Kyin学习笔记(一)-----Kylin安装、入门案例和原理介绍
目录
一、Kylin简介
1、Kylin的诞生背景
2、Kylin的应用场景
3、为什么要使用Kylin
4、Kylin的总体架构
二、Kylin安装
1、依赖环境
2、集群规划
3、安装kylin-2.6.3-bin-hbase1x
4、集群模式部署(官网)
三、入门案例
1、测试数据表结构介绍
2、操作步骤
3、按照日期统计订单总额/总数量(Hive方式)
4、按照日期统计订单总额/总数量(Kylin方式)
1、创建项目(Project) (HMaster 不用 会挂,Hive 挂掉也 创建不了)
2、创建数据源(DataSource)
3、创建模型(Model)
4. 创建立方体(Cube)
5、按照订单渠道名称统计订单总额/总数量
Hive中的语句:
Kylin开发步骤
5、按照日期、区域、产品维度统计订单总额/总数量
Kylin开发步骤
四、Kylin的工作原理
1、维度和度量
2、Cube和Cuboid
3、工作原理
一、Kylin简介
Apache Kylin™是一个开源的、分布式的分析型数据仓库,提供Hadoop/Spark 之上的 SQL 查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由 eBay 开发并贡献至开源社区。它能在亚秒内查询巨大的表。(官网:http://kylin.apache.org/cn/)
1、Kylin的诞生背景
- ebay-中国团队研发的,是第一个真正由中国人自己主导、从零开始、自主研发、并成为Apache顶级开源项目
- Hive的性能比较慢,支持SQL灵活查询,特别慢
- HBase的性能快,原生不支持SQL
- Kylin是将先将数据进行预处理,将预处理的结果放在HBase中。效率很高
2、Kylin的应用场景
Kylin 典型的应用场景如下:
- 用户数据存在于Hadoop HDFS中,利用Hive将HDFS文件数据以关系数据方式存取,数据量巨大,在500G以上
- 每天有数G甚至数十G的数据增量导入
- 有10个以内较为固定的分析维度
Kylin 的核心思想是利用空间换时间(笔记本耗内存),在数据 ETL 导入 OLAP 引擎时提前计算各维度的聚合结果并持久化保存

麒麟官网:http://kylin.apache.org/
3、为什么要使用Kylin
Kylin 是一个 Hadoop 生态圈下的
MOLAP(多维度联机事务分析)系统,是 ebay 大数据部门从2014 年开始研发的支持 TB 到 PB 级别数据量的分布式 Olap 分析引擎。
特点包括:
- 可扩展的超快的 OLAP 引擎
- 提供 ANSI-SQL 接口交互式查询能力
- MOLAP Cube 的概念
- 与 BI 工具可无缝整合
Kylin 的优势(美团)
第一,性能非常稳定。因为 Kylin 依赖的所有服务,比如 Hive、HBase 都是非常成熟的,Kylin 本身的逻辑并不复杂,所以稳定性有一个很好的保证。目前在我们的生产环境中,稳定性可以保证在 99.99% 以上。同时查询时延也比较理想。我们现在有一个业务线需求,每天查询量在两万次以上,95% 的时延低于 1 秒,99% 在 3 秒以内。基本上能满足我们交互式分析的需求。
第二,对我们特别重要的一点,就是数据的精确性要求。其实现在能做到的只有 Kylin,所以说我们也没有什么太多其他的选择。
第三,从易用性上来讲,Kylin 也有非常多的特点。首先是外围的服务,不管是 Hive 还是 HBase,只要大家用 Hadoop 系统的话基本都有了,不需要额外工作。在部署运维和使用成本上来讲,都是比较低的。其次,有一个公共的 Web 页面来做模型的配置。相比之下 Druid 现在还是基于配置文件来做。这里就有一个问题,配置文件一般都是平台方或者管理员来管理的,没办法把这个配置系统开放出去,这样在沟通成本和响应效率上都不够理想。Kylin 有一个通用的 Web Server 开放出来,所有用户都可以去测试和定义,只有上线的时候需要管理员再 review 一下,这样体验就会好很多。
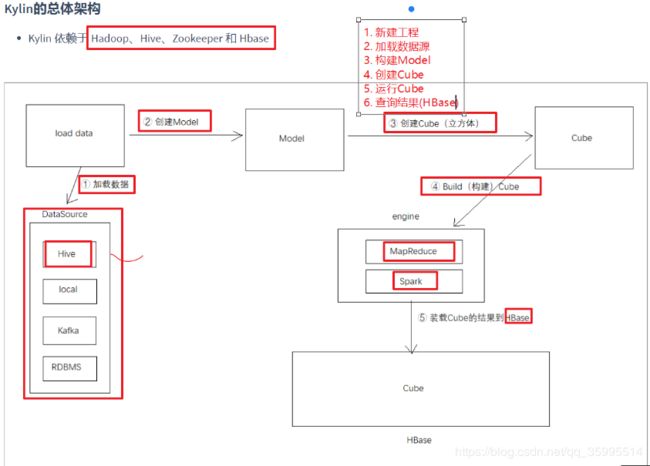
4、Kylin的总体架构
Kylin 依赖于 Hadoop、Hive、Zookeeper 和 Hbase
二、Kylin安装
1、依赖环境
| 软件 | 版本 |
|---|---|
| Apache hbase-1.1.1-bin.tar.gz | 1.1.1 |
| apache-kylin-2.6.3-bin-hbase1x.tar.gz | 2.6.3 |

2、集群规划
| 主机名 | IP | 守护进程 |
|---|---|---|
| node01 | 192.168.100.10 | NameNode DataNode RunJar(Hive metastore) RunJar(Hive hiveserver2) QuorumPeerMain HMaster HRegionServer kylin NodeManager |
| node2 | 192.168.100.11 | SecondaryNameNode JobHistoryServer DataNode HRegionServer QuorumPeerMain ResourceManager HistoryServer NodeManager |
| node3 | 192.168.100.12 | HRegionServer NodeManager DataNode QuorumPeerMain |
注意:
kylin-2.6.3-bin-hbase1x所依赖的hbase必须是Apache为1.1.1版本- 要求hbase的 hbase.zookeeper.quorum() 值必须只能是host1,host2,...。不允许出现host:2181,...

3、安装kylin-2.6.3-bin-hbase1x
## 解压apache-kylin-2.6.3-bin-hbase1x.tar.gz
tar -zxf /export/softwares/apache-kylin-2.6.3-bin-hbase1x.tar.gz -C /export/servers/1. 增加 kylin 依赖组件的配置
cd /export/servers/apache-kylin-2.6.3-bin-hbase1x/conf
# 添加下列软链接
ln -s $HADOOP_HOME/etc/hadoop/hdfs-site.xml hdfs-site.xml
ln -s $HADOOP_HOME/etc/hadoop/core-site.xml core-site.xml
ln -s $HBASE_HOME/conf/hbase-site.xml hbase-site.xml
ln -s $HIVE_HOME/conf/hive-site.xml hive-site.xml
ln -s $SPARK_HOME/conf/spark-defaults.conf spark-defaults.conf2. 配置kylin.sh
cd /export/servers/apache-kylin-2.6.3-bin-hbase1x/bin
vim kylin.sh
kylin.sh文件添加如下内容:
export HADOOP_HOME=/export/servers/hadoop-2.6.0-cdh5.14.0
export HIVE_HOME=/export/servers/hive-1.1.0-cdh5.14.0
export HBASE_HOME=/export/servers/hbase-1.1.1
export SPARK_HOME=/export/servers/spark-2.2.0-bin-hadoop2.6
3. 配置 conf/kylin.properties
修改 配置文件kylin.properties 中HDFS的路径,然后上传到 Linux的 Kylin/conf文件夹中
#### METADATA | ENV ###
#
## The metadata store in hbase
#kylin.metadata.url=kylin_metadata@hbase
#
## metadata cache sync retry times
#kylin.metadata.sync-retries=3
#
## Working folder in HDFS, better be qualified absolute path, make sure user has the right permission to this directory
kylin.env.hdfs-working-dir=/apps/kylin
#
## DEV|QA|PROD. DEV will turn on some dev features, QA and PROD has no difference in terms of functions.
#kylin.env=QA
#
## kylin zk base path
kylin.env.zookeeper-base-path=/kylin
kylin.source.hive.keep-flat-table=false
#
## Hive database name for putting the intermediate flat tables
kylin.source.hive.database-for-flat-table=default
#
## Whether redistribute the intermediate flat table before building
kylin.source.hive.redistribute-flat-table=true
#
#
#### STORAGE ###
#
## The storage for final cube file in hbase
kylin.storage.url=hbase
#
## The prefix of hbase table
kylin.storage.hbase.table-name-prefix=KYLIN_
#
## The namespace for hbase storage
kylin.storage.hbase.namespace=default
#
## Compression codec for htable, valid value [none, snappy, lzo, gzip, lz4]
kylin.storage.hbase.compression-codec=none
#
#
#### SPARK ENGINE CONFIGS ###
#
## Hadoop conf folder, will export this as "HADOOP_CONF_DIR" to run spark-submit
## This must contain site xmls of core, yarn, hive, and hbase in one folder
kylin.env.hadoop-conf-dir=/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
#
## Estimate the RDD partition numbers
kylin.engine.spark.rdd-partition-cut-mb=10
#
## Minimal partition numbers of rdd
kylin.engine.spark.min-partition=1
#
## Max partition numbers of rdd
kylin.engine.spark.max-partition=1000
#
## Spark conf (default is in spark/conf/spark-defaults.conf)
kylin.engine.spark-conf.spark.master=yarn
kylin.engine.spark-conf.spark.submit.deployMode=cluster
kylin.engine.spark-conf.spark.yarn.queue=default
kylin.engine.spark-conf.spark.driver.memory=512M
kylin.engine.spark-conf.spark.executor.memory=1G
kylin.engine.spark-conf.spark.executor.instances=2
kylin.engine.spark-conf.spark.yarn.executor.memoryOverhead=512
kylin.engine.spark-conf.spark.shuffle.service.enabled=true
kylin.engine.spark-conf.spark.eventLog.enabled=true
kylin.engine.spark-conf.spark.eventLog.dir=hdfs://node1:8020/apps/spark2/spark-history
kylin.engine.spark-conf.spark.history.fs.logDirectory=hdfs://node1:8020/apps/spark2/spark-history
kylin.engine.spark-conf.spark.hadoop.yarn.timeline-service.enabled=false
#
#### Spark conf for specific job
kylin.engine.spark-conf-mergedict.spark.executor.memory=1G
kylin.engine.spark-conf-mergedict.spark.memory.fraction=0.2
#
## manually upload spark-assembly jar to HDFS and then set this property will avoid repeatedly uploading jar at runtime
kylin.engine.spark-conf.spark.yarn.archive=hdfs://node1:8020/apps/spark2/lib/spark-libs.jar
kylin.engine.spark-conf.spark.io.compression.codec=org.apache.spark.io.SnappyCompressionCodec
4. 初始化kylin在hdfs上的数据路径
hdfs dfs -mkdir hdfs://node01:8020/apps/kylin5. 启动集群
1、启动zookeeper
2、启动HDFS
3、启动YARN集群
4、启动HBase集群
start-hbase.sh
5、启动 metastore
nohup hive --service metastore &
6、启动 hiverserver2
nohup hive --service hiveserver2 &
7、启动Yarn history server
mr-jobhistory-daemon.sh start historyserver
8、启动spark history server【可选】
sbin/start-history-server.sh
9、启动kylin
./kylin.sh start

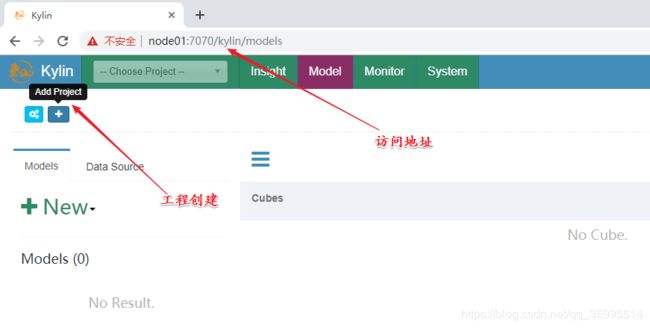
登录Kylin
http://node01:7070/kylin
| url | http://IP:7070/kylin |
|---|---|
| 默认用户名 | ADMIN |
| 默认密码 | KYLIN |
用户名和密码都必须是大写
4、集群模式部署(官网)
Kylin 实例是无状态的服务,运行时的状态信息存储在 HBase metastore 中。 出于负载均衡的考虑,您可以启用多个共享一个 metastore 的 Kylin 实例,使得各个节点分担查询压力且互为备份,从而提高服务的可用性。下图描绘了 Kylin 集群模式部署的一个典型场景:
Kylin 集群模式部署
如果您需要将多个 Kylin 节点组成集群,请确保他们使用同一个 Hadoop 集群、HBase 集群。然后在每个节点的配置文件
$KYLIN_HOME/conf/kylin.properties中执行下述操作:
- 配置相同的
kylin.metadata.url值,即配置所有的 Kylin 节点使用同一个 HBase metastore。- 配置 Kylin 节点列表
kylin.server.cluster-servers,包括所有节点(包括当前节点),当事件变化时,接收变化的节点需要通知其他所有节点(包括当前节点)。- 配置 Kylin 节点的运行模式
kylin.server.mode,参数值可选all,job,query中的一个,默认值为all。job模式代表该服务仅用于任务调度,不用于查询;query模式代表该服务仅用于查询,不用于构建任务的调度;all模式代表该服务同时用于任务调度和 SQL 查询。注意:默认情况下只有一个实例用于构建任务的调度 (即
kylin.server.mode设置为all或者job模式)。任务引擎高可用
从 v2.0 开始, Kylin 支持多个任务引擎一起运行,相比于默认单任务引擎的配置,多引擎可以保证任务构建的高可用。
使用多任务引擎,你可以在多个 Kylin 节点上配置它的角色为
job或all。为了避免它们之间产生竞争,需要启用分布式任务锁,请在kylin.properties里配置:kylin.job.scheduler.default=2 kylin.job.lock=org.apache.kylin.storage.hbase.util.ZookeeperJobLock并记得将所有任务和查询节点的地址注册到
kylin.server.cluster-servers。安装负载均衡器
为了将查询请求发送给集群而非单个节点,您可以部署一个负载均衡器,如 Nginx, F5 或 cloudlb 等,使得客户端和负载均衡器通信代替和特定的 Kylin 实例通信。
读写分离部署
为了达到更好的稳定性和最佳的性能,建议进行读写分离部署,将 Kylin 部署在两个集群上,如下:
- 一个 Hadoop 集群用作 Cube 构建,这个集群可以是一个大的、与其它应用共享的集群;
- 一个 HBase 集群用作 SQL 查询,通常这个集群是专门为 Kylin 配置的,节点数不用像 Hadoop 集群那么多,HBase 的配置可以针对 Kylin Cube 只读的特性而进行优化。
这种部署策略是适合生产环境的最佳部署方案,关于如何进行读写分离部署,请参考 Deploy Apache Kylin with Standalone HBase Cluster。

三、入门案例
1、测试数据表结构介绍
(事实表)dw_sales
| 列名 | 列类型 | 说明 |
|---|---|---|
| id | string | 订单id |
| date1 | string | 订单日期 |
| channelid | string | 订单渠道(商场、京东、天猫) |
| productid | string | 产品id |
| regionid | string | 区域名称 |
| amount | int | 商品下单数量 |
| price | double | 商品金额 |
(维度表_渠道方式)dim_channel
| 列名 | 列类型 | 说明 |
|---|---|---|
| channelid | string | 渠道id |
| channelname | string | 渠道名称 |
(维度表_产品名称)dim_product
| 列名 | 列类型 | 说明 |
|---|---|---|
| productid | string | 产品id |
| productname | string | 产品名称 |
(维度表_区域)dim_region
| 列名 | 类类型 | 说明 |
|---|---|---|
| regionid | string | 区域id |
| regionname | string | 区域名称 |
导入测试数据
为了方便后续学习Kylin的使用,需要准备一些测试表、测试数据。
- Hive中创建库
- Hive中创建表
- 将数据从本地文件导入到Hive
2、操作步骤
1、使用 beeline 连接Hive
!connect jdbc:hive2://node01:100002、创建 kylin_dw 数据库
create database kylin_dw;
use kylin_dw;3、执行sql、创建测试表
-- 1、销售表:dw_sales
-- id 唯一标识
-- date1 日期
-- channelId 渠道 ID
-- productId 产品 ID
-- regionId 区域 ID
-- amount 数量
-- price 金额
create table dw_sales(
id string,
date1 string,
channelId string,
productId string,
regionId string,
amount int,
price double)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' stored as textfile;
-- 2、渠道表:dim_channel
-- channelId 渠道ID
-- channelName 渠道名称
create table dim_channel(
channelId string,
channelName string )
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' stored as textfile;
-- 3、产品表:dim_product
create table dim_product(
productId string,
productName string )
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' stored as textfile;
--4、区域表:dim_region
create table dim_region(
regionId string,
regionName string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' stored as textfile;
-- 查看表是否创建成功
show tables;4、将测试数据文件上传到Linux, 导入数据到表中
-- 导入数据
LOAD DATA LOCAL INPATH '/export/datas/kylin_demos/dw_sales_data.txt' OVERWRITE INTO TABLE dw_sales;
LOAD DATA LOCAL INPATH '/export/datas/kylin_demos/dim_channel_data.txt' OVERWRITE INTO TABLE dim_channel;
LOAD DATA LOCAL INPATH '/export/datas/kylin_demos/dim_product_data.txt' OVERWRITE INTO TABLE dim_product;
LOAD DATA LOCAL INPATH '/export/datas/kylin_demos/dim_region_data.txt' OVERWRITE INTO TABLE dim_region;
# dim_channel_data.txt
01,商场
02,京东
03,天猫
# dim_product_data.txt
01,meta20
02,p30
03,ihpone Xs
04,小米 9
# dim_region_data.txt
010,北京
021,上海
# dw_sales_data.txt
0001,2019-02-01,01,01,010,1,3400.00
0002,2019-02-01,02,02,021,2,6800.00
0003,2019-02-01,01,01,010,1,3400.00
0004,2019-02-01,01,02,021,1,3400.00
0005,2019-02-01,02,01,010,1,3400.00
0006,2019-02-01,01,01,021,2,6800.00
0007,2019-02-01,03,02,010,1,3400.00
0008,2019-02-01,01,01,021,1,3400.00
0009,2019-02-01,01,03,010,1,3400.00
0010,2019-02-01,02,01,021,3,10200.00
0011,2019-02-01,01,04,010,1,3400.00
0012,2019-02-01,03,01,021,1,3400.00
0013,2019-02-01,01,04,010,1,3400.00
0014,2019-02-02,01,01,010,1,3400.00
0015,2019-02-02,02,02,021,2,6800.00
0016,2019-02-02,01,01,010,1,3400.00
0017,2019-02-02,01,02,021,1,3400.00
0018,2019-02-02,02,01,010,1,3400.00
0019,2019-02-02,01,01,021,2,6800.00
0020,2019-02-02,03,02,010,1,3400.00
0021,2019-02-02,01,01,021,1,3400.00
0022,2019-02-02,01,03,010,1,3400.00
0023,2019-02-02,02,01,021,3,10200.00
0024,2019-02-02,01,04,010,1,3400.00
0025,2019-02-02,03,01,021,1,3400.00
0026,2019-02-02,01,04,010,1,3400.00
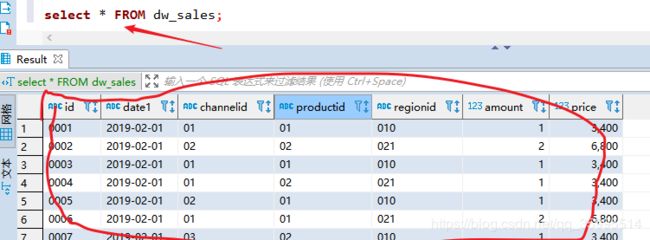
0027,2019-02-02,01,04,010,1,3400.005. 执行一条SQL语句,确认数据是否已经成功导入
select * from dw_sales;
3、按照日期统计订单总额/总数量(Hive方式)
操作步骤:
1. 切换到 kylin_dw 数据库
use kylin_dw;2. 在代码目录中创建sql文件,编写SQL语句
select
date1,
sum(price) as total_money,
sum(amount) as total_amount
from dw_sales
group by date1;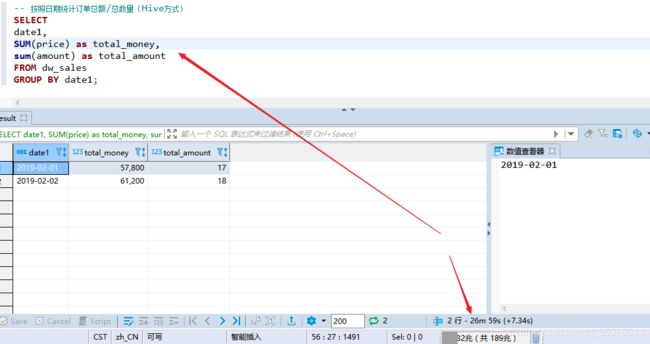
4、按照日期统计订单总额/总数量(Kylin方式)
要使用Kylin进行OLAP分析,需要按照以下方式来进行。
1、创建项目(Project) (HMaster 不用 会挂,Hive 挂掉也 创建不了)


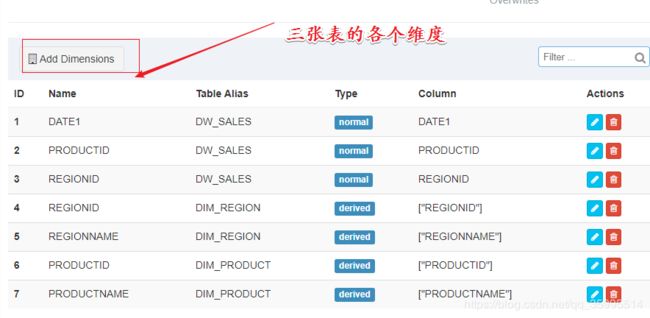
2、创建数据源(DataSource)
- 将Hive中的表都导入到Kylin中
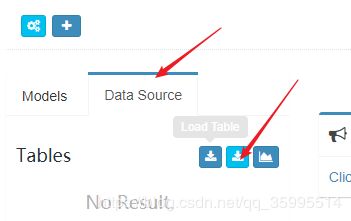
- 添加数据库,指定表名

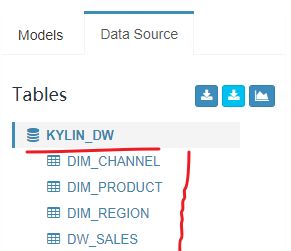
- 选择库之后就可以看到各个表
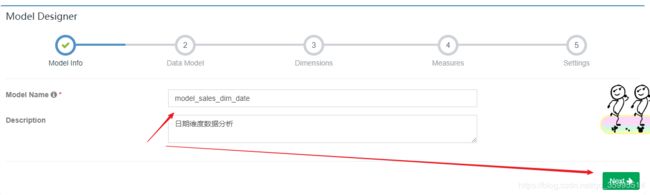
3、创建模型(Model)
- 指定模型名称
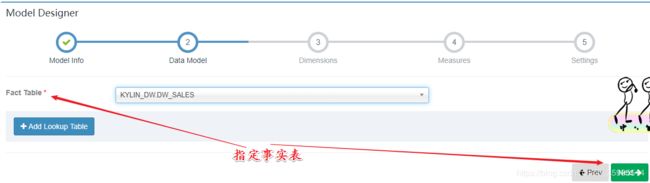
- 指定事实表
- 指定维度列
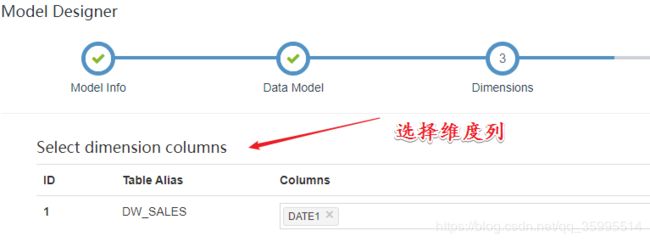
- 指定待分析的指标
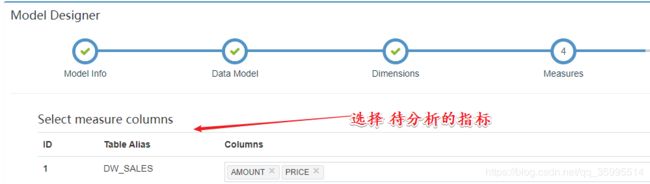
- 指定分区和过滤条件
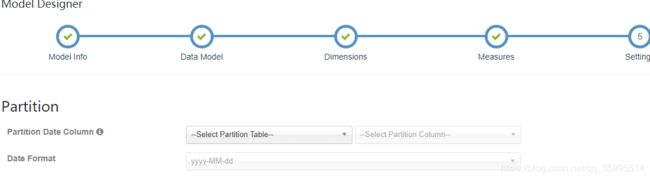
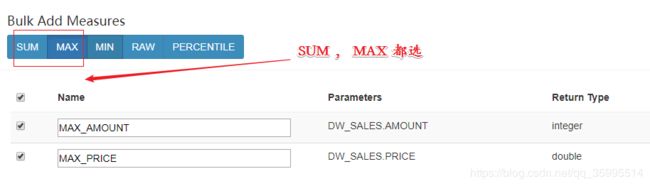
4. 创建立方体(Cube)
1. 选择数据模型
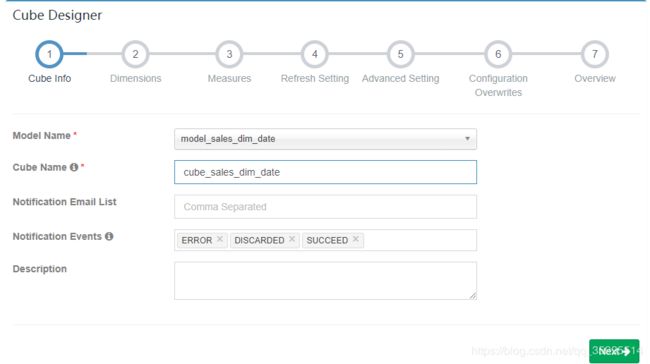
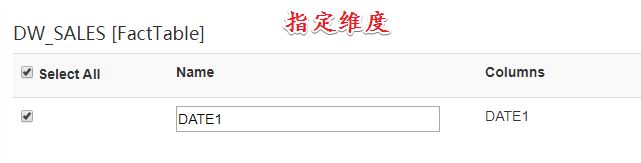
2. 指定维度
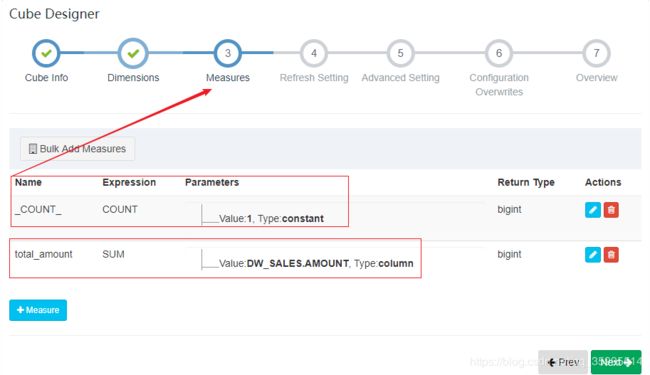
3. 指定度量

4. 指定刷新设置
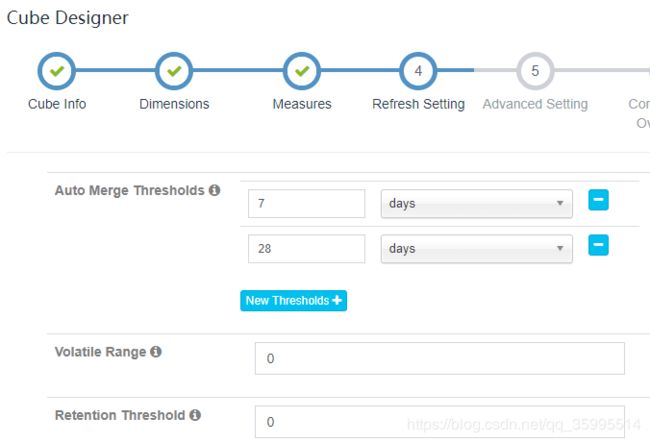
5. 指定执行引擎
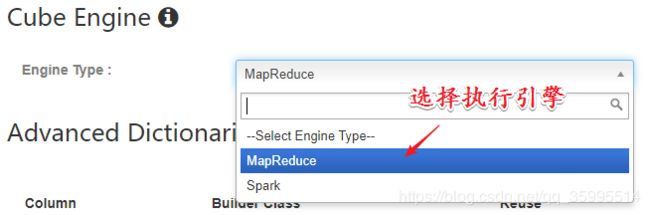
6. 执行构建并等待完成
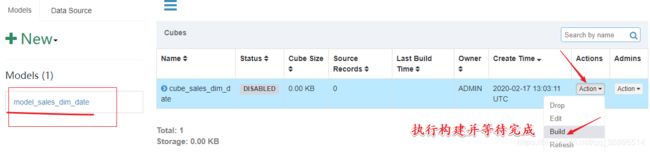
点击顶部导航栏 Monitor 可以观察运行进度
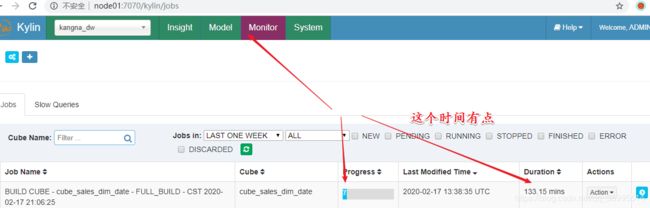
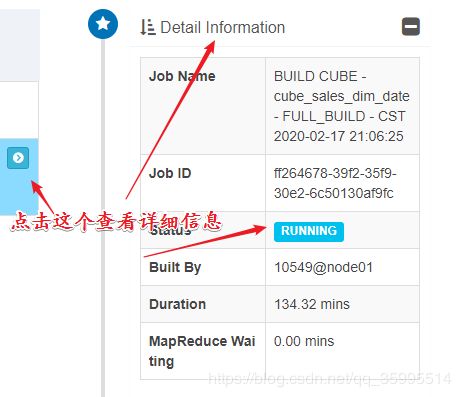
执行SQL语句分析
select
date1,
sum(price) as total_money,
sum(amount) as total_amount
from
dw_sales
group by date1;5、按照订单渠道名称统计订单总额/总数量
Hive中的语句:
select
t2.channelid,
t2.channelname,
sum(t1.price) as total_money,
sum(t1.amount) as total_amount
from
dw_sales t1
inner join dim_channel t2
on t1.channelid = t2.channelid
group by t2.channelid, t2.channelnameKylin开发步骤
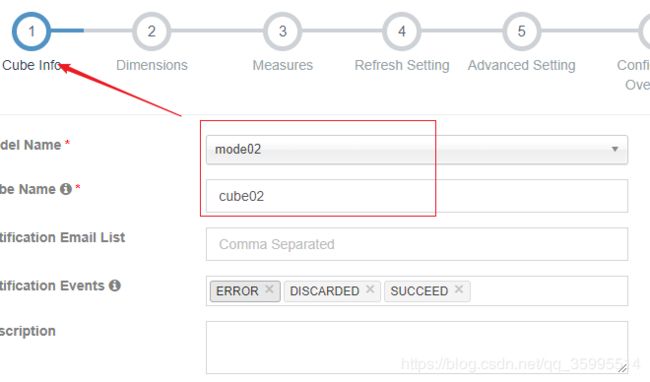
1、创建Model
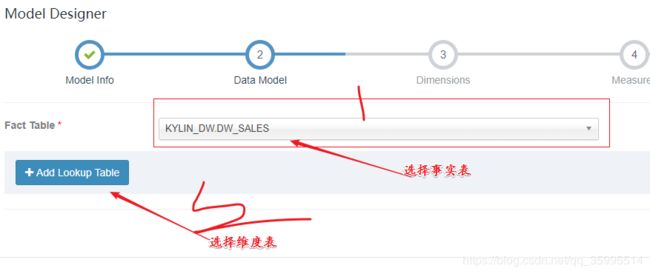
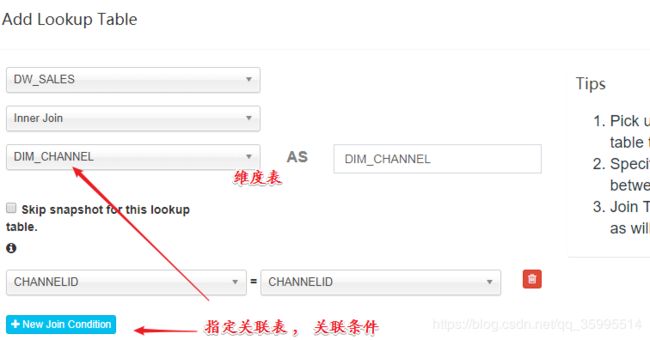
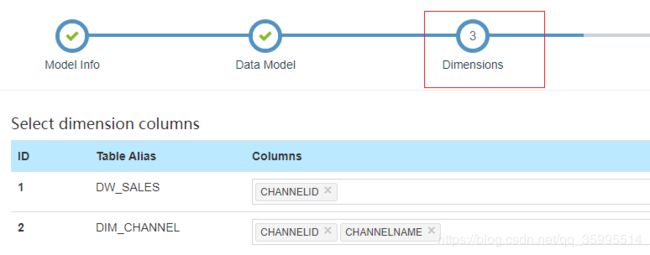
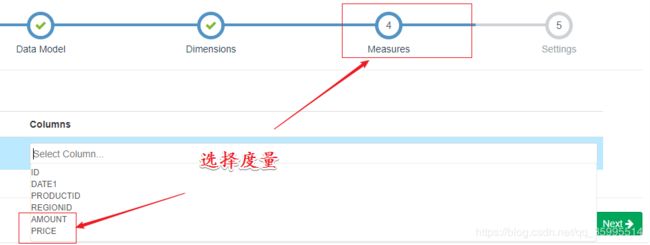
2、创建Cube
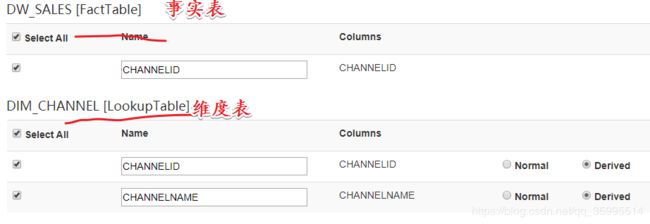
维度表 选择
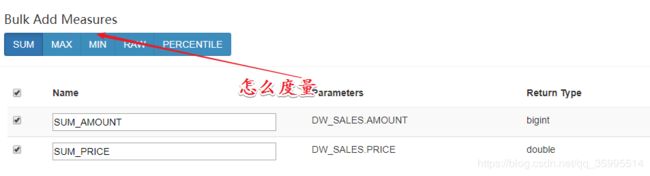
后面选择引擎保存就可以了
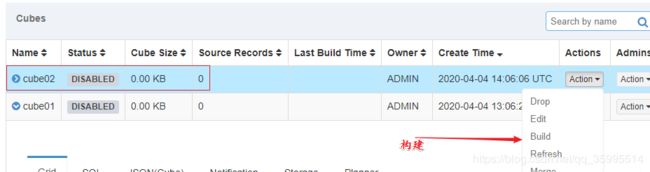
3、执行构建、等待构建完成
4、执行SQL查询,获取结果
select
t2.channelid,
t2.channelname,
sum(t1.price) as total_money,
sum(t1.amount) as total_amount
from
dw_sales t1
inner join dim_channel t2
on t1.channelid = t2.channelid
group by t2.channelid, t2.channelname5、按照日期、区域、产品维度统计订单总额/总数量
Hive查询语句
select
t1.date1,
t2.regionid,
t2.regionname,
t3.productid,
t3.productname,
sum(t1.price) as total_money,
sum(t1.amount) as total_amount
from
dw_sales t1
inner join dim_region t2
on t1.regionid = t2.regionid
inner join dim_product t3
on t1.productid = t3.productid
group by
t1.date1,
t2.regionid,
t2.regionname,
t3.productid,
t3.productnameKylin开发步骤
1、创建Model
指定维度字段
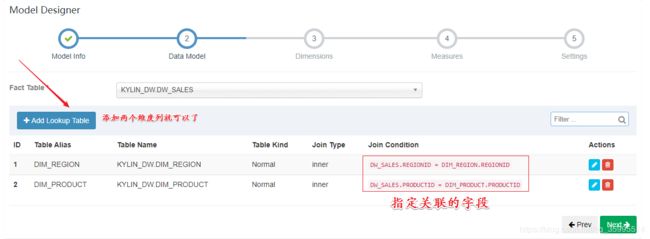
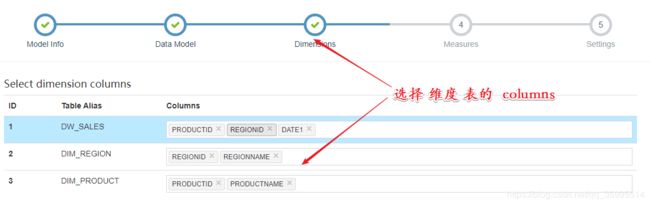
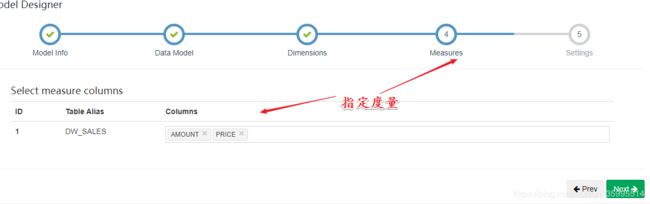
next --- save
2、创建Cube
指定cube维度
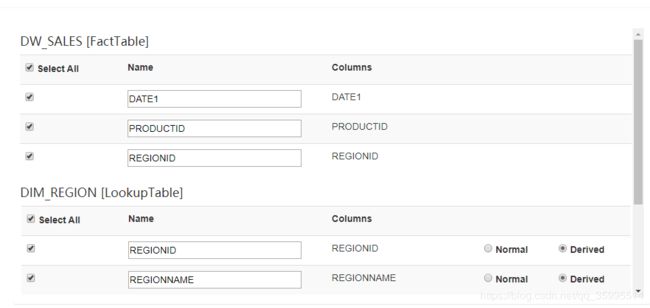
next --- -save
3、执行构建、等待构建完成

4、执行SQL查询,获取结果
select
t1.date1,
t2.regionid,
t2.regionname,
t3.productid,
t3.productname,
sum(t1.price) as total_money,
sum(t1.amount) as total_amount
from
dw_sales t1
inner join dim_region t2
on t1.regionid = t2.regionid
inner join dim_product t3
on t1.productid = t3.productid
group by
t1.date1,
t2.regionid,
t2.regionname,
t3.productid,
t3.productname
order by
t1.date1,
t2.regionname,
t3.productname时间对比
| 环境(单机) | 时间 |
|---|---|
| Hive | 42s |
| Hive本地模式 | 6s |
| Spark-Sql | 8.7s |
| Kylin | 0.1s |
四、Kylin的工作原理
Apache Kylin的工作原理本质上是 MOLAP Cube(多维立方体分析)。
MOLAP : Multidimension OLAP
1、维度和度量
-
维度就是观察数据的角度,例如:
-
电商的销售数据,可以从时间的维度来观察,也可以细化从时间和地区的维度来观察
-
统计时,可以把维度值相同的记录聚合在一起,然后应用聚合函数做累加、平均、去重计数等聚合计算
-
-
度量就是被聚合的统计值,也是聚合运算的结果。
| 时间(维度) | 销售额(度量) |
|---|---|
| 2019 1Q | 1.7M |
| 2019 2Q | 2.1M |
| 2019 3Q | 1.6M |
| 2019 4Q | 1.8M |
| 时间(维度) | 地区(维度) | 销售额(度量) |
|---|---|---|
| 2019 1Q | 中国 | 1.0M |
| 2019 1Q | 北美 | 0.7M |
| 2019 2Q | 中国 | 1.5M |
| 2019 2Q | 北美 | 0.6M |
| 2019 3Q | 中国 | 0.9M |
| 2019 3Q | 北美 | 0.7M |
| 2019 4Q | 中国 | 0.9M |
| 2019 4Q | 北美 | 0.9M |
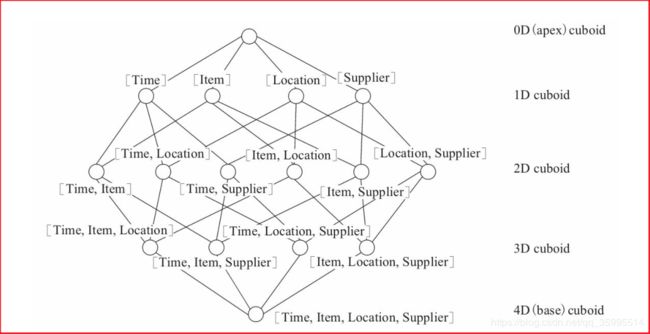
2、Cube和Cuboid
-
一个数据表或数据模型上的字段就它们要么是维度,要么是度量(可以被聚合)
-
给定一个数据模型,可以对其上的所有维度进行组合。对于N个维度来说,组合的所有可能性共有2^N种
-
对于每一种维度的组合,将 度量 做聚合运算,然后将运算的结果保存为一个物化视图,称为
Cuboid(立方形) -
所有维度组合的 Cuboid 作为一个整体,被称为Cube(立方体)。一个Cube就是许多按维度聚合的物化视图的集合。
| 说明 | 维度1 | 维度2 | 维度3 | 维度4 |
|---|---|---|---|---|
| 取值 | 0或1 | 0或1 | 0或1 | 0或1 |
mysql的视图:
是一张虚拟的表
例如: 表名(stu) -> select id,name from stu; (屏蔽掉不想要的列)
为了避免敏感信息泄露,我们可以把以上的结果存储为一个
视图, 视图存储的是sql语句,不是真实的数据. 视图的数据直接来源于源表, 那么当源表的数据发生改变了, 再次查询视图的时候, 数据就会发生变化 当你修改视图的数据的时候,还是在修改源表的数据!!!
物化视图
MySql中没有物化视图, Oracle有!!!
物化视图就是一个真实存在的物理表,相当于把前面我们说的普通视图给物理化成表了!!!
- 普通视图能加快查询速度吗? --- 不能
- 物化视图能加快查询速度吗? --- 能
物化视图由于是一个真实的表,它占用磁盘空间,另外当你join更多表的时候,这些表一旦发生了变化,就会触发物化视图的数据更新!!!( 类似于为什么不在所有的列上建立索引)
![]()
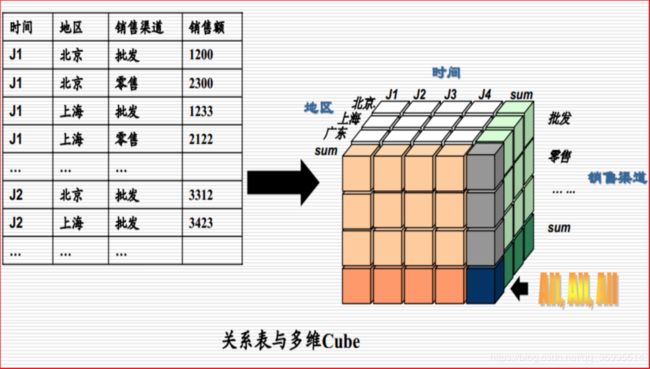
-
数据立方体
-
Cube 是所有 dimension的组合
-
每一种 dimension的组合称之为cuboid(立方形)。某一有 n 个 dimension的 cube 会有 2^n个 cuboid
-
数据立方体只是多维模型的一个形象的说法
-
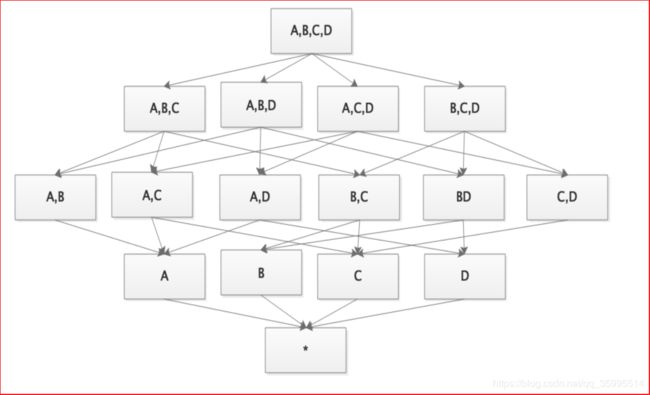
-
为什么叫立方体?
-
立方体本身只有三维,但多维模型不仅限于三维模型,可以组合更多的维度
-
为了与传统关系型数据库的二维表区别开来,才有了数据立方体的叫法
-
3、工作原理
Apache Kylin的工作原理是对数据模型做Cube预计算,并利用计算的结果加速查询。具体工作过程如下。
-
指定数据模型Model,定义
维度和度量 -
预计算Cube,计算所有 Cuboid 并保存为物化视图
-
执行查询时,读取Cuboid,运算,产生查询结果
高效OLAP分析:
-
Kylin的查询过程不会扫描原始记录,而是通过预计算预先完成表的关联、聚合等复杂运算
-
利用预计算的结果来执行查询,相比非预计算的查询技术,其速度一般要快一到两个数量级,在超大的数据集上优势更明显
-
数据集达到千亿乃至万亿级别时,Kylin的速度可以超越其他非预计算技术1000倍以上
技术架构
Apache Kylin系统可以分为在线查询和离线构建两部分。
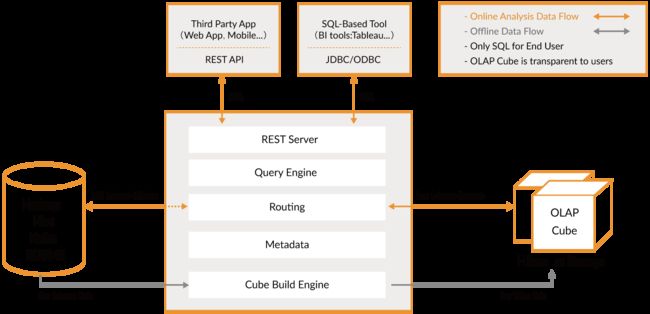
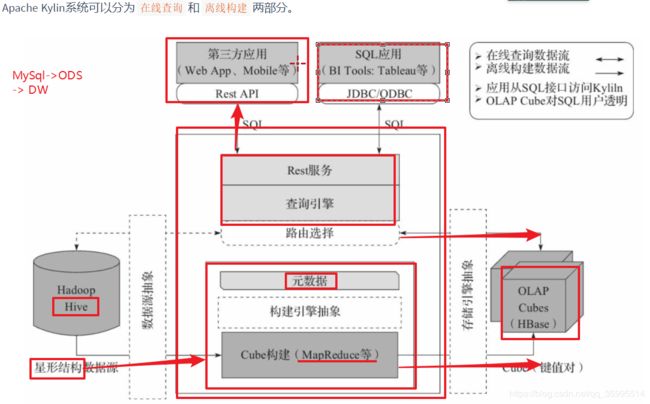 在线查询模式主要处于上半部分,离线构建处于下半部分。以下为Kylin技术架构的具体内容:
在线查询模式主要处于上半部分,离线构建处于下半部分。以下为Kylin技术架构的具体内容:
-
数据源主要是Hadoop Hive,数据以关系表的形式输入,且必须符合星形模型,保存着待分析的用户数据。根据元数据的定义,构建引擎从数据源抽取数据,并构建Cube
-
Kylin可以使用MapReduce或者Spark作为构建引擎。构建后的Cube保存在右侧的存储引擎中,一般选用HBase作为存储
-
完成了离线构建后,用户可以从上方查询系统发送SQL进行查询分析
-
Kylin提供了各种Rest API、JDBC/ODBC接口。无论从哪个接口进入,SQL最终都会来到Rest服务层,再转交给查询引擎进行处理
-
SQL语句是基于数据源的关系模型书写的,而不是Cube
Kylin在设计时,刻意对查询用户屏蔽了Cube的概念
分析师只需要理解简单的关系模型就可以使用Kylin,没有额外的学习门槛,传统的SQL应用也很容易迁移
查询引擎解析SQL,生成基于关系表的逻辑执行计划,然后将其转译为基于Cube的物理执行计划,最后查询预计算生成的Cube并产生结果,整个过程不会访问原始数据源
Kylin查询流程

Kylin On HBase问题
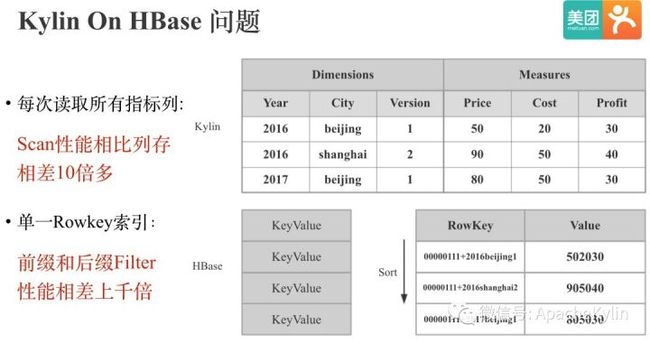
Kylin On HBase中前后缀过滤性能相差巨大的原因:如图所示:Kylin中会将 Cuboid+所有维度拼接成HBase的Rowkey,Kylin默认会将所有普通指标拼接成HBase一个Column Family中同一列的Value。HBase只有单一Rowkey索引,所以只有查询能够匹配Rowkey的前缀时,查询性能会十分高效,反之,查询性能会比较低下,甚至会出现全表Scan。此外,即使只需要查询一个指标,Kylin在HBase侧也需要Scan所有指标列,相比列存性能也会有较大差距。 总的来说,HBase在Kylin的查询场景下Scan和Filter效率较低下。
对于Kylin On HBase Scan和Filter效率低下的问题,我们比较自然会想到的解法是:用列存加速Scan,用索引来加速Filter。
这里我简单介绍下列存的优点,主要包含以下3点:
- 因为只需要读取必需访问的列,所以列存有高效的IO
- 因为每列数据的类型一致,格式一致,所以列存可以进行高效的编码和压缩
- 列存更容易实现向量化执行,而向量化执行相比传统的火山模型,函数调用次数更少,对CPU Cache和SIMD更加友好。 总的来说,列存相比HBase的KV模型更适合Kylin的查询场景。
所以,要解决 Kylin On HBase Scan 和 Filter 效率低下的问题, 我们就需要为 Kylin 增加一个列存,有高效索引的存储引擎。
参考:作者:Kyligence
链接:https://www.jianshu.com/p/554f8b391704