数据分析从零开始实战 | 基础篇(六)
零、写在前面
保证,全网最详细的OpenRefine初级入门教程。
前面四篇文章讲了数据分析虚拟环境创建和pandas读写CSV、TSV、JSON、Excel、XML格式的数据,HTML页面读取,数据库相关操作,今天我们继续探索pandas。
基础篇(一)
基础篇(二)
基础篇(三)
基础篇(四)
基础篇(五)
本系列学习笔记参考书籍:《数据分析实战》托马兹·卓巴斯
一、基本知识概要
1.数据转换工具OpenRefine介绍
2.数据转换工具OpenRefine安装
3.数据转换工具OpenRefine基本使用
4.数据转换工具OpenRefine进阶使用
二、开始动手动脑
1、数据转换工具OpenRefine介绍
OpenRefine是一个数据转换工具(IDTS),Metaweb公司2009年发布的一个开源软件。Google在2010年收购了Metaweb,把项目的名称从Freebase Gridworks改成了Google Refine,后来Google开放其了源码,并改名为OpenRefine。
其能够对数据进行可视化操作处理。它很像传统的excel软件,但其工作方式更像数据库,因其并不是处理单独的单元格,而是处理列和字段。这意味着OpenRefine对于增加新行内容表现不佳,但对于探索、清洗、整合数据却功能强大,主要用于快速筛选数据、清理数据、排重、分析时间维度上的分布与趋势等。
2、数据转换工具OpenRefine安装
(1)下载地址:http://openrefine.org/download.html
OpenRefine的主页,“A free, open source, powerful tool for working with messy data”,一个免费的,开源的,强大的,处理杂乱的数据的工具。

这里我下载的是OpenRefine 3.2 beta(3.2测试版),因为觉得比较新,所以下载来试试。
我的电脑是windows的,所以下载的是Windows kit,大家根据自己的开发环境下载,我们可以看到这个软件还挺大的有95.9MB。

(2)下载好后,解压下载好的压缩包,然后点击openrefine.exe文件,即可启动服务。

(3)在第二步中我们可以看出服务地址是http://127.0.0.1:3333/,浏览器内访问即可打开OpenRefine,如果你和老表(小编本人绰号)一样英语不好的话,我建议你使用谷歌浏览器打开,可以自动翻译页面内容,准确率还是很高的。


3、数据转换工具OpenRefine基本使用
(1)按上述步骤打卡OpenRefine后,第一步就是导入文件,这里书中给的示例文件是:realEstate_trans_dirty.csv,点击选择文件,选择好文件后,点击打开就行。
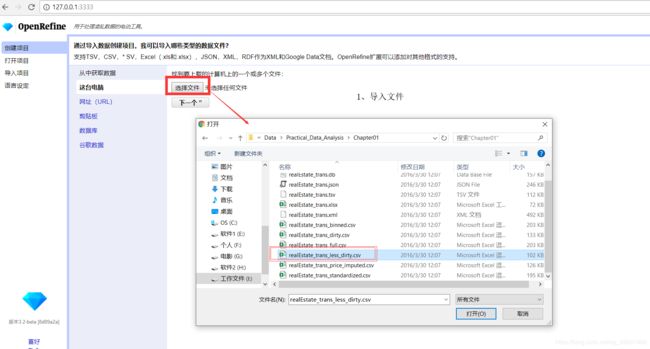
(2)数据导入成功后,点击下一个(Next)后数据就完全导入成功了,如下图,我们可以看到,OpenRefine支持多种文件格式数据读入,如:基于CSV / TSV /分隔符的文件、基于行的文本文件、固定宽度的字段文本文件、PC轴文本文件、JSON文件、MARC文件、JSON-LD文件、RDF / N3文件、RDF / N-Triples文件、Excel文件等。
另外需要注意的是数据导入后,是被当做文本格式的,所以后续数据分析前还要把数据行的格式转变为数值型。(如图片中的:beds、baths等列)

上一步中我们已经导入好了数据,点击右上角的Create Project,创建项目,接下来就可以开始对数据进行初步的处理了。

(3)数据格式转换:直接转换的(如:beds、baths列)
示例:将beds列的数据转换为数值类型
a、点击beds左边的小三角形
b、点击 Edit cells(编辑列)
c、点击 Common transforms(普通转换)
d、选择 To number(表示转换成数值类型)
我们可以看到上面还可以转换成其他格式,比如 To data(日期类型)、To text(文本类型) 、To nul1(空值)、 To uppercase(大写)等。

转换成功。为后续数据分析做准备,我们依次把baths、sq__ft、price、latitude、longitude这几行按上面方法转换成数值类型。

(4)数据格式转换:需处理再转换的(如:sale_date列)
在sale_date列,数据是类似:Wed May 21 00:00:00 EDT 2008这样的,我们希望这样的数据变得更加方便观察,变成某种适合的数据类型,明显不应该是字符型,所以我们把其转变成日期类型,这需要一点点技巧,不是上面的Common transforms能实现的。
示例:将sale_date列的数据转换为日期类型
a、点击sale_date左边的小三角形
b、点击 Edit cells(编辑列)
c、点击 Transform…(转换…)

d、选择GREL(谷歌优化表达语言)转换日期。

# 原始数据
Wed May 21 00:00:00 EDT 2008
# 修改后数据
2008-05-21T00:00:00Z
# 使用GREL语句
substring(value, 4, 10) + ',' + substring(value, 24, 29).toDate()
# 解释
'''
vaule表示数值(内容),即 Wed May 21 00:00:00 EDT 2008
substring表示分割字符串函数
第一个参数是要分割的字符串,即 Wed May 21 00:00:00 EDT 2008
第二个参数是分割起始符的下标,4 表示的是 M的下标
第三个参数是分割终止符的下标,10表示的是21后的空格字符的下标
剪切出字符串后,调用 toDate()把提取出来的数据转换成日期(date)类型。
'''

到这里,我们就粗略的对数据进行了第一步处理。
4、数据转换工具OpenRefine进阶使用
理解数据是建立成功模型的前提。 ----来自《数据分析实战》
(1)OpenRefine Facet之文本facet
首先,所谓facet,表面意思是面状、面片,在这里我们可以理解为过滤器,可以使你快速的选择某些行或直接探索数据。
文本facet可以让你快速地对数据集中文本列的分布有一个感觉,也就是了解文本数据在一些维度上的信息。
示例: 统计 city_state_zip(表示意思是:城市_州_邮政编码)中那个城市出现次数最多
a、点击 city_state_zip左边的小倒的三角形
b、点击 Facet- Text facet

我们仔细观察显示结果会发现,有很多其实是一个城市,只是所处州邮政编码不同导致统计的时候误认为是两个城市了,所以我们在统计数据前需要处理一下数据。

这次我们点击Facet后选择 Custom text facet(自定义文本过滤器)。

用一句GREL表达式处理数据,提取出city_state_zip中的城市名。
'''表达式解析'''
value.match("(.*?) CA.*?")[0]
'''
vaule表示数值(内容),即 SACRAMENTO CA 95823
match表示正则提取函数
参数是正则匹配模式字符串,表示意思是 取出" CA"之前的字符串,即城市名
'''
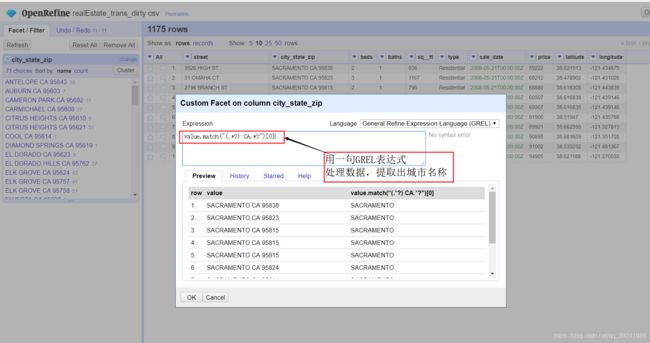
原数据是记录2008.5.15-2008.5.21之间商品的交易信息,通过这个结果我们可以明显看出,在这期间SACRAMENTO交易次数是最多的,其次是ELK GROVE,这比我们在Python里用代码处理数据计数好多了,当然,前提是你能比较熟练的使用OpenRefine。

(2)OpenRefine Facet之数字facet
示例: 查看价格( price)分布
a、点击 price左边的倒三角形
b、点击 Facet-> Numeric facet
我们发现原数据中有108行price是空白的,有值的数据量有1067个,价格区间在0-890000,大量数据靠左,我们进行进一步确定数据集中处,可以拖拽两边的滑动块,发现价格集中在60000 — 400000。

(3)OpenRefine Facet还有 时间线facet和散布图facet
时间线facet(Timeline facet):可以看到不同时间点的数据量情况。
散布图facet(Scatterplot facet):可以分析数据集中数字型变量间的相互作用。
(4)OpenRefine 数据排重
这里我们对stree列处理,因为同一套房子不会在一周内同时卖出两次,如果有相同的stree就表示是重复的数据。
a、点击 stree左边的倒三角形
b、点击 Edit cells-> Blank down
Blank down表示:使重复数据的位置值变成空值(用于去除重复数据);
Fill down表示:如果某数据位置为空值,则使用上一行的数据值填补该位置(用于填补空缺数据)。


(5)OpenRefine 快速去除空白、缺失数据
如何去除这些分布在数据中的空白行呢?
我们可以创建一个空白数值过滤器。
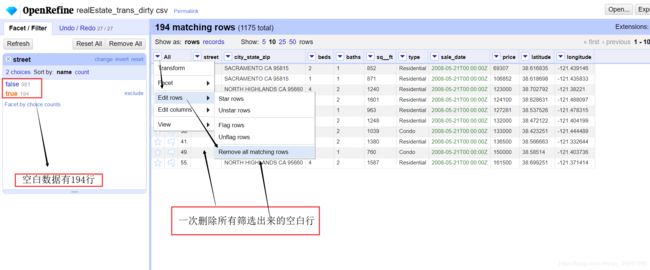
a、点击 stree左边的小倒的三角形
b、点击 Facet- > Customized facets ->Facet by blank
这样就可以筛选出所有stree值空缺的行。

c、点击 All左边的小倒的三角形
d、点击 Edit rows- > Remove all matching rows
既可以删除所有空白行。
另外,在OpenRefine里GREL语法是比较重要的,也是一种编程语言,具体语法请查看GREL-Functions Github地址:https://github.com/OpenRefine/OpenRefine/wiki/GREL-Functions
三、老表说话
本系列前五篇阅读量都不错,很多读者也反应对自己学习很有帮助,这也是我继续输出写作的动力,如何把书上的东西学会?如何将学会的东西转化成更通熟易懂的能传播的知识?如何坚持学习?这些是我在考研之于思考的最多的东西(学习方面)。
不说废话了,只要想做,干就是了;只要想学,学就完了。
老表联系了机械工业出版社,特地给大家送出五本本系列学习笔记参考书籍托马兹·卓巴斯的《数据分析实战》,参与方式很简单,
1、本文赞赏区送3本,开赞赏不为什么,看着头像多,心里特别舒服,至于赞赏金额大家随意1-100都行;
2、留言区赠送2本,走心点谈谈自己对未来的规划想法,以及接下来最想学什么?(30字以上)
本文完 ,我是老表,支持我请转发分享,谢谢。
