七、利用ik分词器 + kibana + logstash 向es 中导入mysql数据,并索引
一、向 es 中安装ik分词器插件
第一步:去https://github.com/medcl/elasticsearch-analysis-ik/releases?after=v5.5.3该网址下载对应版本的ik分词器(下zip版,不要下成source版)
第二步:在es的plugins下新建ik目录
第三步:解压ik分词器压缩包至ik目录
第四步:验证ik分词器
在linux中输入:curl -XGET 'http://10.202.105.41:9200/_analyze?pretty&analyzer=ik_max_word' -d '联想是全球最大的笔记本厂商',出现如下记录,则成功!
{
"tokens" : [
{
"token" : "联想",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "是",
"start_offset" : 2,
"end_offset" : 3,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "全球",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "最大",
"start_offset" : 5,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "的",
"start_offset" : 7,
"end_offset" : 8,
"type" : "CN_CHAR",
"position" : 4
},
{
"token" : "笔记本",
"start_offset" : 8,
"end_offset" : 11,
"type" : "CN_WORD",
"position" : 5
},
{
"token" : "笔记",
"start_offset" : 8,
"end_offset" : 10,
"type" : "CN_WORD",
"position" : 6
},
{
"token" : "本厂",
"start_offset" : 10,
"end_offset" : 12,
"type" : "CN_WORD",
"position" : 7
},
{
"token" : "厂商",
"start_offset" : 11,
"end_offset" : 13,
"type" : "CN_WORD",
"position" : 8
}
]
}
二、安装启动kibana
(一)去官网下载包
(二)解压
(三)配置kibana.yml
server.port: 5601
server.host: 0.0.0.0
//配置与elasticsearch相连
elasticsearch.url: "http://localhost:9200"
kibana.index: ".kibana"
(四)启动
./kibana 1>/dev/null 2>&1 &
(五)浏览器访问
1、开启5601端口
/sbin/iptables -I INPUT -p tcp --dport 5601 -j ACCEPT&&/etc/init.d/iptables save&&service iptables restart&&/etc/init.d/iptables status
2、访问
http://192.168.10.130:5601/
三、Linux中关闭Kibana进程
使用如下命令都无法查询到kibana的PID:
ps -ef | grep kibana
ps -ef | grep 5601
经过实践,使用如下方法可以查询到kibana的PID:
ps -ef | grep node
#第一个即为查询到的Kibana进程id
root 7877 7487 15 11:02 pts/1 00:00:07 ./../node/bin/node --no-warnings ./../src/cli
root 7891 7487 0 11:03 pts/1 00:00:00 grep --color=auto node
#关闭kibana
kill -9 7877
三、安装logstash并同步mysql中数据
(一)安装
1.下载logstash下载之后直接解压,开箱即用
我这里使用的是6.2.2
2.下载logstash后查看是否安装成功
进入到logstash目录下bin目录,注意这里一定需要以root用户登录(切换用户可以输入命令 su root,输入密码可以切换用户root)
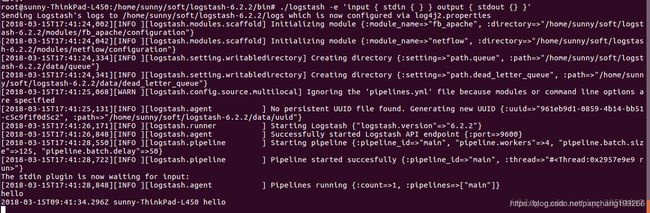
./logstash -e 'input { stdin { } } output { stdout {} }'
需要等大概10秒钟,等待直到显示Pipeline started succesfully,
你可以随意输入 hello word(任意字符串)
输出你输入的字符串,如下图
 3、下载mysql驱动,下载网址:https://dev.mysql.com/downloads/file/?id=480090,使用
3、下载mysql驱动,下载网址:https://dev.mysql.com/downloads/file/?id=480090,使用 mysql-connector-java-6.2.2-bin.jar这一个jar包
(二)同步并索引mysql数据
备注:需要被同步的mysql容许远程访问,比如windows上的mysql容许远程访问需要设置如下,参见 mysql如何修改开启允许远程连接 (windows)
1.在kibana中创建索引
PUT booklist
{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1
},
"mappings": {
"doc" : {
"dynamic" : "false",
"properties": {
"id":{
"type": "integer"
},
"title":{
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"content":{
"type": "text",
"store": false,
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"createDate":{
"type": "date",
"index": false,
"store": false,
"format": ["yyyy-MM-dd HH:mm:ss"]
}
}
}
}
}
2.新建mysql与es交互的配置文件
cd到logstash目录bin目录下,新建文件夹config-mysql,打开并写入mysql.conf文件内容:
input {
stdin{
}
jdbc {
// mysql 数据库链接,test为数据库名
jdbc_connection_string => "jdbc:mysql://192.168.10.1:3306/test"
// 用户名和密码
jdbc_user => "root"
jdbc_password => "root"
// 驱动(需单独下载)
jdbc_driver_library => "/usr/local/mysql-connector-java-6.2.2-bin.jar"
// 驱动类名
jdbc_driver_class => "com.mysql.jdbc.Driver"
//处理中文乱码问题
codec => plain {charset => "UTF-8"}
//使用其它字段追踪,而不是用时间(这里是用来实现增量更新的)
use_column_value => true
//追踪的字段
tracking_column => id
//是否记录上次执行结果, 如果为真,将会把上次执行到的 tracking_column 字段的值记录下来,保存到 last_run_metadata_path 指定的文件中
record_last_run => true
//上一个sql_last_value值的存放文件路径, 必须要在文件中指定字段的初始值
last_run_metadata_path => "/usr/local/logstash-6.2.2/bin/config-mysql/station_parameter.txt"
#sql_last_value每次读取last_run_metadata_path中存放的值,下面语句增量更新是按照id值递增的顺序同步mysql中的内容
statement => "select * from booklist where id > :sql_last_value"
//开启分页查询
jdbc_paging_enabled => true
jdbc_page_size => 300
//设置监听间隔 各字段含义(由左至右)分、时、天、月、年,全部为*默认含义为每分钟都更新
schedule => "* * * * *"
}
}
filter {
json {
source => "message"
remove_field => ["message"]
}
#下面:当使用Logstash自动生成的mapping模板时过滤掉@timestamp和@version字段
mutate {
remove_field =>
["@timestamp","@version"]
}
output {
elasticsearch {
#hosts:一般是localhost:9200
hosts => ["localhost:9200"]
index => "*****"
#表示按照id同步mysql数据
document_id => "%{id}"
document_type => "****"
#下面两个参数表明加载我自己配置的Mapping模板,包括可以自行设置中文分词等
template_overwrite => true
template => "/usr/YEE/logstash-6.3.2/MySqlYee/*****/template/*****_test1_ik.json"
}
stdout {
codec => json_lines
}
}
参数介绍:
//是否记录上次执行结果, 如果为真,将会把上次执行到的 tracking_column 字段的值记录下来,保存到 last_run_metadata_path 指定的文件中
record_last_run => true
//是否需要记录某个column 的值,如果 record_last_run 为真,可以自定义我们需要 track 的 column 名称,此时该参数就要为 true. 否则默认 track 的是 timestamp 的值.
use_column_value => true
//如果 use_column_value 为真,需配置此参数. track 的数据库 column 名,该 column 必须是递增的.比如:ID.
tracking_column => MY_ID
//指定文件,来记录上次执行到的 tracking_column 字段的值
//比如上次数据库有 10000 条记录,查询完后该文件中就会有数字 10000 这样的记录,下次执行 SQL 查询可以从 10001 条处开始.
//我们只需要在 SQL 语句中 WHERE MY_ID > :last_sql_value 即可. 其中 :last_sql_value 取得就是该文件中的值(10000).
last_run_metadata_path => "G:\Developer\Elasticsearch5.5.1\ES5\logstash-5.5.1\bin\mysql\station_parameter.txt"
//是否清除 last_run_metadata_path 的记录,如果为真那么每次都相当于从头开始查询所有的数据库记录
clean_run => false
//是否将 column 名称转小写
lowercase_column_names => false
//存放需要执行的 SQL 语句的文件位置
statement_filepath => "G:\Developer\Elasticsearch5.5.1\ES5\logstash-5.5.1\bin\mysql\jdbc.sql"
3、新建station_parameter.txt
4.测试同步数据
进入bin目录下,输入命令(如果不加--path.data=/root/会报错,多个实例时需要加上path.data才可以哦, 这里也要是root用户登录)
./logstash -f config-mysql/mysql.conf --path.data=/root/
5、查询索引数据
GET /booklist/_search
{
"query": {
"term": {
"title": {
"value": "套装"
}
}
},
"from": 0,
"size": 3
}
(三)同步过程中的异常处理
1、报错如下:
[2018-03-22T14:17:42,271][WARN ][logstash.outputs.elasticsearch] Could not index event to Elasticsearch. {:status=>400, :action=>["index", {:_id=>"%{houseId}", :_index=>"house", :_type=>"doc", :_routing=>nil}, #], :response=>{"index"=>{"_index"=>"house", "_type"=>"doc", "_id"=>"%{houseId}", "status"=>400, "error"=>{"type"=>"illegal_argument_exception", "reason"=>"Rejecting mapping update to [house] as the final mapping would have more than 1 type: [booklist, doc]"}}}}
原因是我自己在创建索引映射的时候的索引类型设置为booklist,但是logstash在同步的时候会自动创建一个doc类型的index,所以引起冲突,解决方式可以修改自己的索引映射为doc,这样就不会发生冲突了,参见如下:
PUT booklist
{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1,
"analysis": {
"analyzer": {
"ik" : {
"tokenizer" : "ik_max_word"
}
}
}
},
"mappings": {
"doc" : {
"dynamic" : "false",
"properties": {
"id":{
"type": "integer"
},
"title":{
"type": "text"
},
"content":{
"type": "text",
"store": false
},
"createDate":{
"type": "date",
"index": false,
"store": false
}
}
}
}
}