Scrapy框架以及scrapy-redis实现分布式爬虫
Scrapy异步爬虫框架:
requests+selenium可以解决绝大部分的爬虫需求,为啥还要学Scrapy?因为用requests和selenium很繁琐,需要自己写整个爬虫生命周期的代码,功能完全取决于你的代码,还有一个主要原因,就是requests不支持异步,效率很低,爬爬几个页面还好,要是爬全站,有些大型网站做的分页可能有几千甚至上万,爬起来就会很耗时。selenium更别提了,慢得都不行了。这时Scrapy框架来了。
一、Scrapy介绍
Scrapy框架它特就特殊在内嵌了很多组件,这也是大多数框架做的事。那Scrapy到底帮我们做了什么?简单地说就是让爬虫井然有序,在一定程度上减少了我们的代码量。它的侧重点是让爬虫更高效,虽然它是用纯python写的,但它内部集成了Twisted这个强悍的异步网络处理框架,Twisted的主要竞争对手就是Tornado,Scrapy非常快,它是一个基于多线程的异步,非阻塞网络请求框架。默认是开的16个线程你可以自己配置,下图就是Scrapy内部封装的五个组件。
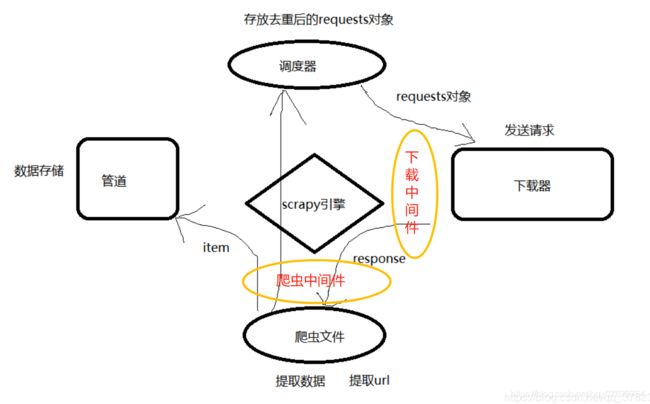
分别是调度器,下载器,爬虫文件,管道和scrapy引擎。scrapy引擎虽然你直观感受不到,但它是最核心的,我们能接触到的就是前四个组件,scrapy引擎可以先不用管,可以把这个引擎理解成是前四个组件的消息中间件,四个组件之间必须靠scrapy引擎才可以传递消息,上图的四个方向箭头,都是经过了scrapy引擎的,scrapy引擎能通过消息的来源判断出该消息交给哪一个组件去处理。相当于对这四个组件进行了解耦。另外,scrapy也有中间件,但只有两个中间件,分别是下载中间件和爬虫中间件。使用方法跟django一样也是定义类重写固定方法再注册进配置文件。
五大组件任务。1、调度器。负责把Request对象去重后压到调度器队列再通过引擎给到下载器。2、下载器。负责拿到Request对象后发送请求,获取响应,再通过引擎把响应数据给到爬虫文件。3、爬虫文件。拿到响应数据response再次提取url并封装成Requet对象,通过引擎把这些对象给到调度器;或者提取response中的数据通过引擎给到管道。4、管道。拿到数据进行持久化。5、scrapy引擎。转发消息。
二、安装:pip install scrapy
三、Scrapy使用流程:
1、创建一个工程;跟django类似,都是使用startproject关键字
scrapy startproject 工程名
2、cd 工程名
3、创建爬虫文件,scrapy genspider 爬虫源文件名 www.xxx.com所有爬虫文件会自动放入spiders包中,后面的那个域名表示scrapy只能爬这个域名下的url,防止scrapy过快请求到页面中的其他站点去了。一般写你要爬取的主站,比如www.taobao.com,但我一般会在爬虫文件中把这个限定注释掉。
4、编写爬虫文件(创建后自动保存在spiders目录下)。
5、执行工程scrapy crawl 爬虫源文件名,不能右键run爬虫文件,要用这个命令在命令行启动爬虫。
6、Scrapy默认是遵从robots协议:要改成False,然后设置日志等级为不报错就不显示日志,或者"WARNING"也可以。然后全局好UA请求头:
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36"
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
LOG_LEVEL = 'ERROR'
案例:抓取段子 https://ishuo.cn/duanzi
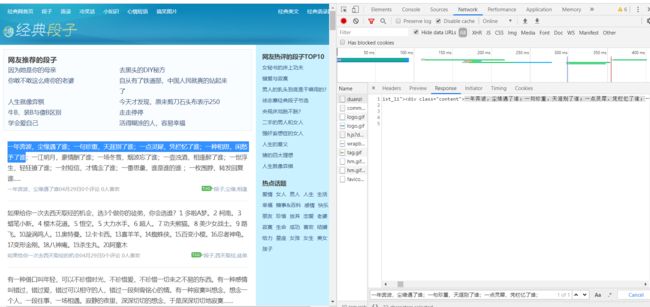
该网站没有ajax动态生成。直接在elements分析即可。下面我们开始使用scrapy爬取段子。
五、爬虫文件编写:
import scrapy
class DuanziSpider(scrapy.Spider):
name = 'duanzi' # 不能随便乱改,跑爬虫的命令scrapy crawl duanzi,就是认的这个变量
# allowed_domains = ['xxx'] # 请求域名限定
# 这个列表作为起始url,scrapy会自动发起get请求,并且响应让回调函数的resposne参数接收
start_urls = ['https://ishuo.cn/duanzi']
def parse(self, response):
# 用来接收爬取的字段数据,实际上这个item我们一般会单独在items文件中定义类,再实例化。可以让项目具有可读性
item = {}
# 拿到li标签列表
li_list = response.xpath('//*[@id="list"]/ul/li')
for li in li_list:
# 当xpath返回的列表有多个字符串,就用extract把这个列表取出来
content_list = li.xpath('./div[1]//text()').extract()
# join表示把列表转化为字符串,用空字符连接,replace去所有空格,也可以用strip()去左右两边空白字符(包括换行符)
item['content'] = ''.join(content_list).replace(' ','')
# 当xpath返回的列表只含一个字符串,就用extract_first把字符串取出来
item['title'] = li.xpath('./div[2]/a/text()').extract_first()
print(item)
# 将存储了解析数据的Item对象提交给管道(piplines.py定义好了管道类)
# 这个yield在for循环里,所以实际上是提交了多次,因为一次只能提交一个item,
yield item
scrapy默认用xpath来解析,直接response.xpath()不需要etree.HTML(response),scrapy中使用xpath有一点区别:首先,你知道xpath返回的肯定是列表。而scrapy中使用xpath返回的是套着selector的列表,可以理解成比我们正常的xpath的返回值多加了一层selector或selectorlist对象,我们需要用extract(取列表)或extract_first(取列表的第一个值)来破这一层。其实extract()[0] == extract_first(),但使用extract_first()的好处就是空列表时值为None而不会报错。还有,parse函数不能随便改名,parse是在源码中写好的它是起始url请求后的默认回调。scrapy的回调函数可以理解为响应数据response的解析函数。
六、数据保存:
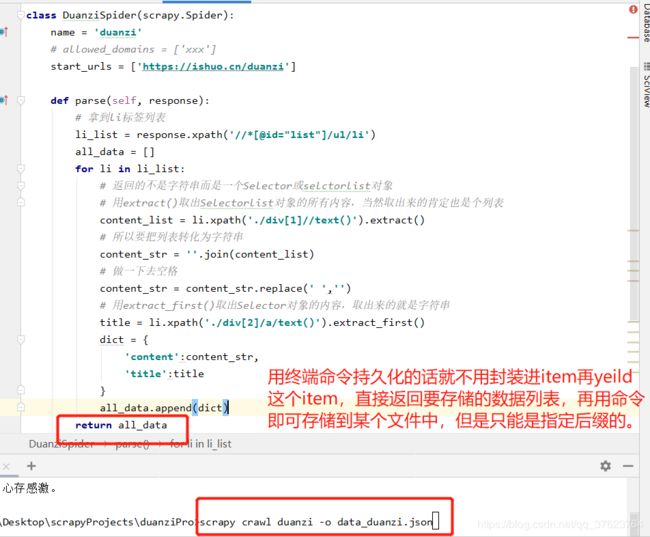
1、基于终端指令存储:直接在for循环外部把每次拿到的item塞进一个列表return,不需要yield挂起。直接用命令如下图(不会用的这个可以不看,局限性太多)
"""只支持存储文件为这些格式:'json', 'jsonlines', 'jl', 'csv', 'xml', 'marshal', 'pickle'"""
scrapy crawl duanzi -o data_duanzi.csv
2、基于管道存储:(scrapy提供的组件,推荐的持久化数据的方法):
如何利用管道实现数据备份:指的是将同一组数据存储到不同的载体(文件,mysql,redis,mongodb)。持久化存储的操作必须要写在管道文件中,一个管道类对应一种形式的持久化存储。如果想将数据存储到多个载体中,则必须定义多个管道类。
持久化流程(一共六步):以爬取阳关问政平台为例:没有ajax动态加载。
网址:http://wz.sun0769.com/political/index/politicsNewest?id=1&page=1

第一步:先在爬虫文件解析好数据;
def parse(self, response):
item = {}
li_list = response.xpath('/html/body/div[2]/div[3]/ul[2]/li')
for li in li_list:
item['number'] = li.xpath('./span[1]/text()').extract_first()
item['status'] = li.xpath('./span[2]/text()').extract_first().strip() # 去首尾空白字符(包括换行符)
item['detail_href'] = 'http://wz.sun0769.com/' + li.xpath('./span[3]/a/@href').extract_first()
item['title'] = li.xpath('span[3]/a/text()').extract_first()
item['start_datetime'] = li.xpath('span[5]/text()').extract_first()
item['left_datetime'] = li.xpath('span[4]/text()').extract_first().strip()
# 抓取详情页面
print(item)
yield item
第二步:在Items文件类中定义相关的属性(解析的数据有哪些字段就定义哪些字段);
你可以不定义这个item,直接像前面爬段子一样在爬虫文件中来个空字典往里塞值。但最好还是定义,一是明确你爬取了哪些字段值,二是防止你在爬虫文件中塞错字段名。
class YangGuanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
number= scrapy.Field()
status= scrapy.Field()
detail_href= scrapy.Field()
title= scrapy.Field()
start_datetime= scrapy.Field()
left_datetime= scrapy.Field()
第三步:在爬虫文件中将解析的数据塞进Item对象中(item就是个字典),并在爬虫文件中将塞好解析数据的Item对象提交给管道(yield item);是在for循环yield的,说明每塞一次就yield一次,虽然是异步一直切换,但是保证了数据不会混淆。
def parse(self, response):
li_list = response.xpath('/html/body/div[2]/div[3]/ul[2]/li')
for li in li_list:
item = YangGuanItem() # 需要导入YangGuanItem
item['number'] = li.xpath('./span[1]/text()').extract_first()
item['status'] = li.xpath('./span[2]/text()').extract_first().strip() # 去首尾空白字符(包括换行符)
item['detail_href'] = 'http://wz.sun0769.com/' + li.xpath('./span[3]/a/@href').extract_first()
item['title'] = li.xpath('span[3]/a/text()').extract_first()
item['start_datetime'] = li.xpath('span[5]/text()').extract_first()
item['left_datetime'] = li.xpath('span[4]/text()').extract_first().strip()
# 抓取详情页面
print(item)
yield item
第四步:在管道文件中定义管道类,在process_item方法中接受Item对象并且对其进行任意形式的持久化存储操作;下面代码为持久化到文件,scrapy专门给了你自动调用的三个方法让你重写,第一个是开启爬虫时被调用,用于连接数据库或者打开文件,第二个就是让你拿item来存进数据库,最后一个就是爬虫结束时关闭连接或关闭文件。
class YangGuanPipeline(object):
f = None
# 只打开一次文件,自动执行
def open_spider(self, spider):
self.f = open('./yangguang.txt', 'w', encoding='utf8')
# 一次只接受一个item,爬虫文件yield多次,当然这儿也接受多次
def process_item(self, item, spider):
# 将接收到的item字典中存储的数据取出,我先就只持久化这三个字段值
number = item['number']
status = item['status']
title = item['title']
self.f.write(number + ':' + status + ':' + title + '\n')
# 有可能有下一个管道类也要存这个item对象,不return,下一个管道就拿不到
return item
# 只关闭一次,自动执行
def close_spider(self, spider):
self.f.close()
第五步最后一步:在配置文件中注册管道,再scrapy crawl 爬虫文件名运行即可。
ITEM_PIPELINES = {
# 300表示优先级,数值越小,优先级越高,越先执行,因为这些类都在管道文件中
'YangGuanPro.pipelines.YangGuanPipeline': 300,
# 管道文件中可以有多个管道类.......
}
注意:如果有多个管道类,来自爬虫文件的item只可以先提交给一个管道,那到底交给哪个管道类呢?所以这就是上面注册管道时,后面有个数值300的作用,300表示优先级,数值越小,优先级越高,爬虫文件会优先把item传给他,然后这个管道类再通过process_item方法return给下一个管道,以此类推,但凡有一个管道类中的process_item方法没有return item,在它以后权重的管道就拿不到item对象。
结果:
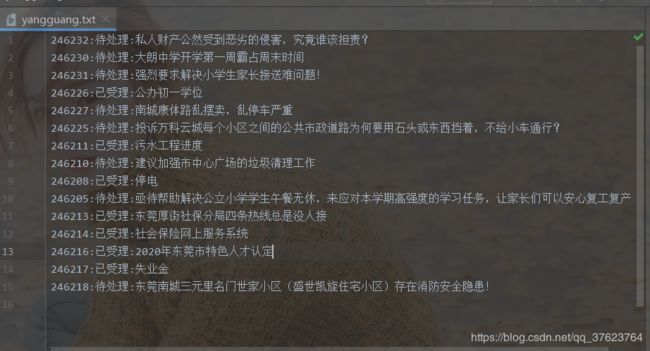
下面是持久化到mysql,需要另外写一个管道类(在同一个管道文件),写完也是需要注册进配置文件,你需要先在目标mysql的数据库中建好数据表及对应字段。
数据库建表语句:create table yangguan(number varchar(20),status varchar(20),title varchar(300));
import pymysql # 存到mysql
class MysqlPipeLine():
conn = None
cursor = None
def open_spider(self, spider):
# connect = Connection = Connect三个方法是一样的
self.conn = pymysql.Connect(host="mysql服务器端ip",user="lanyc",password="密码",db="数据库名",charset='utf8')
# 这个方法会多次接收爬虫文件提交过来的item对象做持久化
def process_item(self,item,spider):
number = item['number']
status = item['status']
title = item['title']
# 数据进库
sql = 'insert into yangguan values("{}","{}","{}")'.format(number,status,title)
self.cursor = self.conn.cursor()
try:
self.cursor.execute(sql)
self.conn.commit()
except Exception as e:
print(e)
self.conn.rollback()
return item
def close_spider(self, spider):
# 关闭游标和连接对象
self.cursor.close()
self.conn.close()
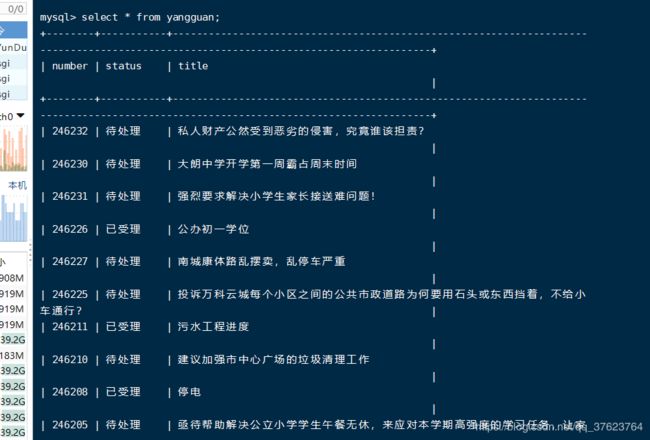
查看mysql数据库的yangguan表:
最后我们再定义一个管道类来持久化到mongodb。持久化到mongodb有一步很重要的操作需要在item文件中再加上一个字段_id= scrapy.Field(),然后还有一点很关键,用mongo存数据,爬虫文件中,实例化item对象必须放在for循环内部,因为mongo中数据是存在集合中,一个集合有多条记录,每条记录有个唯一id,就是这个_id。你可以把mongodb的集合看成mysql的表。这个_id就是它的主键,但是它里面的每条记录的存储值只能是文档型(字典)。那不刚好跟item对口嘛,我们的item就是字典呀,直接就能往mongodb存,所以mongodb也叫爬虫数据库。
from pymongo import MongoClient
# 实例化client,建立连接,我是docker跑的8004端口映射到mongodb的默认端口27017
client = MongoClient(host='你的服务器ip', port=8004)
# 选择你要存储到(可以是不存在的数据库)哪个数据库下的哪个集合里面,我选择存到yangguan数据库里面的lan集合
collection = client['yangguan']['lan']
class MongoDBPipeLine():
def process_item(self,item,spider):
# insert_one是python操作mongo的方法,表示插入一条数据,我们这儿是来一个item插一次。不需要insert_many方法同时插入多条数据。
collection.insert_one(item)
return item
注意:前面我们持久化到文件和mysql都重写了被scrapy自动执行一次的open_spider和close_spider方法来打开或关闭连接。redis和mongo会自动关闭我们可以不用写这两个方法,mongodb非常好的是有python动态理念,不需要你事先创建对应数据库和集合,你随便写一个数据库名和集合名就可以连接,往里存数据就行了。到时mongo会自动创建这个数据库和集合把数据放进去。至于redis就不演示了,redis不会用来存爬虫的数据,只会在分布式爬虫中用到redis来做调度器队列和数据持久化位置(scrapy-redis自动完成不需要你写管道)。
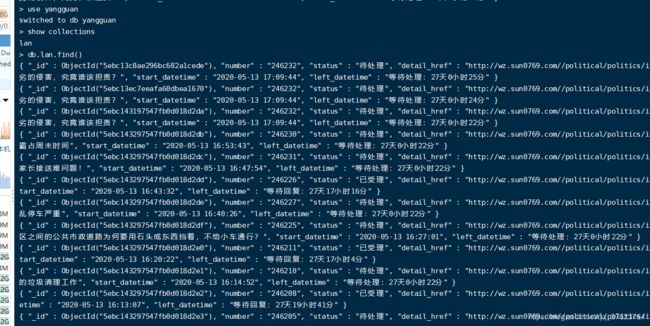
查看数据存进mogodb后的结果:
七、手动发送请求实现对全站的数据爬取,前面我们只是抓了一页。为啥叫手动发起请求,因为scrapy只会对start_urls里面的url发起get请求。在start_urls之外的url就必须靠我们手动发起。
有人说如果我已经知道每一页的url规律,那我直接扔一个列表生成式进start_urls不就行了嘛,这个方法是可行的。代码如下:
import scrapy
from TaoBao.items import YangGuanItem
class GuospiderSpider(scrapy.Spider):
name = 'itcast'
url = 'http://wz.sun0769.com/political/index/politicsNewest?id=1&page={}'
# 规律是page+1,最后一页是13362,先只爬前12页
start_urls = [url.format(i) for i in range(1,13)]
def parse(self, response):
li_list = response.xpath('/html/body/div[2]/div[3]/ul[2]/li')
for li in li_list:
item = YangGuanItem()
item['number'] = li.xpath('./span[1]/text()').extract_first()
item['status'] = li.xpath('./span[2]/text()').extract_first().strip() # 去首尾空白字符(包括换行符)
item['detail_href'] = 'http://wz.sun0769.com/' + li.xpath('./span[3]/a/@href').extract_first()
item['title'] = li.xpath('span[3]/a/text()').extract_first()
item['start_datetime'] = li.xpath('span[5]/text()').extract_first()
item['left_datetime'] = li.xpath('span[4]/text()').extract_first().strip()
print(item)
yield item
但是如果分页的url没法找规律,那你就只能提取每一页url进行手动发请求,这也是推荐的。使用yield scrapy.Request(url,callback)来手动发起get请求。
import scrapy
from TaoBao.items import YangGuanItem
class GuospiderSpider(scrapy.Spider):
name = 'itcast'
start_urls = ['http://wz.sun0769.com/political/index/politicsNewest?id=1&page=1']
def parse(self, response):
li_list = response.xpath('/html/body/div[2]/div[3]/ul[2]/li')
for li in li_list:
item = YangGuanItem()
item['number'] = li.xpath('./span[1]/text()').extract_first()
item['status'] = li.xpath('./span[2]/text()').extract_first().strip() # 去首尾空白字符(包括换行符)
item['detail_href'] = 'http://wz.sun0769.com/' + li.xpath('./span[3]/a/@href').extract_first()
item['title'] = li.xpath('span[3]/a/text()').extract_first()
item['start_datetime'] = li.xpath('span[5]/text()').extract_first()
item['left_datetime'] = li.xpath('span[4]/text()').extract_first().strip()
print(item)
yield item
# 每次都去找下一页按钮的href地址实现爬取全站,记住一定要加if来跳出递归,不然会死循环
next_url = 'http://wz.sun0769.com' + response.xpath(
'/html/body/div[2]/div[3]/div[3]/a[2]/@href').extract_first()
if next_url != 'http://wz.sun0769.com/political/index/politicsNewest?id=1&page=13363': # 最大页是13362
yield scrapy.Request(next_url, callback=self.parse)
还可以手动发起post请求:(注意:在scrapy中一般不发post,因为发post就牵扯到模拟登录或ajax动态加载,用requests,requests不行就用selenium,反正你记住,复杂的别用scrapy来爬。大多玩法是用requests和selenium来帮scrapy做url准备。)
发post请求
yield scrapy.FormRequest(url,formdata,callback)
八、请求传参实现深度爬取:
前面我们已经通过手动发起请求,每次都找下一页实现全站爬取,但是我们只是拿到了第一层,现在需要拿第二层——请求每一页里边的详情页url,之前我们使用requests实现深度爬取也不难,都是从每一页中解析到详情页的地址,然后再向详情页发请求拿数据就行了,并且数据还能对应上。而scrapy是异步的,你怎么保证页面数据跟它所在的详情页一一对应,就是靠在多个解析函数中传递item,保证本次的item对象是主页跟它的详情页共用的。你塞完属性给我塞,只有主页的回调把item传出来meta={'item':item}),详情页的回调才能拿到item往里塞值,也就实现了某条数据跟他所属详情页数据对应。
案例:爬4567电影网
爬下图的所有页码的所有对应详情页中(深度爬取)的电影详情。
https://www.4567kan.com/frim/index6.html
第一页,起始url:
详情页:
import scrapy
class MovieSpider(scrapy.Spider):
name = 'movie'
# allowed_domains = ['xxx']
start_urls = ['https://www.4567kan.com/frim/index6.html']
def parse(self, response):
li_list = response.xpath('/html/body/div[1]/div/div/div/div[2]/ul/li')
for li in li_list:
item = {} # 最好还是在专门的items文件中定义类
item['name'] = li.xpath('./div/div/h4/a/text()').extract_first() # 电影名称
detail_url = 'https://www.4567kan.com' + li.xpath('./div/div/h4/a/@href').extract_first()
# 请求详情页实现深度爬取
yield scrapy.Request(detail_url,callback=self.parse_detail,meta={'item':item})
# 找到下一页的href,进行手动请求实现全站爬取,递归必须加出口if
# 也可以用next_url = 'https://www.4567kan.com' + response.xpath('//a[text()='下一页']/@href').extract_first()
next_url = 'https://www.4567kan.com' + response.xpath('/html/body/div[1]/div/ul/li[9]/a/@href').extract_first()
if next_url != 'https://www.4567kan.com/frim/index6-58.html':
yield scrapy.Request(next_url,callback=self.parse)
def parse_detail(self,response):
item = response.meta.get('item')
movie_detail = response.xpath('/html/body/div[1]/div/div/div/div[2]/p[5]/span[2]/text()').extract_first()
item['dec'] = movie_detail
print(item)
yield item
结果:

记住主要想实现深度爬取,必须在回调函数(解析函数)中通过meta传递item,你塞完给我塞,保证多个有联系的解析函数该次循环塞的是同一个item。让每次的item内部数据是对应的。最终yield item的地方就是最里层的解析函数。本例我们只有两层所以是在parse_detail中。
Scrapy配置文件settings.py的其他配置:
1、调整并发数量:scrapy默认开启16个线程。你可以自己设置CONCURRENT_REQUESTS的值
2、COOKIES_ENABLED,有很多人把这个配置项搞混淆了,这个配置简称为是否禁用cookie,默认是把False给注释了,即允许cookie使用,你一辈子都不需要动。
3、请求失败是否重新请求,RETRY_ENABLED默认为False。
4、一次请求时间超过多少秒,就会放弃请求。DOWNLOAD_TIMEOUT这个在默认配置是没有的。
5、在全站抓取时,DOWNLOAD_DELAY有时能解决503的错误,它表示每个请求的时间间隔。默认是0(秒),我们可以设置为0.15。
Scrapy中间件:
django中间件的作用是利用每个中间件中的五个方法自动适时调用来优化web系统。那scrapy的中间件也差不多吗?那是肯定的。但是scrapy的中间件只有两个。一个是进出爬虫文件的爬虫中间件(基本不用或者说用的不多)。
另一个是进出下载器的下载中间件(重点)。为啥不研究上面的爬虫中间件呢?首先中间件肯定是与请求和响应有关。说到拦截或修正请求,爬虫中间件中,Request对象刚从爬虫文件出来还没到调度器过滤去重,你在这儿拦截不好,而下载器中间件,就能拦截调度器过滤后压到队列的请求对象。说到拦截响应:response回来第一个走的就是下载器中间件,不正好吗,你还在爬虫中间件再拦干啥,所以爬虫中间件从请求和响应来分析都基本用不上,只会编写下载中间件类,这个中间件类名你可以随便定义,但你必须重写这些个固定的中间件方法,最后需要注册进配置文件。
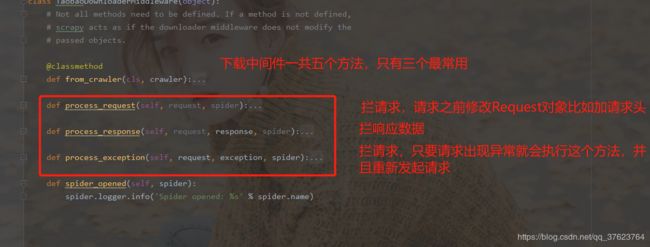
我们加代理ip一般是加在process_exception方法中,process_request中一般是用来加动态UA请求头,request.headers['User-Agent'] = 一个生成动态UA的函数()下面是加代理。:
def process_exception(self, request, exception, spider):
# 一般我们会用random.choice(代理池列表)
request.meta['proxy'] = 'http://代理ip:端口'
return request # 重新发送修正后的请求
最后说一下中间件方法的参数,request好理解,就是当前的这个Request对象,而这个spider参数,包括管道类的三个方法(open_spider,close_spider,process_item)也有这个spider,其实这个spider就是指的我们爬虫文件类的实例对象,作用:比如我们在管道的open_spider方法或这个中间件的方法中赋了一个连接对象给spider,spider.conn = redis连接,以后我们就可以在爬虫文件中self.conn使用。。
CrawlSpider:(以后都会使用CrawlSpider)
前面我们已经使用手动发请求的方式实现了全站爬取(某网站的某板块的所有页面甚至详情页的数据爬取)。前面爬4567电影我们需要自己手动地解析出下一页url以及页面上每个电影的详情url。有没有一个工具能帮我们批量提取url且自动请求呢?这就是CrawlSpider类,它是Spider的子类。作用:用于便捷的实现全站数据的爬取,
使用:
创建爬虫文件scrapy genspider -t crawl 爬虫名 xxx.com,-t crawl 是告诉Scrapy框架你的爬虫类现在不再继承默认的Spider,而是继承CrawlSpider,你还是用原来方法创建爬虫文件也行,但是需要手动修改继承还有添加rules规则。
功能:
两个功能,一是链接提取器LinkExtractor,按某些规则(一般用allow正则或restrict_xpaths)来批量提取url并且自动发起请求(没前缀自动会加上域名前缀);二是规则解析器Rule,给请求的响应数据绑定回调callback(可以为空),如果callback为空,就表示翻页,我们就可以再定义一个Ruel来解析每个页面的详情url,再看你是否要提取数据(绑定回调),相当于就是一层一层往里进。follow=True表示把每一页都作为起始url,可以理解为跟随,继续以当前页为基准提取url,所以会有大量重复的页码url,问题不大,因为Request对象到调度器后会去重的。
Rule(LinkExtractor(allow=r'url正则表达式'), callback=解析函数名, follow=True)
这个Rule类它也做了封装Request对象给调度器的工作。这个工作实际上就是CrawlSpider的父类Spider的parse方法来做的,达到了自动请求的效果,所以你不要在crawlspider中定义parse名称的回调。深度爬取时:如果你想多层的数据有对应关系,该层往里的url的就必须手动提取和请求。因为只有手动请求才可以用meta在回调中传递item对象,这样才能让外层和内层数据一一对应。如果你不需要外层数据,只想要里层数据时,就可以全部url用crawlspider提取,外层的回调为空即可。
下面是用crawlspider和手动发送请求(详情页)来实现爬取4567全站的喜剧类电影的名称及详情:
爬虫文件:
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class CrawlspiderMovieSpider(CrawlSpider):
name = 'crawlspider_movie'
# allowed_domains = ['xxx']
start_urls = ['https://www.4567kan.com/frim/index6.html']
rules = (
# 一般是使用allow(正则),正则不需要你写很完整,能匹配出来就行了
Rule(LinkExtractor(allow=r'/index6-\d+\.html'), callback='parse_item', follow=True),
# 深度爬取最好自己手动发请求让两层数据一一对应,最里层的follow没必要(不是不可以)为True,因为详情页里你不需要取url了
# Rule(LinkExtractor(allow=r'/movie/index\d+\.html'), callback='parse_detail', follow=False),
"""这里面可以有多个Rule,他们之间是层级关系,在这儿的最里层的Rule不需要把follow置为True,因为最里层
就说明不需要提取url了。如果callback为空,它也会正常提取并发请求,相当于是进去了一层的效果
"""
)
def parse_item(self, response):
li_list = response.xpath('/html/body/div[1]/div/div/div/div[2]/ul/li')
for li in li_list:
item = {} # 最好在专门的items文件中定义Item类
item['name'] = li.xpath('./div/div/h4/a/text()').extract_first() # 电影名称
detail_url = li.xpath('./div/a/@href').extract_first() # 该电影的详情页url
detail_url = 'https://www.4567kan.com/' + detail_url
yield scrapy.Request(detail_url,callback=self.parse_detail,meta={'item':item})
def parse_detail(self, response):
item = response.meta.get('item')
movie_detail = response.xpath('/html/body/div[1]/div/div/div/div[2]/p[5]/span[2]/text()').extract_first()
item['dec'] = movie_detail
print(item)
yield item
两层数据一一对应:

面试:如何使用CrawlSpider将一个网站的所有链接爬取到?
回答:问题的意思就是拿全站的url,包括每一页url,每一页中详情页url,广告url,只要是url。只需要这么做:(把正则设置为空即可,follow没必要为True)
Rule(LinkExtractor(allow=r''), callback=解析函数),
分布式:
概念:使用多台机器搭建一个分布式集群,在分布式集群中共同运行同一个程序,让这个分布式集群对同一个网站进行联合数据爬取。原生的scrapy框架是无法实现分布式的。为啥?
怎样实现分布式?
如果用原生的scrapy,每个机器都有自己的调度器和管道,互不相关,比如爬100个url,有三台机,同时跑起来,每台机都爬一遍会一共发起了300个请求,这样做毫无意义。我们目的是让三台机分担地发起这100个请求,爬虫文件任务是数据提取以及封装Request对象给引擎,最终到调度器去重再塞队列,开始调度出url,所以,想要达到分布式效果,就必须让这个分布式集群共享一个调度器,不然就重复请求了,大家的下载器都监听同一个调度器队列。然后数据给到管道存储,还必须让集群机都提交到同一个管道,由这个管道进行统一汇总持久化,所以分布式集群需共享一个管道。使用scrapy-redis组件实现分布式。scrapy-redis组件的作用:能够让分布式集群共享同一个管道和调度器。pip install scrapy-redis
实现流程:
1、创建工程。
2、cd 工程。
3、创建基于CrawlSpider的爬虫文件(加-t crawl),因为一般分布式都是做全站数据爬取会用到链接提取。
4、修改爬虫文件:a、from scrapy_redis.spiders import RedisCrawlSpider,让爬虫文件中继承RedisCrawlSpider。b、删除start_urls添加一个新属性redis_key = 'xxx',指定被共享的调度器队列的名称。爬虫文件我也是爬得上面的电影,只需要做一些修改:
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapy_redis.spiders import RedisCrawlSpider
from fbsPro.items import FbsproItem
#################################修改为继承RedisCrawlSpider(分布式)
class FbsSpider(RedisCrawlSpider):
name = 'fbs'
# allowed_domains = ['example.com']
#################################声明调度器队列(分布式)
redis_key = 'movieQueue'
rules = (
# 只使用链接提取器提取每一页url,详情页url我们自己提取自己手动发请求
Rule(LinkExtractor(allow=r'/frim/index6-\d+\.html'), callback='parse_item', follow=True),
)
def parse_item(self, response):
li_list = response.xpath('/html/body/div[1]/div/div/div/div[2]/ul/li')
for li in li_list:
item = {} # 最好在专门的items文件中定义Item类
item['name'] = li.xpath('./div/div/h4/a/text()').extract_first() # 电影名称
detail_url = li.xpath('./div/a/@href').extract_first() # 该电影的详情页url
detail_url = 'https://www.4567kan.com/' + detail_url
yield scrapy.Request(detail_url, callback=self.parse_detail, meta={'item': item})
def parse_detail(self, response):
item = response.meta.get('item')
movie_detail = response.xpath('/html/body/div[1]/div/div/div/div[2]/p[5]/span[2]/text()').extract_first()
item['dec'] = movie_detail
print(item)
yield item
5、在settings.py文件中配置共享的调度器和管道,scrapy-redis组件会自动帮你持久化数据到redis服务器中(只能存到redis,不能手动改为其他载体)。你不需要编写管道代码了!!!!
# 1、使用同一个调度器
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 去重组件(过滤器的一个类)
SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 调度器组件
SCHEDULER_PERSIST = True # 持续化存储设置,实现了增量式,只爬数据库没有的
# 2、指定使用的同一个管道:
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 400, #这个管道类不是我们定义的,是scrapy-redis组件中的
# 3、连接redis数据库使用默认的0号库
REDIS_HOST = 'x.x.x.x' #主机名
REDIS_PORT = 6379 #端口号
# redis有密码的话加上这个配置
REDIS_PARAMS = {
'password': '123',
}
6、执行爬虫(scrapy crawl 爬虫文件名)。我用的两台机,我先在本机写好了项目代码,然后copy了整个项目到服务器,两边同时执行爬虫,都进入等待调度器队列的url状态。为了看到效果,我改为了开了4个线程,你不改线程数也可以,不过数据量太少的话不好看效果。
7、向调度器队列中塞起始url,因为现在调度器队列movieQueue为空,我直接在redis-cli端命令行:lpush movieQueue www.起始url.com,更多时候是在python代码中连接redis来插入起始url,反正你记住这个队列是个列表就行了。我现在开始插起始url:
![]()
两边代码马上开始工作:

8、我在项目代码中打印了item,那上图的这些item数据持久化在哪呢?前面说了就存储在默认连接的redis服务器的0号库中,现在去看redis的0号库:
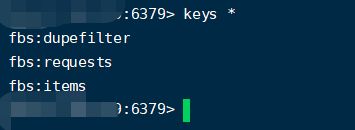
产生了这三个键,用type 键名可以查看数据类型,fbs:items就是存储我们item数据的键,是个列表。其他两个一个是集合一个是有序集合主要是存请求对象,比如第一个就是为了实现去重功能(集合)。查看数据:
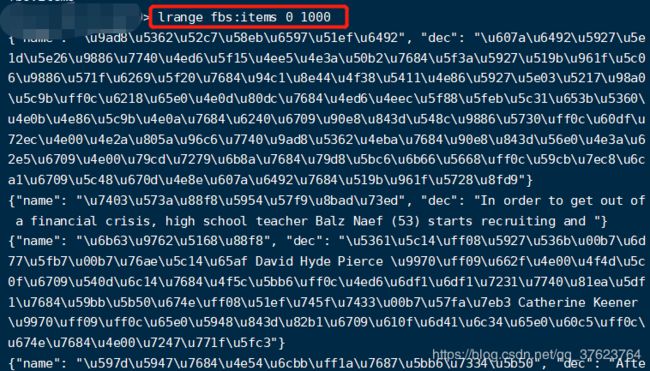
是unicode编码,在代码中进行解码,然后把中文的item存入mongodb:
########### Mogodb
from pymongo import MongoClient
# 建立连接
client = MongoClient(host='ip',port=密码)
collection = client['movie']['chuan']
############## Redis
import redis
conn = redis.Redis(host='ip', password='密码')
# 拿到fbs:items中的列表数据
data_list = conn.lrange('fbs:items', 0, 2000)
i = 1
for dic in data_list:
item = {}
item['name'] = eval(dic.decode()).get('name')
item['dec'] = eval(dic.decode()).get('dec')
# 插入到mongodb
collection.insert_one(item)
print('正在插入第{}条数据......'.format(i))
i += 1
在mongo中查看数据:

增量式爬虫:
概念:监测网站数据更新的情况,只爬取最新的(多数是基于url)。目前我们爬虫文件中可以继承的类有Spider,CrawlSpider,RedisSpider,RedisCrawlSpider。前两种是原生scrapy的方式。后两种是用scrapy_redis组件实现分布式爬虫的方式,这种方式默认就是增量式爬虫,因为redis会用set和zset存Request对象,以及指纹。所以增量式爬虫的设计针对的是原生Scrapy。
原生Scrapy实现增量式:
对爬取的url进行监测,使用一个记录表存储爬取过的url,只要记录表中存有的url,就说明url对应的数据已经爬取过了无须再爬,否则表示该url是最新的url就爬。两个问题,记录表需要持久化存储吗,记录表用什么充当更好?
肯定要存储,不然你咋知道你爬过哪些url,综上,使用redis的set来充当记录表。因为向集合中塞存在的值会失败,返回0。比如我们利用CrawlSpider请求到每一页的数据,然后把解析出来的详情页url在管道中放进redis的一个叫movie_detail集合中,爬虫文件中请求详情页之前先if conn.sadd('movie_detail',movie_url),返回值为0说明集合已经存在,即已经爬过这个详情页,如果返回值为1才手动发起详情页的请求。