【集合系列】- 深入浅出分析 ArrayDeque
一、摘要
在 jdk1.5 中,新增了 Queue 接口,代表一种队列集合的实现,咱们继续来聊聊 java 集合体系中的 Queue 接口。
Queue 接口是由大名鼎鼎的 Doug Lea 创建,中文名为道格·利,关于这位大神,会在后期进行介绍,翻开 JDK1.8 源代码,可以将 Queue 接口旗下的实现类抽象成如下结构图:
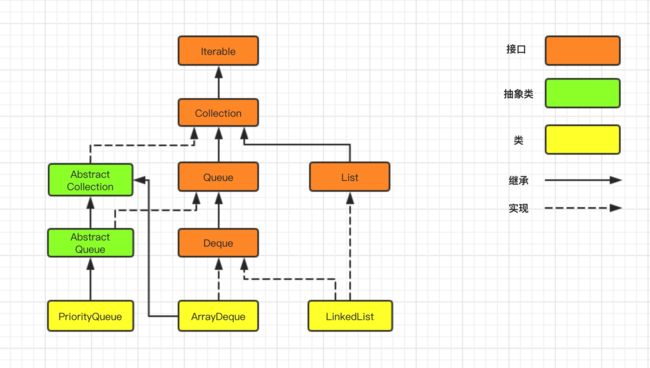
Queue 接口,主要实现类有:ArrayDeque、LinkedList、PriorityQueue。
关于 LinkedList 实现类,在之前的文章中已经有所介绍,今天咱们来介绍一下 ArrayDeque 这个类,如果有理解不当之处,欢迎指正。
二、简介
在介绍 ArrayDeque 类之前,可以从上图中看出,ArrayDeque 实现了 Deque 接口,Deque 是啥呢,全称含义为double ended queue,即双端队列。Deque 接口的实现类可以被当作 FIFO(队列)使用,也可以当作 LIFO(栈)来使用。
其中队列(FIFO)表示先进先出,比如水管,先进去的水先出来;栈(LIFO)表示先进后出,比如,手枪弹夹,最后进去的子弹,最先出来。
ArrayDeque 是 Deque 接口的一种具体实现,所以,既可以当成队列,也可以当成栈来使用,类定义如下:
public class ArrayDeque extends AbstractCollection
implements Deque, Cloneable, Serializable{
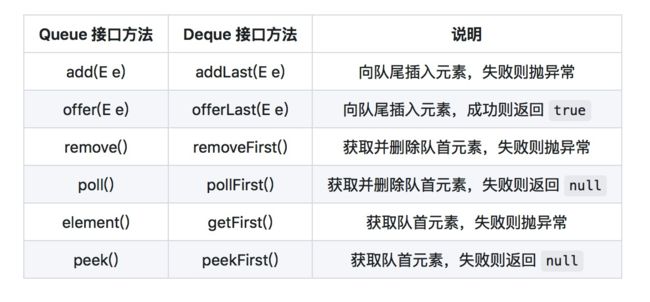
} 当作为队列使用时,我们会将它与 LinkedList 类来做对比,在后文,我们会做测试类来将两者进行详细数据对比。因为 Deque 接口继承自 Queue接口,在这里,我们分别列出两者接口所定义的方法,两者内容区别如下:
当作为栈使用时,难免会将它与 Java 中一个叫做 Stack 的类做比较,Stack 类的数据结构也是后进先出,可以作为栈来使用,我们分别列出 Stack 类和 Deque 接口所定义的方法,两者内容区别如下:
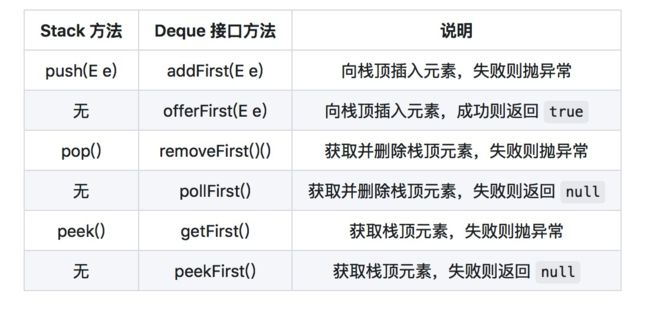
虽然,ArrayDeque 和 Stack 类都可以作为栈来使用,但是 ArrayDeque 的效率要高于 Stack 类,并且功能也比 Stack 类丰富的多,当需要使用栈时,Java 已不推荐使用 Stack,而是推荐使用更高效的 ArrayDeque,次选 LinkedList 。
从上面两张图中可以看出,Deque 总共定义了 2 组方法,添加、删除、取值都有两套方法,它们功能相同,区别是对失败情况的处理不同,一组方法是遇到失败会抛异常,另一组方法是遇到失败会返回null。
方法虽然定义的很多,但无非就是对容器的两端进行添加、删除、查询操作,明白这一点,那么使用起来就很简单了。
继续回到咱们要介绍的这个 ArrayDeque 类,从名字上可以看出 ArrayDeque 底层是通过数组实现的,为了满足可以同时在数组两端插入或删除元素的需求,该数组还必须是循环的,即循环数组,也就是说数组的任何一点都可能被看作起点或者终点。
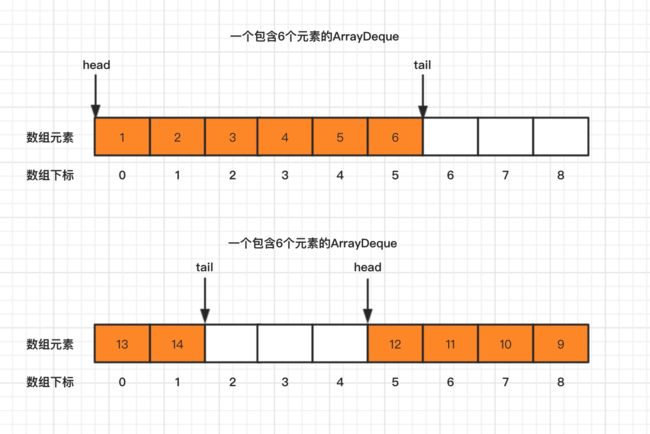
因为是循环数组,所以 head 不一定总是指向下标为 0 的数组元素,tail 也不一定总是比 head 大。
这一点,我们可以通过 ArrayDeque 源码分析得出这些结论,打开 ArrayDeque 的源码分析,可以看到,主要有3个关键参数:
- elements:用于存放数组元素。
- head:用于指向数组中头部下标。
- tail:用于指向数组中尾部下标。
public class ArrayDeque extends AbstractCollection
implements Deque, Cloneable, Serializable{
/**用于存放数组元素*/
transient Object[] elements;
/**用于指向数组中头部下标*/
transient int head;
/**用于指向数组中尾部下标*/
transient int tail;
/**最小容量,必须为2的幂次方*/
private static final int MIN_INITIAL_CAPACITY = 8;
} 与此同时,ArrayDeque 提供了三个构造方法,分别是默认容量,指定容量及依据给定的集合中的元素进行创建,其中默认容量为 16。
public ArrayDeque() {
//默认初始化数组大小为 16
elements = new Object[16];
}指定容量初始化方法,源码如下:
public ArrayDeque(int numElements) {
//指定容量
allocateElements(numElements);
}我们来看看指定容量调用的allocateElements方法,源码如下:
private void allocateElements(int numElements) {
elements = new Object[calculateSize(numElements)];
}calculateSize方法,源码如下:
private static int calculateSize(int numElements) {
//最小容量为 8
int initialCapacity = MIN_INITIAL_CAPACITY;
//如果容量大于8,比如是2的倍数
if (numElements >= initialCapacity) {
initialCapacity = numElements;
initialCapacity |= (initialCapacity >>> 1);
initialCapacity |= (initialCapacity >>> 2);
initialCapacity |= (initialCapacity >>> 4);
initialCapacity |= (initialCapacity >>> 8);
initialCapacity |= (initialCapacity >>> 16);
initialCapacity++;
//容量超出int 型最大范围,直接扩容到最大容量到 2 ^ 30
if (initialCapacity < 0)
initialCapacity >>>= 1;
}
return initialCapacity;
}ArrayDeque 默认初始化容量为 16,如果指定容量,必须是 2 的倍数,当数组容量超过 int 型最大范围时,直接扩容到最大容量到2 ^ 30。
三、常见方法介绍
3.1、添加方法
ArrayDeque,添加元素的方法有两种,一种是通过数组尾部下标进行添加,另一种是向数组头部下标进行添加。两种添加方式,按照处理方式的不同,一种处理方式是返回为空,另一种处理方式是成功返回true,两者共性是如果添加失败直接抛异常。
3.1.1、addLast 方法
addLast 方法,表示向尾部添加元素,操作如下图:
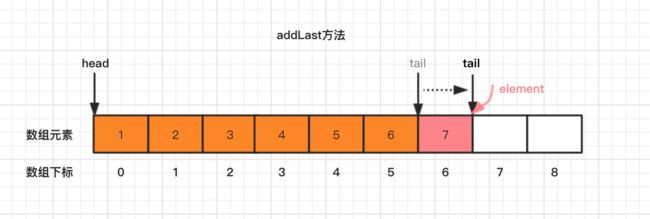
如果插入失败,就失败抛异常,同时添加的元素不能为空null,源码如下:
public void addLast(E e) {
//不允许放入null
if (e == null)
throw new NullPointerException();
elements[tail] = e;//将元素插入到尾部
//将尾部进行+1,判断下标是否越界
if ( (tail = (tail + 1) & (elements.length - 1)) == head)
//数组下标越界,进行扩容
doubleCapacity();
}值得注意的是(tail = (tail + 1) & (elements.length - 1)) == head这个方法,
可以把它拆成两个步骤,第一个步骤是计算tail数组尾部值,等于(tail + 1) & (elements.length - 1),这个操作是先对尾部参数进行+1处理,然后结合数组长度通过位运算得到尾部值,因为elements.length是2的倍数,所以,位运算类似做%得到其余数。
假设,elements.length等于16,测试如下:
public static void main(String[] args) {
int tail = 0;
int[] elements = new int[16];
for (int i = 0; i < elements.length; i++) {
tail = (tail + 1) & (elements.length - 1);
System.out.println("第" + (i+1) + "次计算,结果值:" + tail);
}
}输出结果:
第1次计算,结果值:1
第2次计算,结果值:2
第3次计算,结果值:3
第4次计算,结果值:4
第5次计算,结果值:5
第6次计算,结果值:6
第7次计算,结果值:7
第8次计算,结果值:8
第9次计算,结果值:9
第10次计算,结果值:10
第11次计算,结果值:11
第12次计算,结果值:12
第13次计算,结果值:13
第14次计算,结果值:14
第15次计算,结果值:15
第16次计算,结果值:0尾部下标从1、2、3、.....、14、15、0,依次按照顺序存储,当达到最大值之后,返回到头部,从 0 开始,结果是一个循环下标。
第二个步骤是判断tail == head是否相等,当计算处理的尾部下标循环到与头部下标重合的时候,说明数组长度已经装满,直接进行扩容处理。
我们来看看doubleCapacity()扩容这个方法,其逻辑是申请一个更大的数组(原数组的两倍),然后将原数组复制过去,流程图下:
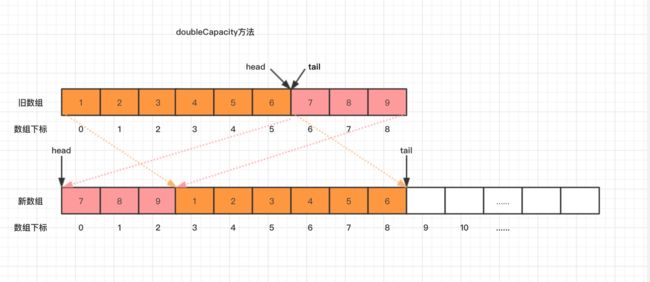
doubleCapacity()扩容源码如下:
private void doubleCapacity() {
//扩容时头部索引和尾部索引肯定相等
assert head == tail;
int p = head;
int n = elements.length;
//计算头部索引到数组末端(length-1处)共有多少元素
int r = n - p;
//容量翻倍,相当于 2 * n
int newCapacity = n << 1;
//容量过大,溢出了
if (newCapacity < 0)
throw new IllegalStateException("Sorry, deque too big");
//分配新空间
Object[] a = new Object[newCapacity];
//复制头部索引至数组末端的元素到新数组的头部
System.arraycopy(elements, p, a, 0, r);
//复制其余元素
System.arraycopy(elements, 0, a, r, p);
elements = a;
head = 0;
tail = n;
}复制数组分两次进行,第一次复制 head 头部索引至数组末端的元素到新数组,第二次复制 head 左边的元素到新数组。
3.1.2、offerLast 方法
offerLast 方法,调用了addLast()方法,两者不同之处,offerLast 有返回值,如果添加成功,则返回true,反之,抛异常;而 addLast 无返回值。
offerLast 方法源码如下:
public boolean offerLast(E e) {
addLast(e);
return true;
}3.1.3、addFirst 方法
addFirst 方法,与addLast()方法一样,都是向数组中添加元素,不同的是,addFirst 方法是向头部添加元素,与 addLast 方法正好相反,但是算法原理是一样。
addFirst 方法源码如下:
public void addFirst(E e) {
//不允许元素为 null
if (e == null)
throw new NullPointerException();
//使用头部参数计算下标
elements[head = (head - 1) & (elements.length - 1)] = e;
if (head == tail)
//如果头部与尾部重合,进行数组扩容
doubleCapacity();
}假设elements.length等于 16,我们来测试一下,通过 head 计算的数组下标值,测试方法如下:
public static void main(String[] args) {
int head = 0;
int[] elements = new int[16];
for (int i = 0; i < elements.length; i++) {
head = (head - 1) & (elements.length - 1);
System.out.println("第" + (i+1) + "次计算,结果值:" + head);
}
}输出结果:
第1次计算,结果值:15
第2次计算,结果值:14
第3次计算,结果值:13
第4次计算,结果值:12
第5次计算,结果值:11
第6次计算,结果值:10
第7次计算,结果值:9
第8次计算,结果值:8
第9次计算,结果值:7
第10次计算,结果值:6
第11次计算,结果值:5
第12次计算,结果值:4
第13次计算,结果值:3
第14次计算,结果值:2
第15次计算,结果值:1
第16次计算,结果值:0头部计算的下标从15、14、13、.....、2、1、0,依次从大到小按照顺序存储,当达到最小值之后,返回到头部,从 0 开始,结果也是一个循环下标。
具体实现流程与addLast流程正好相反,就不再赘述了。
3.1.4、offerFirst 方法
offerFirst 方法,调用了addFirst方法,两者不同之处,offerFirst 有返回值,如果添加成功,则返回true,反之,抛异常;而 addFirst 无返回值。
offerFirst 方法源码如下:
public boolean offerFirst(E e) {
addFirst(e);
return true;
}3.2、删除方法
ArrayDeque,删除元素的方法有两种,一种是通过数组尾部下标进行删除,另一种是通过数组头部下标进行删除。两种删除方式,按照处理方式的不同,一种处理方式是删除失败抛异常,另一种处理方式是删除失败返回null。
3.2.1、pollFirst 方法
pollFirst 方法,表示删除头部元素,并返回删除的元素。
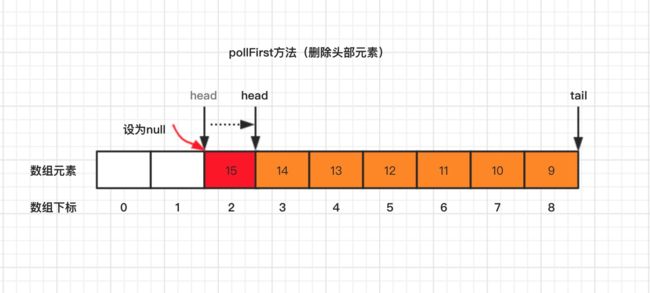
pollFirst 方法源码如下:
public E pollFirst() {
//获取数组头部
int h = head;
E result = (E) elements[h];
//判断头部元素是否为空
if (result == null)
return null;
//设为null,方便GC回收
elements[h] = null;
//向上移动头部元素
head = (h + 1) & (elements.length - 1);
return result;
}pollFirst 方法是先获取数组头部元素,判断元素是否存在,如果不存在,直接返回null,如果存在,将其设为null,并返回元素。
3.2.2、removeFirst 方法
removeFirst 方法,调用了pollFirst方法,两者不同的是,removeFirst 方法,如果删除元素失败会抛异常,而 pollFirst 方法会返回null,源码如下:
public E removeFirst() {
E x = pollFirst();
//返回为null ,抛异常
if (x == null)
throw new NoSuchElementException();
return x;
}3.2.3、pollLast 方法
pollLast 方法,与pollFirst方法正好相反,对数组尾部元素进行删除,并返回元素。
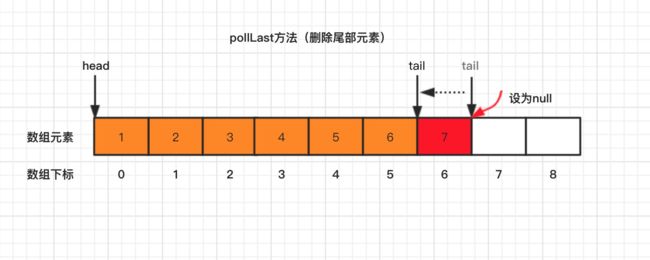
pollLast 方法,源码如下:
public E pollLast() {
//通过尾部计算数组下标
int t = (tail - 1) & (elements.length - 1);
E result = (E) elements[t];
//判断是否为空
if (result == null)
return null;
//设为null
elements[t] = null;
tail = t;
return result;
}pollLast 方法是先通过数组尾部计算数组元素下标,判断元素是否存在,如果不存在,直接返回null,如果存在,将其设为null,并返回元素。
3.2.4、removeLast 方法
removeLast 方法,调用了pollLast方法,两者不同的是,removeLast 方法,如果删除元素失败会抛异常,而 pollLast 方法会返回null,源码如下:
public E removeLast() {
E x = pollLast();
//返回为null ,抛异常
if (x == null)
throw new NoSuchElementException();
return x;
}3.3、查询方法
ArrayDeque,查询元素的方法也有两种,一种是通过数组尾部下标进行获取,另一种是通过数组头部下标进行获取。两种查询方式,按照处理方式的不同,一种处理方式是查询失败抛异常,另一种处理方式是查询失败返回null。
3.3.1、peekFirst 方法
peekFirst 方法,表示通过数组头部获取数组元素,可能返回null,源码如下:
public E peekFirst() {
//可能返回null
return (E) elements[head];
}3.3.2、getFirst 方法
getFirst 方法,表示通过数组头部获取数组元素,如果返回null则抛异常,源码如下:
public E getFirst() {
E result = (E) elements[head];
//查询返回null ,抛异常
if (result == null)
throw new NoSuchElementException();
return result;
}3.3.3、peekLast 方法
peekLast 方法,表示通过数组尾部获取数组元素,可能返回null,源码如下:
public E peekFirst() {
//可能返回null
return (E) elements[(tail - 1) & (elements.length - 1)];
}3.3.4、getLast 方法
getLast 方法,表示通过数组尾部获取数组元素,如果返回null则抛异常,源码如下:
public E getLast() {
//获取数组尾部下标
E result = (E) elements[(tail - 1) & (elements.length - 1)];
//查询返回null,抛异常
if (result == null)
throw new NoSuchElementException();
return result;
}四、性能比较
ArrayDeque 和 LinkedList 都是 Deque 接口的实现类,都具备既可以作为队列,又可以作为栈来使用的特性,两者主要区别在于底层数据结构的不同。
ArrayDeque 底层数据结构是以循环数组为基础,而 LinkedList 底层数据结构是以循环链表为基础。理论上,链表在添加、删除方面性能高于数组结构,在查询方面数组结构性能高于链表结构,但是对于数组结构,如果不进行数组移动,在添加方面效率也很高。
下面,分别以10万条数据为基础,通过添加、删除,来测试两者作为队列、栈使用时所消耗的时间。
4.1、ArrayDeque性能测试
4.1.1、作为队列
public static void main(String[] args) {
ArrayDeque arrayDeque = new ArrayDeque<>();
long addStart = System.currentTimeMillis();
//向队列尾部插入 10W 条数据
for (int i = 0; i < 100000; i++) {
arrayDeque.addLast(i + "");
}
long result1 = System.currentTimeMillis() - addStart;
System.out.println("向队列尾部插入10W条数据耗时:" + result1);
//获取并删除队首元素
long deleteStart = System.currentTimeMillis();
while (true){
String content = arrayDeque.pollFirst();
if(content == null){
break;
}
}
long result2 = System.currentTimeMillis() - deleteStart;
System.out.println("\n从头部删除队列10W条数据耗时:" + result2);
System.out.println("队列元素总数:" + arrayDeque.size());
} 输出结果:
向队列尾部插入10W条数据耗时:59
从队列头部删除10W条数据耗时:4
队列元素总数:04.1.2、作为栈
public static void main(String[] args) {
ArrayDeque arrayDeque = new ArrayDeque<>();
long addStart = System.currentTimeMillis();
//向栈顶插入 10W 条数据
for (int i = 0; i < 100000; i++) {
arrayDeque.addFirst(i + "");
}
long result1 = System.currentTimeMillis() - addStart;
System.out.println("向栈顶插入10W条数据耗时:" + result1);
//获取并删除栈顶元素
long deleteStart = System.currentTimeMillis();
while (true){
String content = arrayDeque.pollFirst();
if(content == null){
break;
}
}
long result2 = System.currentTimeMillis() - deleteStart;
System.out.println("从栈顶删除10W条数据耗时:" + result2);
System.out.println("栈元素总数:" + arrayDeque.size());
} 输出结果:
向栈顶插入10W条数据耗时:61
从栈顶删除10W条数据耗时:3
栈元素总数:04.2、LinkedList
4.2.1、作为队列
public static void main(String[] args) {
LinkedList linkedList = new LinkedList();
long addStart = System.currentTimeMillis();
//向队列尾部插入 10W 条数据
for (int i = 0; i < 100000; i++) {
linkedList.addLast(i + "");
}
long result1 = System.currentTimeMillis() - addStart;
System.out.println("向队列尾部插入10W条数据耗时:" + result1);
//获取并删除队首元素
long deleteStart = System.currentTimeMillis();
while (true){
String content = linkedList.pollFirst();
if(content == null){
break;
}
}
long result2 = System.currentTimeMillis() - deleteStart;
System.out.println("从队列头部删除10W条数据耗时:" + result2);
System.out.println("队列元素总数:" + linkedList.size());
} 输出结果:
向队列尾部插入10W条数据耗时:70
从队列头部删除10W条数据耗时:5
队列元素总数:04.2.2、作为栈
public static void main(String[] args) {
LinkedList linkedList = new LinkedList();
long addStart = System.currentTimeMillis();
//向栈顶插入 10W 条数据
for (int i = 0; i < 100000; i++) {
linkedList.addFirst(i + "");
}
long result1 = System.currentTimeMillis() - addStart;
System.out.println("向栈顶插入10W条数据耗时:" + result1);
//获取并删除栈顶元素
long deleteStart = System.currentTimeMillis();
while (true){
String content = linkedList.pollFirst();
if(content == null){
break;
}
}
long result2 = System.currentTimeMillis() - deleteStart;
System.out.println("从栈顶删除10W条数据耗时:" + result2);
System.out.println("栈元素总数:" + linkedList.size());
} 输出结果:
向栈顶插入10W条数据耗时:71
从栈顶删除10W条数据耗时:5
栈元素总数:04.3、总结
我们分别以10万条数据、100万条数据、1000万条数据来测试,两个类在作为队列和栈方面的性能,可能因为机器的不同,每个机器的测试结果不同,本次使用的是 mac 机器,测试结果如下图:
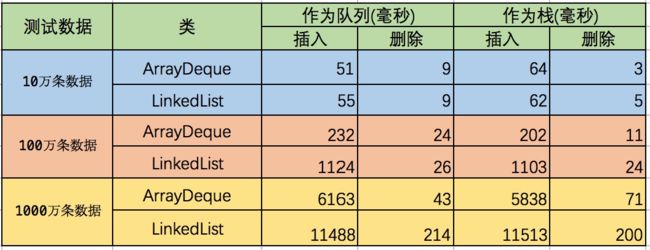
从数据上可以看出,在 10 万条数据下,两者性能都差不多,当达到 100 万条、1000 万条数据的时候,两者的差别就比较明显了,ArrayDeque 无论是作为队列还是作为栈使用,性能均高于 LinkedList 。
为什么 ArrayDeque 性能,在大数据量的时候,明显高于 LinkedList?
个人分析,我们曾在集合系列文章中提到过 LinkedList,LinkedList 底层是以循环链表来实现的,每一个节点都有一个前驱、后继的变量,也就是说,每个节点上都存放有它上一个节点的指针和它下一个节点的指针,同时还包括它自己的元素,在同等的数据量情况下,链表的内存开销要明显大于数组,同时因为 ArrayDeque 底层是数组结构,天然在查询方面在优势,在插入、删除方面,只需要移动一下头部或者尾部变量,时间复杂度是 O(1)。
所以,在大数据量的时候,LinkedList 的内存开销明显大于 ArrayDeque,在插入、删除方面,都要频发修改节点的前驱、后继变量;而 ArrayDeque 在插入、删除方面依然保存高性能。
如果对于小数据量,ArrayDeque 和 LinkedList 在效率方面相差不大,但是对于大数据量,推荐使用 ArrayDeque。
五、总结
ArrayDeque 底层基于循环数组实现,既可以作为队列使用,又可以作为栈来使用。
ArrayDeque 作为栈的时候,经常会将它与 Stack 做对比,Stack 也是一个可以作为栈使用的类,但是 Java 已不推荐使用它,如果要使用栈,推荐使用更高效的 ArrayDeque。
与此同时,ArrayDeque 和 LinkedList 都是 Deque 接口的实现类,两者差别在于底层数据结构的不同,LinkedList 底层基于循环链表实现,内存开销高于 ArrayDeque,在小数据量的时候,两者效率差别不大;在大数据量的时候,ArrayDeque 性能高于 LinkedList,推荐使用 ArrayDeque 类。
还有一个不同的地方是,ArrayDeque 不允许插入null,而 LinkedList 允许插入null;同时,两者都是非线程安全的,如果在多线程环境下,建议使用 Java 并发工具包里面的操作类。
六、参考
1、JDK1.7&JDK1.8 源码
2、知乎 - CarpenterLee -Java ArrayDeque源码剖析