
引言
今天躺在床上刷抖音的时候,正好刷到「基地边缘」的有关 SpaceX 的科普视频,忽然我就想,这个视频我能怎么把它搞下来呢?
分析
在抖音上点击分享的时候可以有下载的选项,但是这个就下载到手机上了,我想把这种科普视频保存起来,下到手机上以后还得通过各种方式导到电脑上,这就很不方便了。
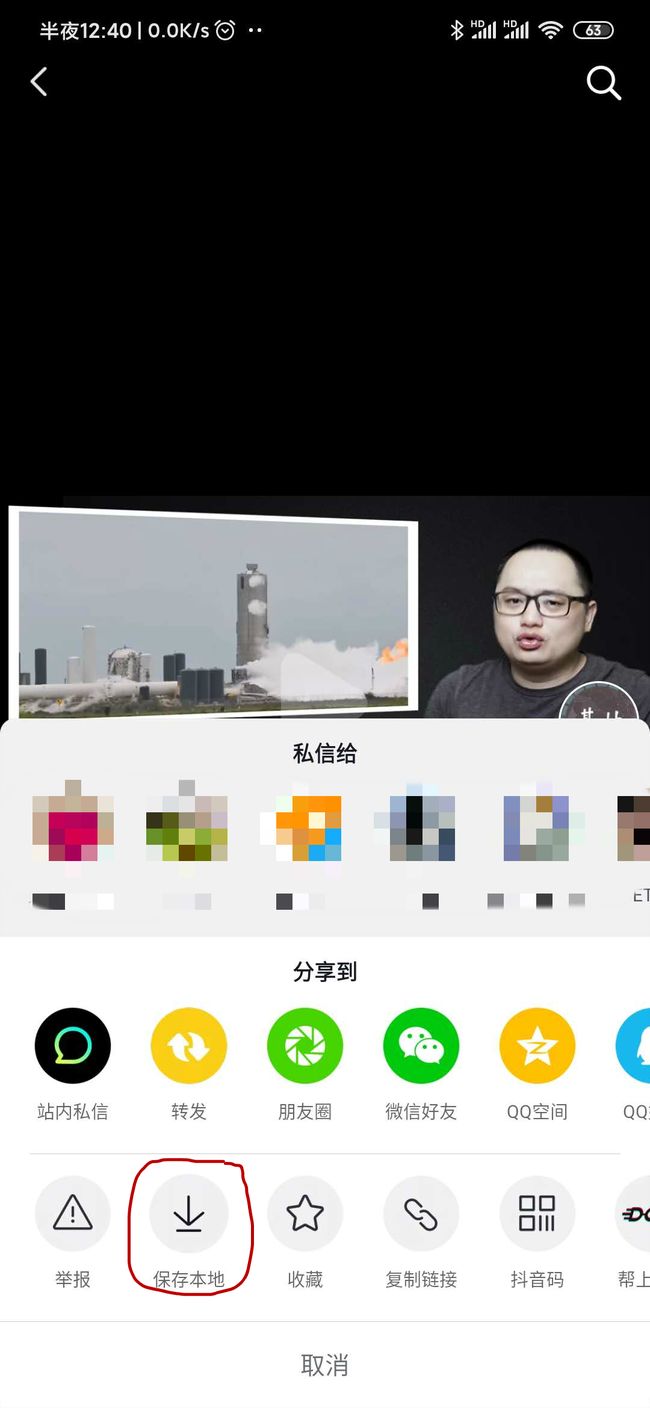
不过还好抖音提供了「复制链接」的功能,先把这个链接复制下来,在浏览器上打开手机模拟,看看能不能打开这个链接。
这里我拿到的链接如下:
https://v.douyin.com/JefvNdx/
在浏览器上输入这个链接以后,可以看到页面进行了一次跳转,刚才的短连接也变成了另一个长链接(这里其实是通过 302 进行了重定向):
https://www.iesdouyin.com/share/video/6834090710124236043/?region=CN&mid=6834090817913670407&u_code=15afkgm1a&titleType=title&utm_source=copy_link&utm_campaign=client_share&utm_medium=android&app=aweme

页面变成这样了,我抱着试试看的心态,点击了一下播放,竟然还能播放,抖音真的是良心啊,我还以为会直接跳转到 APP 下载页面,视频能播放出来,基本上想把这个视频爬下来这件事儿就已经成功了一半了。
还是老方法,打开 Chrome 的 F12 ,进入 network 标签,点击一下播放,看看能不能拿到视频源的地址。
结果在我刷新页面的时候,直接发现了一个请求,这个请求可就 NB 了,直接返回这个视频的所有信息。
请求连接如下:
https://www.iesdouyin.com/web/api/v2/aweme/iteminfo/?item_ids=6834090710124236043&dytk=8667a137523322dcea2304b86a7570cd9e707167df185ed8bdda723dc84d5477
这个地址其实后面的参数穿不穿都没有影响,这里的 item_ids 应该就是这个视频的 id ,和上面那个链接里面直接更在 video 后面的 id 是一致的。

返回的 json 数据我就不贴了,太长了,反正我在这个数据里面找到了视频源的信息:
https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f7b0000brbp0h64tqbtfrkkjqlg&ratio=720p&line=0

这个链接 Copy 出来,在浏览器中直接输入后,成功播放了当前的视频:
眼神好的同学估计已经发现了浏览器地址中的变化,这个地址并不是我们刚才 Copy 出来的地址,这是啥情况呢?
接着打开 F12 看 network :

可以看到,我们原始的访问链接被 302 重定向到了下面这个地址:
http://v26-dy.ixigua.com/f2a61958ae617965d3d42815b13b516e/5eda87f9/video/tos/cn/tos-cn-ve-15/23a5f6a323584ae69b04a65d5ca289b7/?a=1128&br=3213&bt=1071&cr=0&cs=0&dr=0&ds=3&er=&l=20200606005756010019017107165572F4&lr=aweme_search_suffix&mime_type=video_mp4&qs=0&rc=anRudXd0N2tzdTMzZWkzM0ApOTg5ODw5ZDtnNzg4OWQ4O2dpZ2hjX3EzLV9fLS00LS9zcy1fLzIzMmM2YS02MjQtNC46Yw%3D%3D&vl=&vr=
本来我以为是需要访问重定向后的链接才能下载视频,后面实际上测试的结果是使用之前的链接就可以。
编码
到这里,我们就可以开始写代码了,完整代码如下:
import requests
import re
# 创建一个请求头
headers = {
'user-agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1',
}
# 分享路径
share_url = "https://v.douyin.com/JefvNdx/"
session = requests.Session()
res = session.get(share_url, headers = headers)
# 获取视频 id
item_ids = re.compile(r'itemId: "([0-9]+)"').findall(res.text)[0]
# 拼接请求
item_info_url = f"https://www.iesdouyin.com/web/api/v2/aweme/iteminfo/?item_ids={item_ids}"
res_json = session.get(item_info_url, headers = headers).json()
# 获取视频源路径
vedio_url = res_json['item_list'][0]['video']['play_addr']['url_list'][0]
res = requests.get(vedio_url, headers = headers)
with open('demo.mp4', 'wb') as fb:
fb.write(res.content)
print("视频下载完成~~~")
代码我就不多做解释了,注释已经写得很清楚了。
批量爬取
到这里,问题又来了,我如果想要下载这个人所有的科普视频呢?难道要我一个一个去分享链接么?
这也太傻了,我打开了这个人的主页,在右上角的分享按钮中再次发现了「复制链接」,太好了,抖爸爸又给我们提供接口了。

这次我获取到的链接是:
https://v.douyin.com/Je5WLg6/
闲话少说,接着在 Chrome 中打开分析请求,选择 XHR ,直接看到第一个请求:
https://www.iesdouyin.com/web/api/v2/aweme/post/?sec_uid=MS4wLjABAAAAFTNkHANuPtZKteVQsBaMwaIHoSMh3nxqJDOXEDHUnlg&count=21&max_cursor=0&aid=1128&_signature=fJp6thAXIkOb7YKwZF36KXyaeq&dytk=fd2ba6076e7bb73e31504e51bc4baf08
这个请求的响应里面,再次看到了各个视频的详细信息:

这个 aweme_list 数组里面对应了 20 条视频信息,我看到第一条视频信息里面有一个 aweme_id 的值是 6834090710124236043 ,这和我们上面获取到的那个视频的值完全是一样的嘛。
其实我只需要把 aweme_list 里面的所有的 aweme_id 解析出来,套在前面的程序上,我就可以把这 20 条视频下载回来了(偷个小懒,这部分的代码我就不写了)。
注意,我这里说的是这 20 条视频,那为什么拿不到所有视频?
因为我看到前面那个链接里面有一个参数是 _signature 签名,而这个接口的数据又是分页给出来的,虽然后面有一个 count 意思是返回多少数据,但是我只能得到默认的 20 条数据,更多的数据是没办法获得的,除非分析抖音的前端 JavaScript 代码,找到 _signature 这个签名规则,否则我们是没有办法篡改这个请求的参数的。
示例代码
如果有需要获取源码的同学可以在公众号回复「抖音」进行获取。