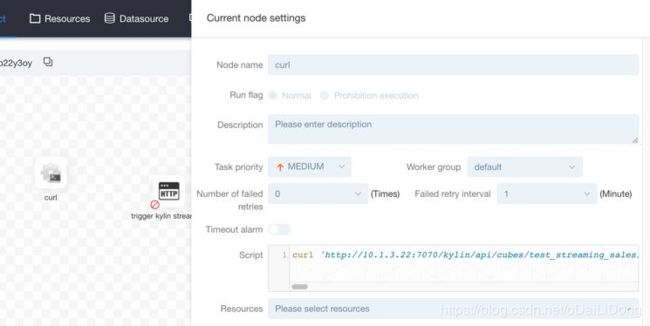
我们的测试场景是 Kylin 的流式构建,需要每五分钟触发一次任务;Kylin 提供 Rest API 供外部触发,但本身不提供调度器;通常用户使用外部调度器或 Linux cron 等服务来执行;使用 Linux cron 最简单,但是难以监控和修改,因此一些用户会觉得麻烦。所以我们可以集成 DS 和 Kylin 做到一站式调度和监控。这里触发Kylin的构建任务,可以用shell(如curl)命令,也可以用HTTP(post、put等)的方式进行;这里我选择用 shell 因为它非常简单,在输入之前,先确保这个shell命令是无误的,手动在Linux命令行中执行验证。
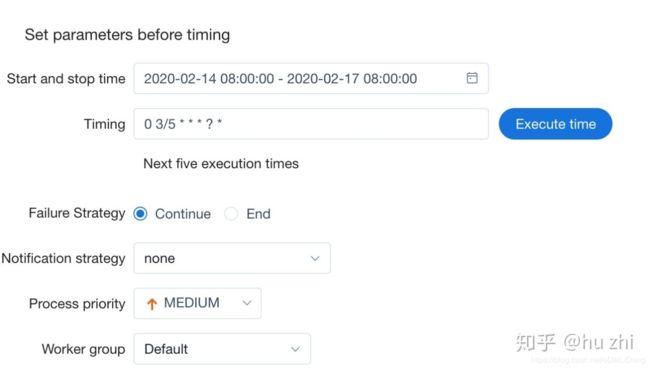
随后对这个进程指定定时器(cron),语法基本上跟Linux crontab相同,用户还可以指定生效范围,通知策略等:
06 运行
之后分别上线这个定时器,以及这个进程;过一会儿我们就会在平台上看到执行的任务:

执行的详细日志也是可以直接在线查看:
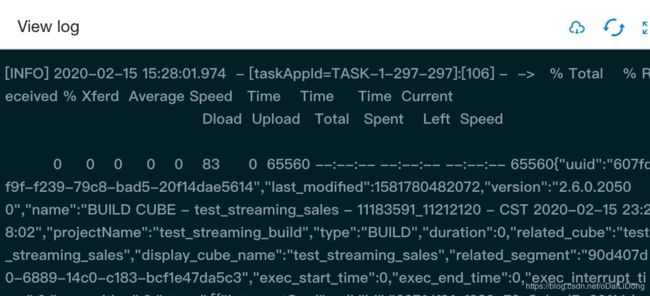
Kylin这边,我们看到任务被正常触发执行:
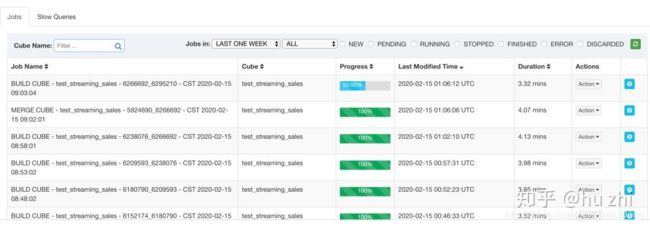
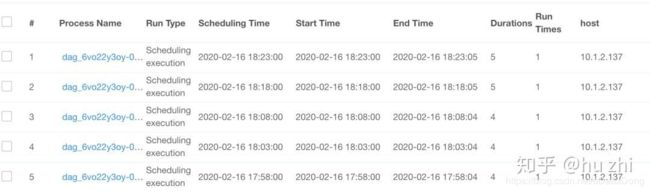
继续一天,两边平台都很稳定,180多次调度都成功执行:
07 总结
DolphinScheduler 是一款功能强大的大数据调度平台。一次配置好任务流,后续就可以靠DS自动定时调度了,任务成功或出错都可以得到邮件通知。如果任务较多,可以水平添加更多节点以扩展资源。Kylin上游通常有复杂的数据ETL过程,如Hive入库,数据清洗等;下游有报表刷新,邮件分发等;有了它可以方便地将大数据平台各组件串联起来,让各个任务通过DAG统一调度。此次时间有限没有进一步测试DS的高级功能,后续如果社区基于插件机制开发出Kylin的触发器,对用户会更加简单易用。
在此也非常感谢DolphinScheduler社区的代立冬等小伙伴,非常热心地帮忙回答和解决问题!
参考文件:
[1] http://www.clickhouse.com.cn/topic/5cab67b369c415035e68d526
[2] https://dolphinscheduler.apache.org/en-us/docs/release/download.html
[3] https://dolphinscheduler.apache.org/en-us/docs/1.2.0/user_doc/frontend-deployment.html
[4] https://dolphinscheduler.apache.org/en-us/docs/1.2.0/user_doc/backend-deployment.html
[5] https://dolphinscheduler.apache.org/en-us/docs/1.2.0/user_doc/quick-start.html