中文分词算法
写在最前面:
由于我们chinese language的特殊性,不和英文中有天然空格符一样,我们需要将汉字序列切分成单独的词。
分词算法是文本挖掘的基础,通常对整个模型的效果起着较大的决定作用。中文分词算法主要分为基于词表的分词算法、基于统计模型的分词算法、基于序列标注的分析算法。下面我们来一一剖析吧
准备好了吗!迎接疾风吧,数学能让人清醒!!!
目录
1.基于词表的分词算法
1.1正向最大匹配法(FMM)
1.2逆向最大匹配法(BMM)
1.3双向最大匹配法
2.基于统计模型的分析算法
2.1基于N-gram语言模型的分词方法
3.基于序列标注的分词算法
3.1基于HMM的分词方法
3.2基于MEMM的分词方法
3.3基于CRF的分词方法
3.4基于深度学习的端对端的分词方法
1.基于词表的分词算法
1.1正向最大匹配法(FMM)
概念:对于输入的一个文本序列从左至右,以贪心的算法切分出当前位置上长度最大的词
分词原理:单词的颗粒度越大,所能表示的含义越确切
分词步骤:
- 首先我们有一个词库word_dict还一个待分词的字符串s,首先我们计算得到词库中最长词语的长度假设为m,从字符串第一个位置开始,选择一个最大长度的词长片段,如果该字符串的长度不足最大词长,则选择该全部字符串;
- 判断选择出来的字符串片段是否在词库中,若在,则将此词分离出来,若不在,则从右边开始,逐一减少一个字符,直到这个片段存在在词典中结束,或者以只剩下最后一个字结束;
- 字符串变为上一步截取分词后剩下的部分序列,直到序列完全被分割。
哈哈哈,上面肯定看的迷迷糊糊的,大家都这么过来的,文字太多容易视觉疲劳,那我们来举个小小的栗子吧。
比如说待分割的序列s=‘我爱长沙理工大学’,然后我们的word_dict={'喜欢',‘长沙’,‘长沙理工大学’,...}假设其中最长词语的长度是6,接下来步骤就是
- ‘我爱长沙理工’(不在)-->'我爱长沙理‘(不在)-->'我爱长沙’(不在)-->'我爱长'(不在)-->'我爱'(不在)-->'我' ====剩余一个字,加入词典
- ‘爱长沙理工大’(不在) -->'爱长沙理工'(不在)-->’爱长沙理‘(不在)-->'爱长沙'(不在)-->'爱长'(不在)-->'爱'====剩余一个字,加入词典
- '长沙理工大学'====在词典中,加入,遂分割完毕
于是"我爱长沙理工大学"就分割成了"我/爱/长沙理工大学"
1.2逆向最大匹配法(BMM)
如果比较深入的理解啦1.1中所说的正向最大匹配,那么只要将正向从左至右筛选的顺序换成从右至左筛选就好了。
其实90%(这个数字我乱编的,你可以理解成为大部分的意思)的情况下正向最大匹配法和逆向最大匹配法分词的结果都是一样的,但是也存在不一样的哟,比如说'结婚的和尚未结婚的'通过FMM可能会被分割成'结婚/的/和尚/未/结婚的/',但是通过BMM可能就会被分割成'结婚/的/和/尚未/结婚/的'
1.3双向最大匹配法
双向最大匹配法就是将正向和逆向最大匹配法进行比较得出最后分词结果,在中文信息处理系统中被广泛运用
启发式规则:
1. 如果正反向分析结果词数不同,则取分析数较少的那个
2. 如果分词结果词数相同
- 分词结果相同,就说明没有歧义,可返回任意一个
- 分词结果不同,返回其中单字较少的那个
2.基于统计模型的分析算法
2.1基于N-gram语言模型的分词方法
wikipedia上有关n-gram的定义:
n-gram是一种统计语言模型,用来根据前(n-1)个item来预测第n个item。在应用层面,这些item可以是音素(语音识别应用)、字符(输入法应用)、词(分词应用)或碱基对(基因信息)。一般来讲,可以从大规模文本或音频语料库生成n-gram模型。 习惯上,1-gram叫unigram,2-gram称为bigram,3-gram是trigram。还有four-gram、five-gram等,不过大于n>5的应用很少见。
如何计算一个句子出现的概率
假设句子s=w1,w2,...wn,那么不妨把s展开表示
p(s) = p(w1,w2,...wn) = p(w1)p(w2|w1)p(w3|w1,w2)***p(wn|w1,...wn-1)
那么问题来了,计算p(w1)简单,p(w2|w1)也能算,p(wn|w1,w2,..wn-1)就额非常费力了,所以我们要很自然的引出马尔科夫链,假设一个词wi出现的概率只与它前面的wi-1词有关,那么
p(s) = p(w1,w2,...wn) = p(w1)p(w2|w1)p(w3|w2)...p(wn|wn-1)
常用于搜索引擎
3.基于序列标注的分词算法
3.1基于HMM的分词方法
我要说的第一点就是他是个生成模型,所谓生成模型即是学习得到联合概率分布P(x,y),即特征x和标记y共同出现的概率,然后求条件概率分布。能够学习到数据生成的机制。
他是将分词问题做个转换,将分词问题转换为对句子中的每个字打标注,标注这个字要么是一个词的开始B(begin),要么是一个词的中间M(middle),要么是一个词的结束(E),要么是单个字S(single),我们将句子标注好了,那么分词结果也就出来了
| X | 我 | 爱 | 长 | 沙 | 理 | 工 | 大 | 学 |
| Y | S | S | B | M | M | M | M | E |
基于HMM的分词方法:属于由字构词的分词方法,由字构词的分词方法思想并不复杂,它是将分词问题转化为字的分类问题(序列标注问题)。从某些层面讲,由字构词的方法并不依赖于事先编制好的词表,但仍然需要分好词的训练预料 。
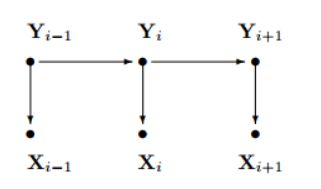
它满足两个假设
- markov链是齐次一阶的
- 观测独立假设
由于HMM是一个生成模型,X为观测序列,Y为隐序列,则X,Y的联合分布为

3.2基于MEMM的分词方法
猜猜我要说的第一点是什么,没错,它是个判别式模型!!!,它是直接通过P(Y|X)来建模的
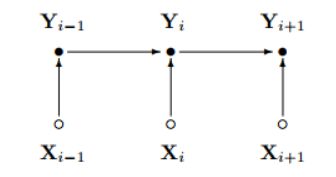

P(i | i',o)通过最大熵分类器建模得到 ,即
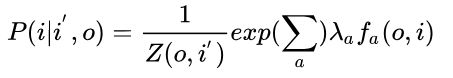
其中Z(o,i')为归一化因子,fa(o,i) 是特征函数,需自己定义,而入a为特征函数的权重,需要通过训练得到
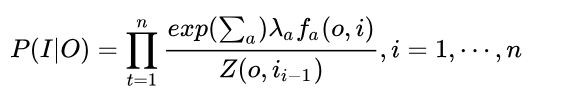
求解步骤:
- 先定义好特征函数fa(o,i)
- 根据已有数据训练得到入a,即得到模型
- 用模型得到数据标注或者求概率
优点:相比于HMM
- 打破了观测独立假设:克服了HMM输出独立性问题,通过引入特征函数使得模型比HMM拥有更多信息,而且最大熵则从全局角度来建模,它“保留尽可能多的不确定性,在没有更多的信息时,不擅自做假设”
缺点:Lable Bias Problem(标注偏差问题)
- 由于MEMM的当前状态只与当前观测以及上一状态有关,导致隐状态中有更少转移的状态拥有的转移概率普遍较高,简单的说就是MEMM中概率最大路径更容易出现在转移少的状态中。
- 解决方案:引入全局化特征可以解决标注偏置问题,那么就很自然的说到我们的3.3CRF方法啦
3.3基于CRF的分词方法
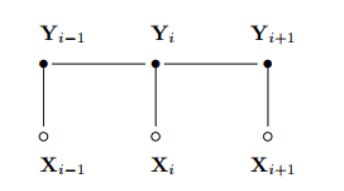
CRF是无向图模型

在这里Z(O)是用来归一化的
P (I|O)表示在给定观测序列O=(O1,O2,...Oi)的情况下,我们用CRF求出的隐序列I = (I1,I2,...Ii)的概率,注意这里I是一个序列,有多个元素
优点:
- 克服了HMM的观测独立假设以及MEMM标注偏差问题
缺点:
- 全局化特征模型会更复杂,导致训练周期长,计算量较大
3.4基于深度学习的端对端的分词方法
最近,基于深度神经网路的序列标注算法在词性标注、命名实体识别问题上取得了优秀的进展。词性标注、命名实体识别都属于序列标注问题,这些端到端方法可以迁移到分词问题上,免去CRF的特征模板配置问题。但与所有深度学习的方法一样,它需要较大的语料库才能体现优势。
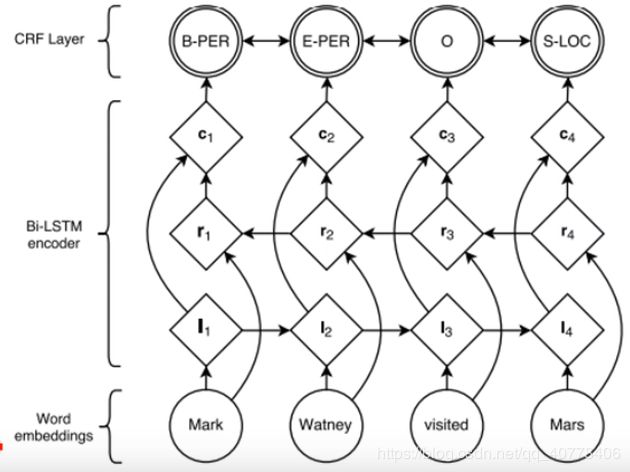
BiLSTM-CRF的网络结构如上图所示,输入层是一个embedding层,经过双向LSTM网络编码,输出层是一个CRF层,经过双向LSTM网络输出的实际上是当前位置对于各词性的得分,CRF层的意义是对词性得分加上前一位置的词性概率转移的约束,其好处是引入一些语法规则的先验信息 。
其实说白了,就是一个深度学习的套路啦,扔进去训练就完事了。
写在后面:其实还有很多细枝末节没有讲清楚,我自己再看也是晕晕的,但是不要怕,多看看,多想想,自然而然也就懂了,各位加油,如有错误,还肯定各大佬批评指正
参考:各路博客以及各路论文以及各路视频网站,只是小小总结一下,感谢巨人的肩膀。