【可能是全网最好的】MySQL基础入门总结笔记
之前已经介绍过了MySQL,收到了很多好评,感谢喜欢文章的朋友的支持。
这次是为了优化其中的细节部分的内容和排版,安装登陆等操作就不再赘述。
关于存储引擎,触发器,索引,锁及优化部分的高级内容大概过年的时候发出。
环境准备
- 导入myemployees数据库
在SQLyog软件中右键选择执行SQL脚本。(没有对应资料的私信我)

选择myemployees的sql脚本,点击执行即可。

之后导入数据库成功,刷新后可以发现多出了一个数据库。
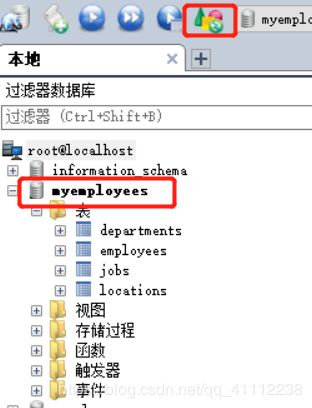
- 部门表departments

- 员工表employees

- 工种表jobs

- 位置表locations

DQL
1 基础查询
语法:
select 查询列表 from 表名;
特点:
- 查询的结果集是一个虚拟表
- select后面的查询列表可以由多个部分组成,中间由逗号隔开
- 执行顺序 例如进行以下查询,是先查询是否存在该表,再查询具体的查询列表是否存在。
- 查询列表可以是:字段、表达式、常量、函数等
1 查询常量
SELECT 100;
2 查询表达式
SELECT 100%3;
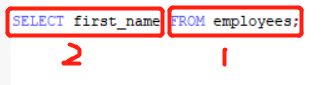
3 查询单个字段
SELECT last_name FROM employees;
4 查询多个字段 选中后按F12可以对齐格式
SELECT last_name, email FROM employees ;
5 查询所有字段
SELECT * FROM employees;
6 查询函数(调用函数,获取返回值)
查询当前所用数据库
SELECT DATABASE();
查询版本
SELECT VERSION();
查询用户
SELECT USER();
7 起别名,可以改变查询结果中的列名
方式一:使用as关键字 语义性更强
SELECT USER() AS '用户名';
方式二:使用空格
SELECT USER() '用户名';
8 拼接
需求:拼接first_name 和 last_name成为全名
SELECT CONCAT(first_name, ' ', last_name) AS 'name' FROM employees ;
9 去重
需求:查询员工涉及到的所有部门
SELECT DISTINCT(department_id) FROM employees;
10 查看表的结构
DESC employees;
SHOW COLUMNS FROM employees;
补充:mysql中+的作用
- 如果两个操作数都是数值型,直接相加
- 如果其中一个操作数是数值型 将字符型尝试转换为数值型,如果无法解析字符串,当作
0计算,例如'abc'+1结果为1 - 如果其中一个操作数为
null,结果就为null
基础查询作业及答案
-
下面的语句是否可以执行成功(可以)
select last_name , job_id , salary as sal from employees; -
下面的语句是否可以执行成功 (可以)
select * from employees; -
找出下面语句中的错误
select employee_id , last_name,salary * 12 “ANNUAL SALARY” from employees;
错误:应该使用英文的逗号和双引号 -
显示表 departments 的结构,并查询其中的全部数据
DESC departments;
SELECT * FROM departments; -
显示出表 employees 中的全部 job_id(不能重复)
SELECT DISTINCT(job_id) FROM employees; -
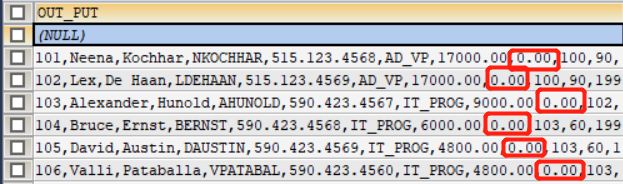
显示出表 employees 的全部列,各个列之间用逗号连接,列头显示成 OUT_PUT
如果其中一个列为null,拼接结果就为null,使用ifnull函数给值为null的列赋值
ifnull(exp1,exp2),如果exp1为null,显示exp2的值,否则显示exp1的值。SELECT CONCAT( employee_id,',', first_name,',', last_name,',', email,',', phone_number,',', job_id,',', salary,',', IFNULL(commission_pct, 0),',', manager_id,',', department_id, ',', hiredate ) AS 'OUT_PUT' FROM employees ;当奖金率为null时,设为0.00
2 条件查询
语法:
select 查询列表 from 表名 where 筛选条件;
特点:
- 执行顺序
①from字句
②where字句
③select字句
- 按条件表达式筛选
关系运算符:大于>,大于等于>=,小于<,小于等于<=,等于=,不等于<>
逻辑运算符:与and,或or,非not

按关系表达式筛选
-
案例1 查询部门编号不是100的员工信息
SELECT * FROM employees WHERE department_id <> 100; -
案例2 查询工资<15000的姓名,工资
SELECT last_name,salary FROM employees WHERE salary<15000;
按逻辑表达式筛选
-
案例1 查询部门编号不是50-100之间的员工信息
SELECT * FROM employees WHERE NOT (department_id >50 AND department_id <100); -
案例2 查询奖金率大于0.03或者员工编号在60-110之间的员工信息
SELECT * FROM employees WHERE commission_pct>0.03 OR (employee_id >=60 AND employee_id <=110);
模糊查询
1 LIKE 一般和通配符搭配使用,对字符型数据进行部分匹配查询
常见的通配符: _任意单个字符 %任意多个字符
-
案例1 查询姓名中包含字符a的员工信息
SELECT * FROM employees WHERE last_name LIKE '%a%'; -
案例2 查询姓名中最后1个字符为e的员工信息
SELECT * FROM employees WHERE last_name LIKE '%e'; -
案例3 查询姓名中第1个字符为e的员工信息
SELECT * FROM employees WHERE last_name LIKE '__e%'; -
案例4 查询姓名中第2个字符为_的员工信息 使用\转义 也可使用escape自定义转义字符
SELECT * FROM employees WHERE last_name LIKE '_\_%';
SELECT * FROM employees WHERE last_name LIKE '_$_%' ESCAPE '$';
2 IN 查询某字段的值是否属于指定的列表值内
-
案例1 查询部门编号是30 / 50 / 90 的员工名
SELECT last_name FROM employees WHERE department_id IN (30, 50, 90) ; -
案例2 查询工种编号不是SH_CLERK或IT_PROG的员工信息 非数值常量值用引号引起
SELECT * FROM employees WHERE job_id NOT IN('SH_CLERK','IT_PROG');
3 BETWEEN AND 判断某个字段的值是否介于某区间之间
-
案例1 查询部门编号在30-90之间的员工姓名
SELECT last_name FROM employees WHERE department_id BETWEEN 30 AND 90; -
案例2 查询年薪不是10000-20000之间的员工姓名,工资,年薪
SELECT last_name,salary,salary*12*(1+IFNULL(commission_pct,0)) s FROM employees WHERE salary*12*(1+IFNULL(commission_pct,0)) NOT BETWEEN 10000 AND 20000;
4 isnull 判断空值
- 案例1 查询没有奖金的员工信息
SELECT * FROM employees WHERE commission_pct IS NULL;
=只能判断普通数值
IS 只能判断null值
<=> 既能判断普通数值,又能判断null值
条件查询作业及答案
- 查询工资大于 12000 的员工姓名和工资
SELECT last_name,salary FROM employees WHERE salary >12000; - 查询员工号为 176 的员工的姓名和部门号
SELECT last_name,department_id FROM employees WHERE employee_id =176; - 选择工资不在 5000 到 12000 的员工的姓名和工资
SELECT latst_name,salary FROM employees WHERE salary NOT BETWEEN 5000 AND 12000; - 选择在 20 或 50 号部门工作的员工姓名和部门号
SELECT last_name,department_id FROM employees WHERE department_id IN(20,50); - 选择公司中没有管理者的员工姓名及 job_id
SELECT last_name,job_id FROM employees WHERE salary >12000; - 选择公司中有奖金的员工姓名,工资和奖金级别
SELECT last_name,salary FROM employees WHERE manager_id IS NULL; - 选择员工姓名的第三个字母是 a 的员工姓名
SELECT last_name FROM employees WHERE last_name LIKE '__a%'; - 选择姓名中有字母 a 和 e 的员工姓名
SELECT last_name FROM employees WHERE last_name LIKE '%a%' AND last_name LIKE '%e%'; - 显示出表 employees 表中 first_name 以 'e’结尾的员工信息
SELECT * FROM employees WHERE first_name LIKE '%e'; - 显示出表 employees 部门编号在 80-100 之间 的姓名、职位
SELECT last_name,job_id FROM employees WHERE department_id BETWEEN 80 AND 100; - 显示出表 employees 的 manager_id 是 100,101,110 的员工姓名、职位
SELECT last_name,job_id FROM employees WHERE department_id IN(100,101,110);
3 排序查询
语法:
select 查询列表 from 表名 where 筛选条件 order by 排序列表;
特点:
- 执行顺序
①from字句
②where字句
③select字句
④order by子句- 排序列表可以是单个字段、多个字段、表达式、函数、列数及以上组合
- 升序,通过asc,默认行;降序,通过desc

1 按单个字段排序
- 案例1 查询员工编号大于120的员工信息,按工资升序
SELECT * FROM employees WHERE employee_id >120 ORDER BY salary ASC;
2 按表达式排序
-
案例1 对有奖金的员工,按年薪降序查询
SELECT * FROM employees WHERE commission_pct IS NOT NULL ORDER BY salary * 12 * (1+ commission_pct) DESC ;
3 按别名排序(WHERE 不能使用别名,因为别名起在select中,select在where后执行)
-
使用上述案例
SELECT *,salary*12*(1+ commission_pct) AS 年薪 FROM employees WHERE commission_pct IS NOT NULL ORDER BY 年薪 DESC ;
4 按函数的结果排序
- 案例1 按姓名的字数长度进行升序排列
SELECT last_name FROM employees ORDER BY LENGTH(last_name);
5 按多个字段进行排序
- 案例1 查询员工的姓名,先按工资升序,再按部门编号降序排列
SELECT last_name FROM employees ORDER BY salary ASC,department_id DESC;
6 按列数排序
- 案例1 按第二列进行排序
SELECT * FROM employees ORDER BY 2;
2代表第二列,相当于 ORDER BY first_name,语义性差
排序查询作业及答案
1 查询员工的姓名和部门号和年薪,按年薪降序 按姓名升序
SELECT
last_name,
department_id,
salary * 12 * (1+ IFNULL(commission_pct, 0)) AS 年薪
FROM
employees
ORDER BY 年薪 DESC,
last_name ;
2.选择工资不在 8000 到 17000 的员工的姓名和工资,按工资降序
SELECT
last_name,
salary
FROM
employees
WHERE salary NOT BETWEEN 8000
AND 17000
ORDER BY salary DESC ;
3 查询邮箱中包含 e 的员工信息,并先按邮箱的字节数降序,再按部门号升序
SELECT
*
FROM
employees
WHERE email LIKE '%e%'
ORDER BY LENGTH(email) DESC,
department_id ASC ;
4 常见函数
函数:
类似于Java中的方法,为了解决某个问题将编写的一系列命令集合封装在一起,对外仅暴露方法名,供外部调用
常见函数:
字符函数、数学函数、日期函数、流程控制函数
1 字符函数
1 CONCAT 拼接字符
SELECT CONCAT(first_name,last_name) FROM employees;
2 LENGTH 获取字节长度
SELECT LENGTH('hello');//5
SELECT LENGTH('字符');//6,一个汉字占3个字节
3 CHAR_LENGTH 获取字符长度
SELECT CHAR_LENGTH('hello字符');//7
4 SUBSTR 截取字符串
SUBSTR(str,起始索引,截取的字符长度)
SUBSTR(str,起始索引)
SELECT SUBSTR('林婉儿是大宗师',1,3);//林婉儿,sql索引从1开始
SELECT SUBSTR('大宝是影子',4);//影子
5 INSTR 获取字符第一次出现的索引
SELECT INSTR('李纯扮演的是司理理,司理理是李纯演的','李纯');//1
6 TRIM 去除前后指定字符,默认去掉空格
SELECT TRIM(' 范 闲 杀了程巨树 ');//范 闲 杀了程巨树
SELECT TRIM(' ' FROM ' 范 闲 杀了程巨树 ');//范 闲 杀了程巨树
7 LPAD/RPAD 左填充/右填充
SELECT LPAD('陈萍萍',10,'a');//aaaaaaa陈萍萍
SELECT RPAD('陈萍萍',10,'a');//陈萍萍aaaaaaa
8 UPPER/LOWER变大/小写
案例:查询员工表中的姓名,要求格式:姓首字符大写,其他字符小写,名所用字符大写,姓名之间用_分隔,起别名name
SELECT SELECT
CONCAT(
UPPER(SUBSTR(last_name, 1, 1)),
LOWER(SUBSTR(last_name, 2)),
'_',
UPPER(first_name)
) AS NAME
FROM
employees ;
9 STRCMP 比较两个字符大写
1表示大于,-1表示小于,0表示等于
SELECT STRCMP('abc','aaa');//1
SELECT STRCMP('a','a');//0
10 LEFT/RIGHT 左/右截取
SELECT LEFT('二皇子是boss',3);//二皇子
SELECT RIGHT('太子喜欢他姑姑',2);//姑姑
2 数学函数
1 ABS 求绝对值
SELECT ABS(-3);//3
2 CEIL 向上取整
SELECT CEIL(4.7);//5
3 FLOOR 向下取整
SELECT FLOOR(2.9);//2
4 ROUND 四舍五入
SELECT ROUND(1.82);//2
SELECT ROUND(1.82,1);//1.8
5 TRUNCATE 截断
SELECT TRUNCATE(1.8713,0);//1
SELECT TRUNCATE(1.8713,2);//1.87
6 MOD 取余
SELECT MOD(-10,3);//-1
3 日期函数
1 NOW 获取当前日期和时间
SELECT NOW();//2020-01-14 09:14:03
2 CURDATE 获取当前日期
SELECT CURDATE();//2020-01-14
3 CURTIME 获取当前时间
SELECT CURTIME();//09:14:03
4 DATEDIFF 获取两个日期之差
SELECT DATEDIFF('1996-02-06','1990-10-22');//1933(天)
5 DATE_FORMAT 日期转换字符串
SELECT DATE_FORMAT('1998-07-04','%Y年%m月%d日');//1998年07月04日
6 STR_TO_DATE 字符串转换日期
SELECT STR_TO_DATE('3/15 1997','%m/%d %Y');//1997-03-15
4 流程控制函数
1 IF 函数
类似于Java中三元表达式
SELECT IF(1>0,'成立','不成立');//成立
- 案例:如果有奖金,显示奖金,如果没有显示0
SELECT IF(commission_pct IS NOT NULL,commission_pct,0) FROM employees;
2 CASE 函数
情况1:类似于switch,实现等值判断
语法:
CASE 表达式
WHEN 值1 THEN 结果1
WHEN 值1 THEN 结果1
...
ELSE 结果n
END
案例:部门编号是30,工资显示2倍,部门编号50,工资显示3倍,否则不变
SELECT
department_id AS 部门编号,
salary AS 旧工资,
CASE
department_id
WHEN 30 THEN salary * 2
WHEN 50 THEN salary * 3
ELSE salary
END AS 新工资
FROM
employees ;
情况2:类似多重if语句,实现区间判断
语法:
CASE
WHEN 条件1
THEN 结果1
WHEN 条件2
THEN 结果2...
ELSE 结果n
END
案例:如果工资大于20000,显示A,如果大于15000,显示B,大于10000显示C,否则显示D
SELECT
salary AS 工资,
CASE
WHEN salary > 20000 THEN 'A'
WHEN salary > 15000 THEN 'B'
WHEN salary > 10000 THEN 'C'
ELSE 'D'
END AS 工资等级
FROM
employees ;
常见函数作业及答案
1 显示系统时间(注:日期+时间)
SELECT NOW();
2 查询员工号,姓名,工资,以及工资提高百分之 20%后的结果(new salary)
SELECT employee_id,last_name,salary,salary*1.2 FROM employees;
3 将员工的姓名按首字母排序,并写出姓名的长度(length)
SELECT last_name,LENGTH(last_name)
FROM employees
ORDER BY SUBSTR(last_name,1,1);
4 做一个查询,产生下面的结果:
SELECT
CONCAT(last_name,' earns ',salary,' monthly but wants ',salary*3)
AS dreammoney
FROM employees;
5 使用 CASE- when,按照下面的条件:
job grade /AD_PRES A /ST_MAN B /IT_PROG C/ SA_REP D /ST_CLERK E 产生下面的结果 Last_name/ Job_id /Grade
SELECT
last_name,
job_id,
CASE
job_id
WHEN 'AD_PRES' THEN 'A'
WHEN 'ST_MAN' THEN 'B'
WHEN 'IT_PROG' THEN 'C'
WHEN 'SA_REP' THEN 'D'
WHEN 'ST_CLERK' THEN 'E'
END AS grade
FROM
employees ;
5 分组函数
分组函数往往用于实现将一组数据进行统计计算,最终得到一个值,又称为聚合函数或统计函数。
分组函数清单:
sum(字段名) 求和
avg(字段名) 求平均值
max(字段名) 求最大值
min(字段名) 求最小值
count(字段名)计算非空字段值的个数
案例1 查询员工表中工资和,工资平均值,最高工资,最小工资,有工资的个数
SELECT SUM(salary),AVG(salary),MAX(salary),MIN(salary),COUNT(salary) FROM employees;
案例2 查询员工表中总记录数
SELECT COUNT(*) FROM employees;
案例3 查询员工表中月薪大于2500的人数
SELECT COUNT(*) FROM employees WHERE salary>2500;
案例4 查询有领导的人数
SELECT COUNT(manager_id) FROM employees;
count的补充:
1 查询结果集的行数,推荐使用*
SELECT COUNT(*) FROM employees;
SELECT COUNT(1) FROM employees;
效果和*一样,不一定是1,也可以是其他常量,相当于在所有行拼接了一个常量列
2 搭配distinct实现去重的统计
案例 查询有员工的部门个数
SELECT COUNT(DISTINCT department_id) FROM employees;
6 分组查询
语法:
SELECT 查询列表
FROM 表名
WHERE 筛选条件
GROUP BY 分组列表 HAVING 分组后筛选
ORDER BY 排序列表
特点:
1.查询列表往往时分组函数和被分组的字段
2.分组前筛选使用 WHERE 筛选的表是原始表 位置在 GROUP BY 前 分组后筛选使用 HAVING 筛选的表是分组后的结果集 位置在 GROUP BY 之后
执行顺序 FROM ->WHERE->GROUP BY->HAVING ->SELECT->ORDER BY
分组函数做条件只能放在 HAVING 后面
案例1 查询每个工种的员工平均工资
SELECT AVG(salary),job_id FROM employees GROUP BY job_id;
案例2 查询每个领导的手下人数
SELECT
COUNT(*),
manager_id
FROM
employees
WHERE manager_id IS NOT NULL
GROUP BY manager_id ;
案例3 查询邮箱中包含a字符的 每个部门的最高工资
SELECT
MAX(salary),
department_id
FROM
employees
WHERE email LIKE '%a%'
GROUP BY department_id ;
案例4 查询每个领导手下有奖金员工的平均工资
SELECT
AVG(salary),
manager_id
FROM
employees
WHERE commission_pct IS NOT NULL
GROUP BY manager_id ;
在分组结果上筛选,使用having子句:
案例5 查询哪个部门额员工个数 > 5
SELECT
department_id,
COUNT(*)
FROM
employees
GROUP BY department_id
HAVING COUNT(*) > 5 ;
案例6 查询每个工种有奖金的员工的最高工资大于12000的工种编号和最高工资
SELECT
job_id,
MAX(salary)
FROM
employees
WHERE commission_pct IS NOT NULL
GROUP BY job_id
HAVING MAX(salary) > 12000 ;
案例7 查询领导编号 > 102 的每个领导手下的最低工资大于5000的领导编号和最低工资
SELECT
manager_id,
MIN(salary)
FROM
employees
WHERE manager_id > 102
GROUP BY manager_id
HAVING MIN(salary) > 5000 ;
案例8 查询每个工种有奖金,最高工资>6000的员工的工种编号和最高工资,按最高工资升序
SELECT job_id,MAX(salary)
FROM employees
WHERE commission_pct IS NOT NULL
GROUP BY job_id
HAVING MAX(salary)>5000
ORDER BY MAX(salary);
案例9 查询每个工种每个部门的最低工资,并按最低工资降序
SELECT
job_id,
department_id,
MIN(salary)
FROM
employees
GROUP BY job_id,
department_id
ORDER BY MIN(salary) DESC ;
7 连接查询
又称多表查询,当我们要查询的字段涉及多个表时,就会用到连接查询
需要导入新的sql脚本,没有的私我

girls表的内容:
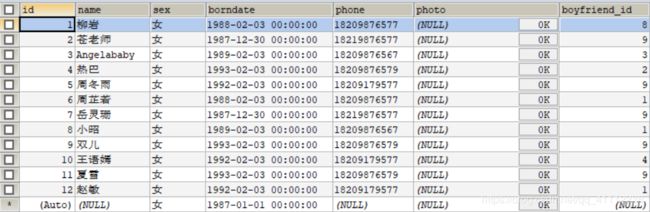
boys表的内容:

如果我们想查询女神名和对应的男朋友名,假如我们使用
SELECT NAME,boyName FROM beauty,boys
得到的结果:
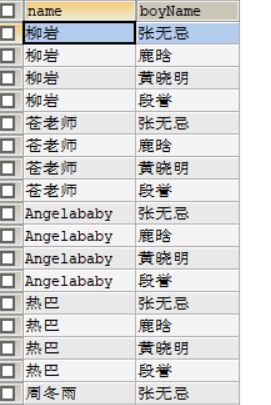
这样的结果显然不是我们想要的,这样的现象是因为没有筛选和连接条件,所以每一条都会互相匹配成功,这种现象叫做笛卡尔乘积现象,假设A表有m行,B表有n行,最终的结果为m*n行。
产生问题的原因为没有添加有效的连接条件。
正确的查询sql语句:SELECT NAME,boyName FROM beauty,boys WHERE boyfriend_id=boys.id;
分类:
- 按年代
sql92标准 仅支持内连接
sql99标准【推荐】支持除了全外连接的连接 - 按功能
内连接:等值连接/非等值连接/自连接
外连接:左外连接/右外连接/全外连接(用于查询主表有但从表没有的记录)
交叉连接
SQL92语法
内连接
1 等值连接
语法:
SELECT 查询列表 FROM 表名1 [AS] 别名1,表名2 [AS] 别名2... WHERE 等值连接条件
特点:
1.为解决多表字段名称重复问题,往往为表起别名,提高语义性
2.表的顺序无要求
案例1 查询员工名和部门名
SELECT last_name,department_name FROM employees AS e,departments AS d
WHERE e.department_id = d.department_id;
案例2 查询部门编号>100的部门名和所在城市名
SELECT d.department_name,l.city
FROM departments d,locations l
WHERE d.location_id=l.location_id AND d.department_id>100;
案例3 查询有奖金的员工名,部门名
SELECT last_name,department_name
FROM employees e,departments d
WHERE commission_pct IS NOT NULL AND e.department_id =d.department_id;
案例4 查询城市名中第二个字符为o的部门名和城市名
SELECT department_name,city
FROM departments d,locations l
WHERE city LIKE '_o%' AND d.location_id=l.location_id;
案例5 查询每个城市的部门个数
SELECT COUNT(department_id),l.city
FROM departments d,locations l
WHERE d.location_id=l.location_id
GROUP BY d.location_id;
案例6 查询有奖金的每个部门的部门名,部门的领导编号,该部门的最低工资
SELECT d.department_name,e.manager_id,MIN(salary)
FROM employees e,departments d
WHERE e.department_id=d.department_id AND commission_pct IS NOT NULL
GROUP BY e.department_id
案例7 查询部门中员工个数>10的部门名
SELECT d.department_name,COUNT(employee_id)
FROM departments d,employees e
WHERE d.department_id=e.department_id
GROUP BY e.department_id
HAVING COUNT(employee_id)>10;
案例8 查询哪个部门的员工个数>5,并按员工个数降序
SELECT department_name,COUNT(*)
FROM departments d,employees e
WHERE d.department_id=e.department_id
GROUP BY d.department_id
HAVING COUNT(*)>5
ORDER BY COUNT(*) DESC;
案例9 查询员工名,部门名和所在城市
SELECT last_name,department_name,city
FROM employees e,departments d,locations l
WHERE e.department_id = d.department_id AND d.location_id=l.location_id;
2 非等值连接
需要创建一个工资等级表,创建表和插入数据的sql语句:
USE myemployees;
DROP TABLE IF EXISTS sal_grade;
CREATE TABLE sal_grade (
id INT PRIMARY KEY AUTO_INCREMENT,
min_salary DOUBLE ,
max_salary DOUBLE,
grade CHAR
);
INSERT INTO sal_grade VALUES(NULL,2000,3999,'A');
INSERT INTO sal_grade VALUES(NULL,4000,5999,'B');
INSERT INTO sal_grade VALUES(NULL,6000,9999,'C');
INSERT INTO sal_grade VALUES(NULL,10000,12999,'D');
INSERT INTO sal_grade VALUES(NULL,13000,14999,'E');
INSERT INTO sal_grade VALUES(NULL,15000,99999,'F');
案例1 查询员工的姓名,工资和工资级别
SELECT last_name,e.salary,g.grade
FROM employees e,sal_grade g
WHERE e.salary BETWEEN min_salary AND max_salary;
3 自连接
案例1 查询员工名和上级的名称
SELECT e1.last_name,e2.last_name
FROM employees e1,employees e2
WHERE e1.manager_id=e2.employee_id;
SQL99语法
内连接:
语法:
SELECT 查询列表 FROM 表名1 别名
[INNER] JOIN 表名2 别名
ON 连接条件
WHERE 筛选条件
GROUP BY 分组列表
HAVING 分组后筛选
ORDER BY 排序列表;
sql92和sql99的区别
sql99使用了 JOIN 关键字代替了之前的逗号,并将连接条件和筛选条件进行分离,提高可读性。
1 等值连接
案例1 查询员工名和部门名
SELECT last_name,department_name
FROM employees e JOIN departments d
ON e.department_id = d.department_id;
案例2 查询部门编号>100的部门名和所在的城市名
SELECT d.department_name,l.city
FROM departments d JOIN locations l
ON d.location_id=l.location_id
WHERE d.department_id>100;
案例3 查询每个城市的部门个数
SELECT COUNT(department_id),l.city
FROM departments d JOIN locations l
ON d.location_id=l.location_id
GROUP BY d.location_id;
案例4 查询部门中员工个数>10的部门名,并按员工个数降序
SELECT d.department_name,COUNT(employee_id)
FROM departments d JOIN employees e
ON d.department_id=e.department_id
GROUP BY e.department_id
HAVING COUNT(employee_id)>10
ORDER BY COUNT(employee_id) DESC;
2 非等值连接
案例 查询部门编号在10-90之间的员工的各个工资级别的个数
SELECT COUNT(*),grade
FROM employees e JOIN sal_grade
ON salary BETWEEN min_salary AND max_salary
WHERE department_id BETWEEN 10 AND 90
GROUP BY grade;
3 自连接
案例 查询员工名和对应的领导名
SELECT e1.last_name,e2.last_name
FROM employees e1 JOIN employees e2
ON e1.manager_id=e2.employee_id;
测试题
一、查询员工姓名、入职日期并按入职日期升序
SELECT last_name,hiredate FROM employees ORDER BY hiredate;
二、将当前日期显示成 xxxx年xx月xx日
SELECT DATE_FORMAT(NOW(),'%Y年%m月%d日');
三、
已知学员信息表stuinfo
stuId
stuName
gender
majorId
已知专业表major
id
majorName
已知成绩表result
id成绩编号
majorid
stuid
score
1、查询所有男生的姓名、专业名和成绩,使用SQL92和SQL99两种语法方式实现
sql92:
SELECT stuName,majorName,score
FROM stuinfo s,major m,result r
WHERE s.majorId=m.id AND m.id=r.majorId AND s.gender='男';
sql99:
SELECT stuName,majorName,score
FROM stuinfo s JOIN major m
ON s.majorId=m.id
JOIN result r ON m.id=r.majorId
WHERE s.gender='男';
2、查询每个性别的每个专业的平均成绩,并按平均成绩降序
SELECT gender,majorName,AVG(score)
FROM stuinfo s JOIN major m ON s.majorId=id
JOIN result r ON m.id=r.majorid
GROUP BY s.gender,m.id
ORDER BY AVG(score) DESC;
外连接:
说明: 查询结果为主表中所有记录,如果从表有匹配项则显示,如果从表没有匹配项则显示null。
应用场景:一般用于查询主表中有但从表中没有的记录。
特点:
- 外连接分主从表,两表的顺序不能任意调换
- 左连接的话,左边为主表。右连接的话,右边为主表。
语法:
SELECT 查询列表 FROM 表1 别名
LEFT/RIGHT [OUTER]JOIN 表2 别名
ON 连接条件 WHERE 筛选条件
案例1 查询所有女神记录以及对应男朋友名,如果没有显示null
SELECT b.*,bo.boyName
FROM beauty b LEFT JOIN boys bo
ON b.boyfriend_id=bo.id;
案例2 查询哪个女神没有男朋友
SELECT b.*,bo.boyName
FROM beauty b LEFT JOIN boys bo
ON b.boyfriend_id=bo.id
WHERE bo.id IS NULL;
案例3 查询哪个部门没有员工,并显示其部门编号和部门名
SELECT d.department_id,d.department_name
FROM departments d LEFT JOIN employees e
ON d.department_id=e.department_id
WHERE e.employee_id IS NULL;
测试题
1 查询编号>3的女神的男朋友信息,如果没有用null填充
SELECT b.id,bo.*
FROM beauty b LEFT JOIN boys bo
ON b.boyfriend_id=bo.id
WHERE b.id>3;
2 查询哪个城市没有部门
SELECT city
FROM locations l LEFT JOIN departments d
ON l.location_id=d.location_id
WHERE d.department_id IS NULL;
3 查询部门名为SAL或IT的员工信息
SELECT e.*
FROM employees e RIGHT JOIN departments d
ON e.department_id=d.department_id
WHERE d.department_name IN ('SAL','IT');
总结join连接
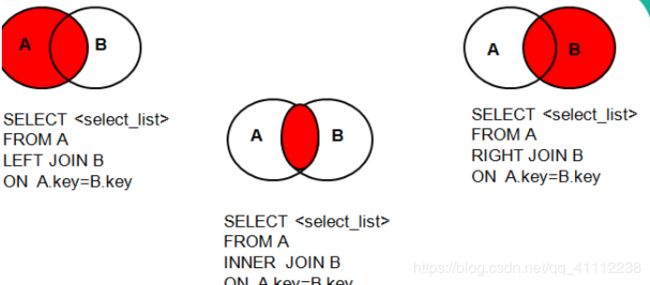
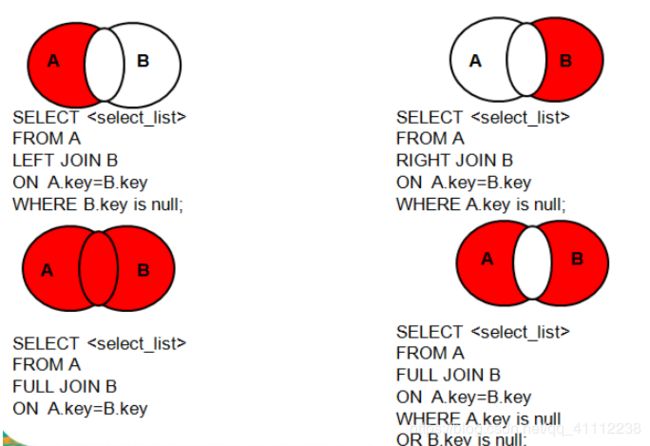
8 子查询
说明:
当一个查询语句中又嵌套了另一个完整的select语句,则被嵌套的select语句称为子查询或内查询,外面的select语句称为主查询或外查询。
分类:
①select后面 要求子查询的结果为单行单列(标量子查询)
②from后面 子查询的结果可以为多行多列(表子查询)
③where或having后面 子查询的结果必须为单列
④exists后面 要求子查询结果必须为单列(相关子查询)
特点:
①子查询放在条件中,一般放在条件的右侧
②子查询一般放在小括号中
③子查询的执行优先于主查询
④单行子查询对应单行操作符 > < >= <= = <>
⑤多行子查询对应多行操作符 any in some all
1 单行子查询
案例1 查询和Zlotky相同部门的员工姓名和工资
SELECT
last_name,salary
FROM
employees
WHERE department_id =
(SELECT
department_id
FROM
employees
WHERE last_name = 'Zlotkey');
案例2 查询工资比公司平均工资高的员工的员工号,姓名和工资
SELECT
employee_id,
last_name,
salary
FROM
employees
WHERE salary >
(SELECT
AVG(salary)
FROM
employees) ;
案例3 查询工资最高的员工的姓名,要求first_name和last_name显示为一列,列名为姓名
SELECT CONCAT(first_name,' ',last_name) AS '姓名' FROM employees
WHERE salary = (SELECT MAX(salary) FROM employees);
2 多行子查询
IN 判断某字段是否在指定列表内
ANY / SOME 判断某字段的值是否满足其中任意一个
ALL 判断某字段的值是否满足所有的
案例1 返回location_id是1400或1700的部门中的所有员工姓名
SELECT
last_name
FROM
employees
WHERE department_id IN
(SELECT DISTINCT
department_id
FROM
departments
WHERE location_id IN (1400, 1700));
案例2 返回其他部门中比job_id为’IT_PROG’部门任一工资低的员工的员工号、姓名、job_id和salary
SELECT employee_id,last_name,salary,job_id
FROM employees
WHERE salary< ANY(SELECT DISTINCT salary FROM employees WHERE job_id = 'IT_PROG')
AND job_id <> 'IT_PROG';
案例3 返回其他部门中比job_id为’IT_PROG’部门所有工资都低的员工的员工号、姓名、job_id和salary
SELECT employee_id,last_name,salary,job_id
FROM employees
WHERE salary< ALL(SELECT DISTINCT salary FROM employees WHERE job_id = 'IT_PROG')
AND job_id <> 'IT_PROG';
案例4 查询在部门的location_id为1700的部门的员工的员工号
SELECT employee_id FROM employees
WHERE department_id IN
(SELECT DISTINCT department_id FROM departments d
JOIN locations l ON d.location_id=l.location_id
WHERE l.location_id =1700);
3 标量子查询
案例 查询部门编号是50的员工个数
SELECT (SELECT COUNT(*) FROM employees WHERE department_id =50);
4 表子查询
案例 查询每个部门的平均工资的工资级别
SELECT s.sal,g.grade
FROM sal_grade g
JOIN (SELECT AVG(salary) AS sal FROM employees GROUP BY department_id) s
ON s.sal BETWEEN g.min_salary AND g.max_salary;
5 放在exists后面
案例 查询有无名字为’abc’的员工信息
SELECT EXISTS(SELECT * FROM employees WHERE last_name = 'abc');//0,存在为1
子查询习题及答案
题1 查询各部门中工资比本部门平均工资高的员工的员工号、姓名和工资
SELECT employee_id,last_name,salary
FROM employees e1
JOIN
(SELECT AVG(salary) avg_sal,department_id did
FROM employees
GROUP BY department_id) e2
ON e1.department_id = e2.did
WHERE e1.salary > e2.avg_sal ;
题2 查询和姓名中包含字母u的员工的在相同部门的员工号和姓名
SELECT employee_id,last_name
FROM employees
WHERE department_id IN
(SELECT DISTINCT department_id
FROM employees
WHERE last_name LIKE '%u%');
题3 查询管理者是K_ing的员工姓名和工资
SELECT last_name,salary
FROM employees
WHERE manager_id IN
(SELECT employee_id FROM employees WHERE last_name ='K_ing');
子查询经典题目及答案
1 查询工资最低的员工信息: last_name, salary
SELECT last_name,salary FROM employees
WHERE salary = (SELECT MIN(salary) FROM employees);
2 查询平均工资最低的部门信息
SELECT * FROM departments
WHERE department_id =
(SELECT department_id
FROM employees
GROUP BY department_id
ORDER BY AVG(salary)
LIMIT 1);
3 查询平均工资最低的部门信息和该部门的平均工资
SELECT d.*,temp_table.asl
FROM departments d
JOIN
(SELECT department_id AS did,AVG(salary) AS asl
FROM employees
GROUP BY department_id
ORDER BY asl
LIMIT 1) temp_table
ON d.department_id = temp_table.did;
4 查询平均工资最高的 job 信息
SELECT j.*
FROM jobs j
JOIN employees e
ON e.job_id=j.job_id
WHERE e.salary=
(SELECT AVG(salary)
FROM employees
GROUP BY job_id
ORDER BY AVG(salary) DESC
LIMIT 1);
5 查询平均工资高于公司平均工资的部门有哪些?
SELECT t1.did,t1.asl FROM
(SELECT AVG(salary) asl,department_id did FROM employees e GROUP BY department_id) t1,
(SELECT AVG(salary) asl FROM employees) t2
WHERE t1.asl>t2.asl;
6 查询出公司中所有 manager 的详细信息.
SELECT * FROM employees
WHERE employee_id IN
(SELECT DISTINCT manager_id FROM employees);
7 各个部门中,最高工资中最低的那个部门的最低工资是多少
SELECT MIN(salary) FROM employees
WHERE department_id =
(SELECT department_id,MAX(salary)
FROM employees GROUP BY department_id
ORDER BY MAX(salary) LIMIT 1);
8 查询平均工资最高的部门的 manager 的详细信息: last_name, department_id, email, salary
SELECT e.* FROM employees e
JOIN
(SELECT department_id FROM employees GROUP BY department_id ORDER BY AVG(salary) DESC LIMIT 1) t
ON e.department_id = t.department_id
WHERE e.employee_id IN
(SELECT DISTINCT manager_id FROM employees WHERE department_id = t.department_id);
9 分页查询
应用场景:
当页面上的数据一页显示不全,需要分页显示时
分页查询的sql命令请求数据库服务器->服务器响应到多条数据->前台页面
语法:
SELECT 查询列表 FROM 表名 WHERE 筛选条件
GROUP BY 分组条件 HAVING 分组后筛选
ORDER BY 排序列表
LIMIT 起始索引,显示的条目数
执行顺序:
FROM->WHERE->GROUP BY ->HAVING->SELECT->ORDER BY->LIMIT
特点:
① 起始索引从0开始,不写默认从0开始
② 要显示的是第p页,每页显示s条
则limit后参数为(p-1)*s,s
案例1 查询员工信息表的前5行
SELECT * FROM employees LIMIT 0,5;
SELECT * FROM employees LIMIT 5;
案例2 查询有奖金的且工资较高的11-20名
SELECT * FROM employees WHERE commission_pct IS NOT NULL
ORDER BY salary DESC LIMIT 10,10;
10 联合查询
说明:
当查询结果来自多张表,但多张表之间没有关联时,常使用联合查询
语法:
SELECT 查询列表 FROM 表1 WHERE 筛选条件...
UNION
SELECT 查询列表 FROM 表2 WHERE 筛选条件...
特点:
1 多条待联合的查询语句的查询列数必须一致,查询类型和字段意义最好一致
2 UNION 自动去重 UNION ALL 不去重,支持重复项
案例1 查询所有国家年龄大于20岁的用户信息
SELECT * FROM china WHERE age>20
UNION
SELECT * FROM usa WHERE uage>20;
案例2 查询所有国家的用户姓名和年龄
SELECT NAME,age FROM china
UNION
SELECT uname,uage FROM usa;
DDL
Data Define Language 数据定义语言,用于对数据库和表的管理和操作
库的管理
1 创建数据库
CREATE DATABASE [IF NOT EXISTS] 数据库名;
2 删除数据库
DROP DATABASE IF EXISTS 数据库名;
3 修改数据库名
打开对应数据库文件夹选择重命名,并重启MySQL服务
表的管理
1 创建表
语法:
CREATE TABLE [IF NOT EXISTS]表名(
字段名 字段类型 [字段约束],
...
字段名 字段类型 [字段约束]
);
案例1 创建没有约束的学生信息表
CREATE TABLE stuinfo(
id INT,
NAME VARCHAR(20),
sex CHAR,
birtday DATETIME
);
常见的数据类型:
TINYINT/SMALLINT/INT/BIGINT
整形 int最常用DOUBLE/FLOAT(m,n)
浮点型,m,n可选例如 DOUBLE(5,2)代表最多5位,其中必须有2位小数,即最大值999.99DECIMAL(m,n)
高精度浮点型,一般用在金融方面数据CHAR(n)
固定长度字符串类型,n可省略,默认1,不管实际存储都是开辟n个字符空间,空间换时间VARCHAR(n)
可变长度字符串类型,n不可省略,根据实际存储决定开辟的空间,时间换空间TEXT
字符串类型,表示存储较长文本BLOB
字节类型/二进制类型DATE
日期类型 yyyy-MM-ddTIME
时间类型 hh:mm:ssTIMESTAMP/DATETIME
时间戳类型,日期+时间
datetime,保存范围交大从1900-1-1开始,占字节8
timestamp,保存范围较小,从1970-1-1~2038-12-31,占字节4
常见的约束
说明:
用于限制表中字段数据的,用于保证数据表中的数据是一致的、准确的、可靠的
NOT NULL
非空,限制字段为必选项DEFAULT
默认,用于给没有插入值的字段赋初值PRIMARY KEY
主键,限制字段的值不可重复,该字段默认不能为空,只能有一个主键,但可由多个字段组成UNIQUE
唯一,限制该字段不能重复,可以为空,可以有多个唯一约束CHECK
检查,限制该字段的值必须满足指定条件,MySQL不支持 CHECK 约束FOREIGN KEY
外键,限制两个表的关系,要求外键列的值必须来自主表的关联列
要求:
①主表的关联列必须是主键
②主表的关联列和从表的关联列的类型必须一致,意思一样,名称无要求
③要求在从表设置外键关系
④要求插入数据时,先插入主表,再插入从表,删除数据时,先删除从表,再删除主表。
分类:
表级约束:PRIMARY KEY,UNIQUE,FOREIGN KEY
列级约束:NOT NULL,DEFAULT,UNIQUE,PRIMARY KEY,CHECK
表级约束例:
CREATE TABLE students(
id INT,
NAME VARCHAR(10),
majorId INT,
CONSTRAINT pk PRIMARY KEY(id),
CONSTRAINT uq UNIQUE(NAME),
CONSTRAINT fk FOREIGN KEY(majorId) REFERENCES major(id)
);
案例2 创建有约束的学生信息表
CREATE TABLE stuinfo(
id INT PRIMARY KEY,#主键约束
NAME VARCHAR(20) UNIQUE,#唯一约束
sex CHAR DEFAULT '男',#默认约束
birthday DATETIME NOT NULL#非空约束
major_id INT,
CONSTRAINT fk FOREIGN KEY major_id REFERENCES major(id)
#外键格式 在最后添加 constraint 外键名 foreign key 从表关联列名 references 主表名(主表主键关联列)
);
2 修改表
语法:
ALTER TABLE 表名 ADD/MODIFY/CHANGE/DROP COLUMN 字段名 字段类型 [字段约束]
案例1 修改表名
ALTER TABLE stuinfo RENAME TO stu;
案例2 添加字段
ALTER TABLE stuinfo ADD COLUMN age INT NOT NULL;
案例3 修改字段名
ALTER TABLE stuinfo CHANGE COLUMN sex gender CHAR DEFAULT '男'
案例4 修改字段类型
ALTER TABLE stuinfo MODIFY COLUMN birthday TIMESTAMP;
案例5 删除字段
ALTER TABLE stuinfo DROP COLUMN birthday;
3 删除表
语法:
DROP TABLE IF EXISTS 表名;
4 复制表
语法:
CREATE TABLE 新表名 LIKE 旧表名; #仅复制表结构
CREATE TABLE 新表名 SELECT * FROM 旧表名;#复制表结构和数据
案例 复制员工表的姓名,部门编号,工资字段到新表emp,但不复制数据
CREATE TABLE emp SELECT last_name,department_id,salary FROM employees WHERE 1=0;
综合测试及答案
1.使用分页查询实现,查询员工信息表中部门为50号的工资最低的5名员工信息
SELECT * FROM employees WHERE department_id =50 ORDER BY salary ASC LIMIT 0,5;
2.使用子查询实现城市为Toronto的,且工资>10000的员工姓名
SELECT last_name FROM employees
WHERE salary>10000 AND department_id IN
(SELECT department_id FROM departments d,locations l
WHERE d.location_id=l.location_id AND city = 'Toronto')
3.创建表qqinfo,里面包含qqid,添加主键约束、昵称nickname,添加唯一约束、邮箱email(添加非空约束)、性别gender
CREATE TABLE qqinfo(
qqid INT PRIMARY KEY,
nickname VARCHAR(20) UNIQUE,
email VARCHAR(20) NOT NULL,
sex CHAR
);
4.删除表qqinfo
DROP TABLE IF EXISTS qqinfo;
5.试写出sql查询语句的定义顺序和执行顺序
定义顺序:
SELECT->FROM->JOIN ON->WHERE->GROUP BY->HAVING->ORDER BY->LIMIT
执行顺序:
FROM->JOIN ON->WHERE->GROUP BY->HAVING->SELECT->ORDER BY->LIMIT
DML
Data Manipulation Language 数据操作语言,主要用于对数据的增删改
插入
语法:
INSERT INTO 表名(字段名1,字段名2...) VALUES(值1,值2...);
INSERT INTO 表名(字段名1,字段名2...) VALUES(值1,值2...),(值1,值2...)...(值1,值2...);
特点:
1 字段和值列表一一对应,包含类型、约束等必须匹配
2 数值型的值不用单引号,非数值型的值需要使用单引号
3 字段顺序无要求
例1:字段和值列表一一对应
INSERT INTO stuinfo(id,stuName,gender,seat,age,majorId) VALUES(3,'宁缺','男',3,20,1);
例2:可以为 NULL 的字段可以插入 NULL,或不写
INSERT INTO stuinfo(id,stuName,gender,seat,age,majorId) VALUES(4,'桑桑',NULL,NULL,NULL,NULL);
INSERT INTO stuinfo(id,stuName) VALUES(4,'桑桑');
例3:默认字段的插入插入 DEFAULT,或不写
INSERT INTO stuinfo(id,stuName,age) VALUES(4,'桑桑',DEFAULT);
INSERT INTO stuinfo(id,stuName) VALUES(4,'桑桑');
例4:插入所有字段 可省略字段名
INSERT INTO stuinfo VALUES(3,'宁缺','男',3,20,1);
例5:插入自增长字段
INSERT INTO stuinfo(stuName) VALUES('范闲');
补充:设置自增长字段
创建表时在字段后追加 AUTO_INCREMENT,必须搭配 PRIMARY KEY 或 UNIQUE,类型为数值型,一个表只能有一个自增长列。例:
CREATE TABLE t(id INT PRIMARY KEY AUTO_INCREMENT);
更新数据
语法:
UPDATE 表名 SET 字段名1=值1,字段名2=值2...
WHERE 筛选条件;
例:修改年龄小于20的学生的专业编号为3,且座位号更改为5
UPDATE students SET majorId=3,seat=5 WHERE age<20;
删除数据
方式1
语法:
DELETE FROM 表名 WHERE 筛选条件;
案例:删除姓李的所有信息
DELETE FROM students WHERE stuName LIKE '李%';
方式2
语法:
TRUNCATE TABLE 表名;
案例:删除表中所有数据
TRUNCATE TABLE students;
DELETE 和 TRUNCATE 的区别:
① DELETE 可以添加 WHERE 条件,TRUNCATE 不能,直接删除所有数据
② TRUNCATE 的效率较高,不需要逐行判断
③ 如果删除带自增长列的表,使用 DELETE 删除,插入数据后,记录从断点处开始,如果使用 TRUNCATE 则从1开始
④ DELETE 删除数据返回受影响的函数,TRUNCATE 不返回
⑤ DELETE 删除数据支持事务回滚,TRUNCATE 不支持
事务
什么是事务?
一个事务是由一条或多条sql语句构成,这一条或者多条sql语句要么全部执行成功,要么全部执行失败。
默认情况下,每条单独的sql语句就是一个单独的事务。
例:银行转账,A要向B转账1000元,这需要两条sql语句:
①A的账户减去1000元 ②B的账户加上1000元。
设想如果在第一条sql语句执行成功后,在执行第二条sql语句之前程序被中断了,那么B的账户没有增加而A的账户却减少了1000,这肯定不是我们想要的结果。
因此我们需要事务来解决此类问题。
事务的特性ACID
原子性 atomicity
事务中所有操作是不可分割的原子单位,事务中的所有操作要么全部执行成功,要么全部执行失败。
一致性 consistency
事务执行后,数据库状态与其他业务规则保持一致。如转账案例中,无论事务成功与否,参与转账的两个账户的金额之和应保持不变。
隔离性 isolation
在并发操作中,不同事务之间是互相隔离的,不会互相干扰。
持久性 durability
一旦事务提交成功,事务中所有的数据都必须被持久化到数据库中,即使提交数据后数据库崩溃,在数据库重启时,也必须保证通过某种机制恢复数据。
MySQL中的事务
1 隐式事务
没有明显的开始和结束标记
例如DML语句的 INSERT,UPDATE,DELETE 语句本身就是一条事务
2 显式事务
具有明显的开始和结束标记
一般由多条sql语句组成,必须具有明显的开始和结束标记
步骤:
①取消事务的自动提交
②开启事务
③编写sql语句
④结束事务
转账案例
SET autocommit = 0;
START TRANSACTION;
UPDATE account SET money=money-1000 WHERE NAME = 'A';
UPDATE account SET money=money+1000 WHERE NAME = 'B';
COMMIT;
隔离级别
脏读:
对于两个事务T1和T2,T1读取了已被T2 更新但还没有提交 的字段,之后若T2回滚,T1读取的内容是临时且无效的。
比如事务B执行过程中修改了数据D,在未提交前事务A读取了D,而事务B却回滚了,这样事务A就形成了脏读,也就是说,当前事务读到的数据是别的事务想要修改但是没有修改成功的数据。
不可重复读:
T1读取了一个字段,T2 更新该字段并提交 ,T1再次读取同一字段,值不同。
比如事务A首先读取了一条数据,然后执行逻辑的时候,事务B将这条数据改变了,然后事务A再次读取的时候,发现数据不匹配了,就是所谓的不可重复读。
也就是说,当前事务先进行了一次数据读取,然后再次读取到的数据是别的事务修改成功的数据,导致两次读取到的数据不匹配。
幻读:
T1读取了一个字段,T2在该表中插入了一些新行,之后T1再读取同一个表会多出几行。
比如事务A首先根据条件索引得到N条数据,然后事务B改变了这N条数据之外的M条或者增添了M条符合事务A搜索条件的数据,导致事务A再次搜索发现有N+M条数据了,就产生了幻读。也就是说,当前事务读第一次取到的数据比后来读取到数据条目少。
MySQL支持四个隔离级别
- 读未提交(存在脏读、不可重复读、幻读)
- 读已提交(解决脏读,存在不可重复读和幻读)
- 可重复读(默认,解决脏读,不可重复读,存在幻读)
- 可串行化(解决所有并发问题,但效率较低)