【GNN】PinSAGE:GCN 在工业级推荐系统中的应用
今天学习的是 Pinterest 和斯坦福大学 2018 年合作的论文《Graph Convolutional Neural Networks for Web-Scale Recommender Systems》,目前有 200 多次引用。
论文中提出的 PinSAGE 结合了随机游走和 GCN 来生成节点的 Embedding 向量。同时考虑了图结构和节点的特征信息。此外,PinSAGE 也设计了一种新颖的训练策略,该策略可以提高模型的鲁棒性并加快模型的收敛。
这篇论文是 GraphSAGE 一次成功的应用,也是 GCN 在大规模工业网络中的一个经典案例,为基于 GCN 结构的新一代 Web 级推荐系统铺平了道路。
1.Introduction
GCN 在图数据中扮演着举足轻重的角色,其背后的核心思想在于使用神经网络来聚合领域的特征信息,并且通过堆叠可以扩大节点的感受野。与纯粹基于内容的深度模型(例如,递归神经网络)不同,GCN 会利用内容信息以及图结构。基于 GCN 的方法刷新很多的任务的 SOTA(state of the art),但是目前很多模型都尚未转化到实际生产环境中。
GCN 在工业中应用的主要挑战在于如何在数十亿节点和数百亿边的网络中高效完成训练,对此论文提出了以下几种改进措施:
- 动态卷积:通过对节点的领域进行采样构建计算图来执行高效局部卷积,从而减轻训练期间对整个图进行操作的需要;
- 生产者-消费者批处理构建:通过 mini-batch 来确保模型在训练期间最大限度的利用 GPU;
- 高效的 MapReduce:实际一种高效的 MapReduce 通道用于分发经过训练的模型以生成数十亿节点,同时最大程度地减少重复计算。
除了提高 GCN 的可扩展性外,作者还设计了新的训练方式和算法创新,提高了 Embedding 的质量,从而在下游任务中带来显著的性能提升:
- 通过随机游走构建卷积:利用短随机游走对图进行采样来代替随机采样;
- Importance Pooling:基于随机游走相似性度量引入节点的特征重要性权重,并根据权重进行聚合;
- 课程学习(Curriculum Learning):由 Bengio 在 2009 年提出,主要是模仿人类学习的特征,由简到难的来学习课程。在机器学习领域就是先训练容易区分样本,在训练难以区分的样本。
接下来我们看下算法具体的实现。
2.PinSAGE
本节我们介绍下 PinSAGE 架构和训练过程中的技术细节,以及 MapReduce 的通道。
先介绍下难点:
2.1 Model Architecture
我们先来总览下模型架构:

PinSAGE 使用的是两层局部卷积模块来生成节点的 Embedding。左上角为图示例,右边是一个两层的神经网络,用来计算节点 A 的 Embedding 向量。底部是节点的输入,每个节点具有不同的输入,但是共享神经网络的输入。
下图为局部卷积操作的前向传播算法的伪代码,也是 PinSAGE 算法的核心:

- 输入是节点 u 的 Embedding z u z_u zu,以及节点邻居的 Embedding 集合 { z v ∣ v ∈ N ( u ) } \{z_v | v \in N(u)\} {zv∣v∈N(u)},还有邻居的权重集合 { α v ∣ v ∈ N ( u ) } \{\alpha_v | v\in N(u) \} {αv∣v∈N(u)},聚合函数 γ ( ⋅ ) \gamma(\cdot) γ(⋅);
- 输出是节点 u 的新 Embedding 向量 z u n e w z_u^{new} zunew;
- 第 1 行是利用节点 u 的邻居的 Embedding 向量、权重和聚合函数来得到节点 u 邻居的向量表征;
- 第 2 行是拼接当前节点和邻居的向量表征后通过神经网络得到节点 u 新的 Embedding 向量(根据经验选择了拼接而不是平均);
- 第 3 行是归一化操作,主要是为了使训练更加稳定,并且归一化后的进行最近邻搜索更加有效。
邻居重要性:区别于以往 GCN 考虑 k-hop 图邻域,PinSAGE 定义了基于重要性的邻域。具体来说,利用节点 u 开始随机游走,并计算基于随机游走访问到的节点次数,并将访问次数最高的 K 个节点作为邻域。这样做的优点在于,聚合节点的数量固定有助于控制训练的内存;其次在聚合邻居节点时可以进行加权聚合;
堆叠卷积:使用多层卷积进行叠加,第 k 层卷积的输入取决于第 k-1 层的输出,模型参数在层内共享,在层间相互独立。
算法 2 介绍了训练过程中 mini-batch:

- 输入为小批量节点集合 M;深度为 K;
- 输出为 Embedding z u z_u zu;
- 第 1 行到第 7 行为集合 M 中的节点计算节点邻域,这边注意遍历顺序(K…1),这和 GraphSAGE 一个道理;
- 第 8 行到第 14 行为 K 层卷积操作;
- 第 15 行到第 17 行为模型的最终输出。
2.2 Model Training
损失函数:为了训练模型,作者采用了一个类似 Hinge Loss 的损失函数,考虑边距最大。具体来说就是最大化正样本的内积(可以理解为最大化正样本间的相似度),并且正负样本间的距离要比正样本间的距离要大。所以损失函数为:
J G ( z q , z i ) = E n k ∽ P n ( q ) m a x { 0 , z q ⋅ z n k − z q ⋅ z i + Δ } J_G(z_q,z_i) = E_{n_k\backsim P_n(q)}max\{ 0, z_q \cdot z_{n_k} - z_q \cdot z_i + \Delta \} \\ JG(zq,zi)=Enk∽Pn(q)max{0,zq⋅znk−zq⋅zi+Δ}
其中,输入为正样本的节点对 ( z q , z i ) : ( q , i ) ∈ L (z_q,z_i):(q,i) \in L (zq,zi):(q,i)∈L, ( q , i ) (q, i) (q,i) 表示用户与 q 交互后立即与 i 进行交互,下文对 q 称为查询项目; P n ( q ) P_n(q) Pn(q) 表示查询项 q 的负样本集合; Δ \Delta Δ 为超参,用于控制距离。负样本的采样下面会介绍。
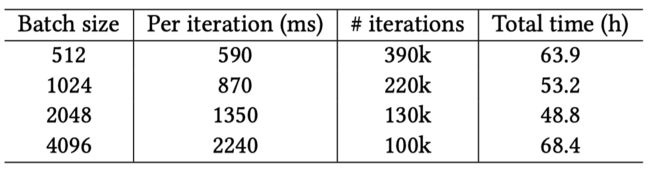
多 GPU 训练:为了能够在单台机器上充分利用多个 GPU 进行训练,作者以多塔(Mulit-tower)的方式训练前向和反向传播。对于多个 GPU,首先将每个 mini-batch (模型架构图的底部)划分为相等大小,每个 GPU 将负责一部分 mini-batch,并使用相同的参数来进行计算。在反向传播时,汇聚所有 GPU 上每个参数的梯度然后执行同步的 SGD 运算。作者针对 Pinterest 的数据规模将 mini-batch 的大小设置为 512 到 4096 之间。此外,作者还参考了引用[2]中 Goyal等人的工作,从而确保批处理训练时能更快收敛,并有更好的泛化精度。
生产者-消费者批处理构建:在训练过程中,数十亿节点的邻居表和特征矩阵都会被放在 CPU 的内存中,但是 PinSAGE 卷积计算是在 GPU 中进行的,从 GPU 访问 CPU 内存数据效率不高。为了解决这个问题,作者使用重新索引的技术来创建一个包含节点及其邻域的子图 G ′ = ( V ′ , E ′ ) G^{'}=(V^{'},E^{'}) G′=(V′,E′) 邻接表,该子图将参与当前 mini-batch 的计算中。此外,也会提取一个与当前 mini-batch 计算相关的节点特征的小特征矩阵,并且保证其使用顺序与子图中的节点索引顺序一致。在每次 mini-batch 计算开始时,子图 G ′ G^{'} G′ 邻接表和小特征矩阵都会被送到 GPU 中,这样就不需要在卷积计算的过程中进行 CPU 和 GPU 的通信,从而大大提高了 GPU 的利用率,并减少了将近一半的训练时间。
负样本采样:为了提高训练效率,作者为每个 mibi-batch 采样了 500 个负样本,即 mini-batch 中的样本共享这 500 个负样本。与单独为每个节点进行负采样相比,其结果几乎没有什么差异。对于这 500 个负样本来说,最简单的方法就是随便找 500 个样本,但是这样并不能体现出正负样本间的差异。为了解决这个问题,作者为每个正样本对设计了“硬性”的负样本。比如,对于每对训练样本 ( q , i ) (q,i) (q,i) 来说,强负样本为与查询项目 q 相关,但是与正样本 i 不相关的样本。强负样本主要来源为基于查询项 q 的个性化 Pagerank 得分,并对排名在 2000-5000 的项目中进行随机采样。下图分别展示了查询项、正样本、随机负样本、强负样本:

课程学习(Curriculum Learning):但是在训练过程中,使用强负样本会使得模型收敛所需时间加倍。为了解决这个问题,作者引入 Curriculum Learning 的训练方式,在每个 epochs 中,第一个阶段不使用强负样本,而使用课程学习的方式进行训练,该算法可以在参数空间中快速找到损失相对较小的区域,随后再使用强样本进行训练。
2.3 Node Embeddings via MapReduce
完成训练后,直接对所有 item 进行 Embedding 仍是一个比较大的挑战,包括是对于那些未知的 item(冷启动问题)。
使用算法 2 来计算节点的 Embedding 会导致很多的重复计算(k hop 会有邻域重叠),所以为了确保有效的计算节点的 Embedding,作者设计了一种 MapReduce 方法,这种方法将不会涉及重复计算。
下图展示了节点 Embedding 数据流的 MapReduce 计算。

MapReduce 算法主要利用算法 1,并分为两个部分:
- 首先是利用 MapReduce 作业将所有节点都映射到一个低维空间,并计算出节点的邻域采样和权重(算法 1 的第 1 行);
- 然后利用另一个 MapReduce 作业进行前向传播,通过合并(采样后)邻居的特征来计算节点的 Embedding。多层网络重复计算即可,最后一层结果为最终的表征向量。
2.4 Efficient nearest-neighbor lookups
作者主要通过计算 query 和 item 的 Embedding 向量的 k-近邻来进行推荐。考虑计算复杂度,这里使用的是局部敏感哈希的方式来近似获得 k-近邻,并使用基于弱 AND 运算的两级检索过程来实现 item 的检索。详细细节不进行介绍,感兴趣的可以看论文及其参考文献。
3.Experiment
简单看一下实验部分。
首先是 PinSAGE 与其他算法的相似度对比,胜率都在 50% 以上:

可视化展示:
衡量 Embedding 有效性的另一个指标是:考虑随机的 Item 之间的相似度距离分分布比较广,如果所有节点对的距离大致相同则区分度不足。下图为不同模型的计算节点对相似度的概率密度函数,可以看到 PinSAGE 的相似度距离分布更加广泛:

下图为 PinSAGE 和其他模型的命中率和 MRR,可以看到 PinSAGE 的命中率提高了 150%,MRR 提高了 60%。

下图为利用 t-SNE 的可视化展示:
还有训练一些参数敏感性实验:

4.Conclusion
总结:作者提出了一种基于随机游走的 GCN 算法 PinSAGE,PinSAGE 具有高度可扩展性,并且能够适配数十亿节点和数百亿边的网络。除了保证高度可扩展性外,作者还引入 Importance Pooling 和 Curriculum Learning 的技术大大提高了模型的性能和收敛速度,从实验结果表明 PinSAGE 显著了提升了推荐系统的效果。
5.Reference
- 《Graph Convolutional Neural Networks for Web-Scale Recommender Systems》
- 《Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour》
- 《Presented Slide》
关注公众号跟踪最新内容:阿泽的学习笔记。
