Pretraning in NLP(预训练ELMo,GPT,BERT,XLNet)

图像中的Pretraning往往是在大规模图像集上进行训练后,再在特定的任务上进行fine-turning。而nlp领域的fine-turning就是word embedding了。而词嵌入(例如word2vec,GloVe)通常是在一个较大的语料库上利用词的共现统计预训练得到的。例如king和queen上下文时常相同或相似,所以词向量相似,在向量空间中词距离很近。
但是word2vec在训练完毕后,某个单词的表示向量就已经确定了,这样的向量对于一词多义其实是没有帮助的,换一个语境单词所表达的意思就完全不一样的,即Word2vec的处理其实是与上下文无关的(虽然可能用了多个不同语境的句子进行计算,但是最后总会得到一个向量,无法得到区分)。虽然可以在此基础之上做一些聚类,但是也只是治标不治本。那如何做到静态变动态呢?
ELMo(embedding from language models)
paper:https://arxiv.org/pdf/1802.05365.pdf
官网:https://allennlp.org/elmo
code:https://github.com/allenai/allennlp

ELMO的fine-turning:在使用中动态调整。
即,对于已经用语言模型训练好了的Word Embedding,虽然无法处理多义词,但在句子中使用这个词向量的时候,会结合当前句子的上下文去调整这个单词的Embedding,就ok了。(有点不同的是,NLP的pre往往是无监督的)
- 实现细节如上图。想要结合上下文信息,很自然的想法就是利用LSTM,
是句子的开头要逐词的预测下一位。(这个bilstm就可以理解为 nlp的fine-turning…有时候也把原输入embedding也拼接,即三个向量的cat)另外由于ELMo的输入是字母为单位,而不是单词,所以对于 hhhhhh 这种没有记录的单词也有很好的效果,至少能给出相近词性的解释。 - ELMo是基于BiLSTM来抽取文本特征的,即得到左右绿色和蓝色的两个LSTM特征后,直接拼接(或者用alpha做控制)输入到模型中去做下游任务。
- 最后通过打印出在不同下游预训练任务中哪些特征比较重要,如右下角,在不同的时候某些特征参数会格外的large,这在BERT等其他模型中可以观察到,即预训练模型究竟做了什么,它是怎么根据应用而适时的调整词向量的。

GPT(Generative Pre-Training)
paper:https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf
code:https://openai.com/blog/language-unsupervised/

GPT和ELMo一样,也是先语言模型预训练embedding,然后再fine-turning。fine-turning的不同点在于
- LSTM升级为Transformer提取特征
- Bi舍弃,变成单向而不是双向。作者认为如果双向,在编码解码中有些单词可能会间接的作弊,即提前的‘’看到‘’自己。(但是实际证明上下文信息对词语的理解是非常重要了,所以之后的模型还是使用了双向,并使用别的trick解决“作弊”问题)
由于结果固定住了,GPT在使用时需要让 下游任务 往GPT的输出靠拢,不过效果好什么都中。
- 序列标注:中文分词,词性标注,命名实体识别,语义角色标注等。
- 分类任务:文本分类,情感计算
- 句子关系判断:Entailment,QA,语义改写,自然语言推理
- 生成式任务:机器翻译,文本摘要,写诗造句,看图说话
- 细分下来有,自然语言十项全能挑战(decaNLP),涉及十个任务:问答,机器翻译,摘要,自然语言推理,情感分析,词性标注,关系抽取,目标导向对话,数据库查询生成和代词解析

BERT(Bidirectional Encoder Representation from Transformer)
划时代之作。
paper:https://arxiv.org/abs/1810.04805
code:https://github.com/google-research/bert

- LSTM太慢了啦 —> 还是Transformer吧,并行而且还没有梯度的问题
- 人类理解语言会同时考虑上下文的 —> 双向吧,只要不看要预测的部分就可以
从图看BERT的输入是两个句子A和B进行成对训练,输入以【CLS】(classification token)隔开,句子则是【SEP】(special token)隔开。。然后特征由三个部分组成:词嵌入后的token embedding,句子类别的符号segment embedding句子A,句子B,词的位置信息position embedding,这跟Transformer里面是一致的。这三个部分相加之后作为输入。然后Loss=MLM+NSP进行fine-turning:
- Masked Language Model(MLM)。灵感来自完型填空,先扣掉(以【MASK】标记),再尝试恢复。【MASK】总词的15%,在15%中:80%用[MASK]标记替换,10%用其他的词随机替换,10%保持原词不做替换,这一部分的loss只针对【MASK】位置的输出。(即其他位置的词输出正确与否,不在MLM计算)
- Next Sentence Prediction(NSP)。NSP关注两个句子间的关系,所以输出是binarized task即成对训练。对于成对训练的【句子A,句子B】的构建,50%的两个句子对间有上下关系,此时label为IsNext或1,剩下50%的句子无上下关系(随机选择),标记label为NoNext或0。
Training tips:
- 1dupe_factor,从训练文档中重复使用一些数据的比例,训练集数目少的时候可以设置高一些
- 2max_predictions_per_eq,控制一句话里面被mask的最大数目
- 3do_whole_word_mask,如果是true就整个词蒙住,如果false则是会倾向蒙住单词里的字母(个人理解这种操作同样也是填空的一种形式,蒙住后的词同样是不认识的新词,需要靠语境来判断)
- 4length of a sentence is larger than the limit,句子中的最大长度限制
BERT的缺点:
- 【MASK】只会在预训练中使用,后续任务是不会出现的,所以导致训练环境和测试环境不一样(一个有mask,一个没有mask)。实际处理中,在后续任务时需要同样按相同的比率替换句子。即把输入序列中的k%(一般为15%,k太小:计算代价过大。k太大:剩下的上下文不足以准确预测)的词掩盖住,然后通过上下文预测这些被掩盖住的词。
- independent assumption。每个词都是独立的,很多短语被强行拆开(如New York)。(这点由于ELMo服从概率完备,用LSTM基于前面的词的隐向量,预测后面的句子,所以可以处理好这个问题,即词和词之间有联系的)
- 缺乏生成能力。是mased地方的重构。
BERT的本质
BERT的本质是Denoising Autoencoder,降噪自编码。
- 预训练是无监督的,寻找词自己之间的关系和表达。之后在下游任务中才会有监督。
- AE:输入–中间特征–输出,约束输入==输出。DAE:输入+噪声–中间特征–输出,在同样的约束下起降噪的作用使结果更加的鲁棒。而BERT:输入+【MASK】–Transformer–输出预测【MASK】。所以实际上,【MASK】的作用就是加了噪音,然后利用Transformer进行降噪。

XLNet(Generalized Autoregressive Pretraining for Language)
集大成者来了。
- 自回归语言模型(Autoregressive LM)。代表是ELMo 和 GPT,根据前文预测后面的单词或者反过来的思路。优点是:词与词之间是有联系的。缺点是:只能利用上文或者下文的信息,不能同时利用上文和下文的信息(ELMO虽然双向都做,但是是伪双向,即正向的时候用不到反向,反向用不到正向)。
- 自编码语言模型(Autoencoder LM)。代表BERT。优点:直接就是上下文都能够考虑到。缺点:1 词和词割裂 2使用了【MASK】使训练和测试的环境不一致。
XLNet:我要融合。我要构建一个
- 考虑上下文双向信息
- 考虑词间依赖关系
- 测试环境一致

融合思路显然是改装ELMo更为方便,只需要把ELMo变得可以处理真正的上下文就行。那么如何在只看得到前面词的时候,也能揉入后面的词?
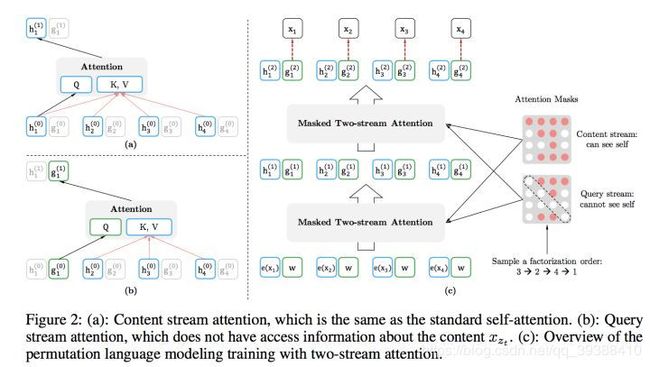
- 乱序全排列语言模型(Permutation Language model),即如果每个词都可以有不同的位置,就可以利用到上下文信息了!如上图 h 1 ( 1 ) , h 1 ( 2 ) h^{(1)}_1,h^{(2)}_1 h1(1),h1(2)上标是层数(多层Transformer),下标是位置信息,正常情况下一个四个词的句子词顺序是【1 2 3 4】,那么打乱这个顺序变成【3 2 4 1】,【2 4 3 1】等等,那么在预测比如 x 3 x_3 x3的时候,【1 2 3 4】的3的前面有1 2的信息,【3 2 4 1】的3的没有其他的词即会是开始符,【2 4 3 1】的3的前面有2 4的信息可以利用,以前正常的顺序是无法看到4号的信息,打乱之后就可以用到了。
- 在具体的实现中,不用打乱输入(即还是1234),只是此时的3要用到谁,就连接谁,如上图的第2个图【2 4 3 1】,3的前面有2 4的信息可以用,那么 h 3 ( 1 ) h^{(1)}_3 h3(1)连接了 x 2 x_2 x2和 x 4 x_4 x4,还有mem(即在当前词输出前,已经输出的隐向量表示,即在预测3号的时候,实际上2和4已经输出了,mem是它俩的表示)
- 双流自注意力机制(Two-stream Self Attention)。PLM实际上已经完成了融合的任务,但是此处存在一个冲突问题需要解决即:1 预测自己时不能有自己的内容信息(如果知道了 x 3 x_3 x3去预测 x 3 x_3 x3就作弊了,只能用 x 2 x_2 x2和 x 4 x_4 x4的信息预测 x 3 x_3 x3) 2预测别人时,自己由作为了上下文,又需要给出所有信息(内容信息+位置信息)。(预测完 x 3 x_3 x3后,需要输出 x 1 x_1 x1,此时 x 3 x_3 x3需要用到其他词的向量)。冲突就在于:既要没有自己,自己又不能丢?怎么办?
- two-stream,双流,一个流content stream是既有内容又有位置信息,一个流query stream是只有位置信息,没有自己的内容信息。实现如下图, h 1 h_1 h1和 g 1 g_1 g1分别是两个流的隐层,图a是标准self-Attention组成的content stream,查询 h 1 ( 0 ) h_1^{(0)} h1(0)得到 h 1 ( 1 ) h_1^{(1)} h1(1),图b是不能跟自己内容有连接的query stream,然后在不同情况下用不同的流进行计算就行。
- 此外关于打乱的顺序由利用Attention masks实现,即如图中的矩阵红色代表有关系。(在content stream第一行与1234有关,第二行与23有关,第三行与3有关,第四行与234有关,即逻辑上的顺序是【3 2 4 1】,query stream中则是没有对角线即不能看到自己,不作弊)通过不同的掩码,就能得到不同逻辑顺序的句子了。
Trick:
引入了Transformer-XL做提升,Transformer-XL=Transformer+RNN。
- 原因:Transformer的最大缺点是每个Transformer的所有的Decoder层的矩阵都要保存以便BP,但是预训练模型往往需要很大量的计算,比如直接输入好几本书,计算资源消耗比较大,所以导致Transformer每次无法输入很长的文本进行训练。
- 主要思路:相对位置编码以及分段RNN机制。即第一页句子在第一个Transformer训练,第二页在另一个训练,由于两者之间可能存在关系,再使用分段RNN机制进行连接。实践已经证明这两点对于长文档任务是很有帮助的。
未来:1Transformer-XL为什么有效?2permutation的采样如何更加有效 3compress成Albert 4合适的融合应用。
和BERT其实是一回事?
- Bert是直接在输入端显示地通过引入Mask标记,在输入侧隐藏掉一部分单词,让这些单词在预测的时候不发挥作用,要求利用上下文中其它单词去预测某个被Mask掉的单词;而XLNet则抛弃掉输入侧的Mask标记,通过Attention Mask机制,在Transformer内部随机Mask掉一部分单词(这个被Mask掉的单词比例跟当前单词在句子中的位置有关系,位置越靠前,被Mask掉的比例越高,位置越靠后,被Mask掉的比例越低),让这些被Mask掉的单词在预测某个单词的时候不发生作用。
(详细请参看张俊林大牛:https://zhuanlan.zhihu.com/p/70257427)
应用BERT提特征
实际训练BERT 需要用 WordPiece工具分词,并插入各种特殊的分离符如([CLS],用来分隔样本)和分隔符([SEP],用来分隔样本内的不同句子)等等细节,其训练花费很轻松只需要76分钟!(如果我们能有1024块TPU…在16 个 Cloud TPU 上则需要训练 4 天, GPT-2是BERT的3倍,而XLNet在128 个 Cloud TPU v3 下需要训练 2 天半,花费以美金算emmm)
所以还是看怎么使用Pretraning!
版本一:使用自己的词汇库进行训练
https://github.com/codertimo/BERT-pytorch
1. pip install bert-pytorch
2. 准备语料库,两个句子在同一行,并用 \t 分割。如
Welcome to the \t the jungle\n
I can stay \t here all night\n
3. 建立vocab
bert-vocab -c data/corpus.small -o data/vocab.small
4. 训练bert
bert -c data/corpus.small -v data/vocab.small -o output/bert.model
版本二:利用训练好的模型进行向量抽取
https://github.com/hanxiao/bert-as-service 或者keras的版本:https://github.com/CyberZHG/keras-bert
1. 下载英文词向量:https://storage.googleapis.com/bert_models/2018_11_03/english_L-12_H-768_A-12.zip
2. 或者中文词向量:https://storage.googleapis.com/bert_models/2018_11_03/chinese_L-12_H-768_A-12.zip
3. 开启服务器BERT:bert-serving-start -model_dir /tmp/english_L-12_H-768_A-12/ -num_worker=4
访问本机
from bert_serving.client import BertClient
bc = BertClient()
bc.encode(['First do it', 'then do it right', 'then do it better'])
远程访问,加入端口号
from bert_serving.client import BertClient
bc = BertClient(ip='xx.xx.xx.xx') # ip address of the GPU machine
bc.encode(['First do it', 'then do it right', 'then do it better'])
或者跑example的代码,亲测真好用…给大佬加星。
版本三:直接使用开源工具
文本摘要:https://github.com/dmmiller612/bert-extractive-summarizer
from summarizer import Summarizer
text='xxxx xxx'
model=Summarizer()
model(text)
ALBERT: A Lite BERT for Language Understanding:
最后,最近又有火爆的模型出现了!由于BERT参数太了(base版1.1亿,large版3.4亿),ALBERT模型的目的是实现参数量轻量级。它主要的优化是:
- factorized embedding parametrization。在one-hot处理的过程中先用矩阵做低秩分解,从 O ( V × H ) O(V\times H) O(V×H)到 O ( V × + E × H ) O(V\times+E\times H) O(V×+E×H),减少了19M个参数。
- 共享Transformer注意力所有层的参数。即不管多少层,每层参数都用一样的(虽然参数共享,但每一层的输出不一样,Attention的动态调整效果也是不一样的)。以前使用12层Transformer,所以参数数量变成12分之一。
- 不要dropout。提升不明显,还占内存,所以不使用。
- 将参数变少后性能略有降低,然后学Alex把网络加宽加深,这样在参数量比较小的情况下得到了比BERT性能很好的提升。
- 之前有人发文诟病:NSP构建正负例的方式,由于负例的句子是随机组合,这样容易让网络找到topic进行学习(即线索词,A句子和B句子很无关,所以很容易分别上下文是否有联系)。所以作者将NSP变成SOP(sentence order prediction),即直接把A,B对换就行了,这样保证了topic一致的情况下构建了正负例。
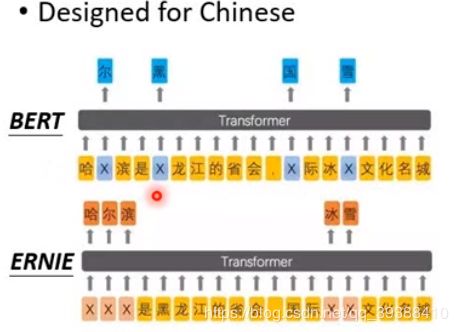
ERNIE2.0
ERNIE1.0如上,是把BERT改为适合中文的模型,想法是来自对于中文的词很容易猜到masked某个词,所以masked是一整个词(做到这一点将BERT融合了知识图谱(knowledge graphs,KG),以知识图谱中的多信息实体(informative entity)作为外部知识改善语言表征)。
而ERNIE2.0挺有意思的,也放上来一下,它主要贡献是两个:
- 序列多任务学习的预训练任务机制(sequential multi-task learning),使模型能够学习到词汇,语法,语义信息。不同于持续学习和多任务学习,序列多任务学习在引入新的训练任务时,先利用之前学习到的参数对模型进行初始化,再同时训练新任务和旧任务。
- 定制和引入了多种预训练任务。侧重词汇的任务(mask,大写字词预测,字词-文章关系),侧重结构/语法的任务(词语重排序,语句距离),侧重语义的任务(文章关系任务,信息检索相关性任务)。
Future?
- Pre+KG。
- Pre+ENDEcodeer。如UULM。
- Pre+Multi-Learning。如MT-DNN,ERNIE。
- Updated Pre。如XLNet,RoBERTa。
- Pre+Chinese。BERT-WWM。
- Pre+Turning。
- Updated Transformer?Transformerxl?
模型对比

预训练语言模型(PLM)论文清单:https://github.com/t/thunlp/PLMpaper