京东评论爬虫教程/手册 Python (4步操作 超级简单)
感谢 @biptcszy 本文由该博主的教程和code更新而来 因为做的改动有点多 所以开了新博文
原文地址:https://blog.csdn.net/weixin_42474261/article/details/88354134
原作者github地址:https://github.com/YuleZhang/JDComment_Spider
如有侵权 立刻删除
此文仅是我在原作者的code和教程的帮助下 成功得到自己需要的结果 但过程中有小小曲折 回报大家 传递人间真情!!
操作手册
完整爬虫及存档代码 github链接 https://github.com/rileyatoddler/JDComment_Spider/blob/JD-Web-Scraping-Complete-Code/SpiderScript.py
- 复制粘贴代码到Spyder
- 将想爬的商品SKU粘贴到在代码中productid = [‘SKUID’,‘SKUID’,‘SKUID’,‘SKUID’,‘SKUID’]
- 在文件夹中创建test.csv
- 跑代码,结果会存在test.csv
(得出的结果test.csv直接用excel打开可能会因为有中文字符的问题,中文全部乱码,解决办法是用notepad打开再保存一次,注意检查encoding是UTF-8,得出的结果应该有重复数据,数据清洗可用excel或者参考原作者)
完成
附录:案例操作,相关解释及代码逻辑
案例商品 荣耀v30
https://item.jd.com/100001864325.html
本人使用Anaconda Spyder (Python 3.7)
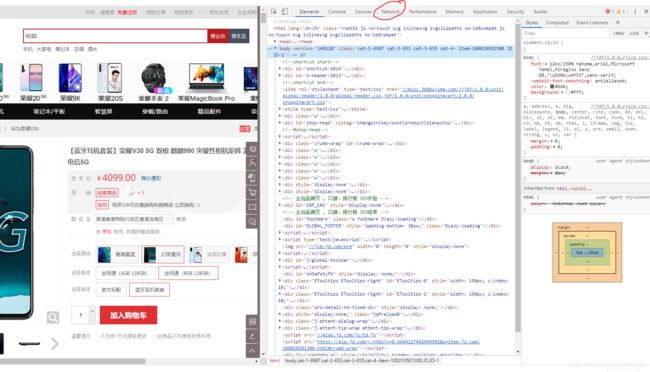
1.打开网站,按"F12"进入网站信息详情页,页面长底下这样
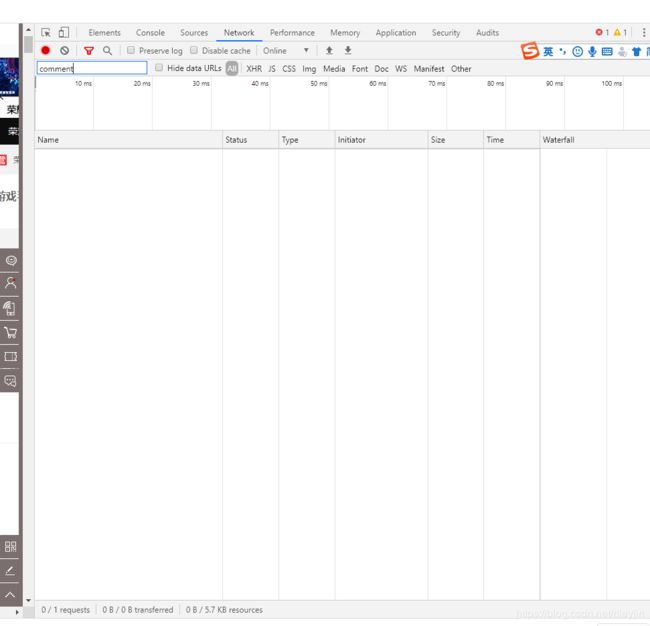
2.单击圈起来的"Network",在搜索栏里输入"comment"
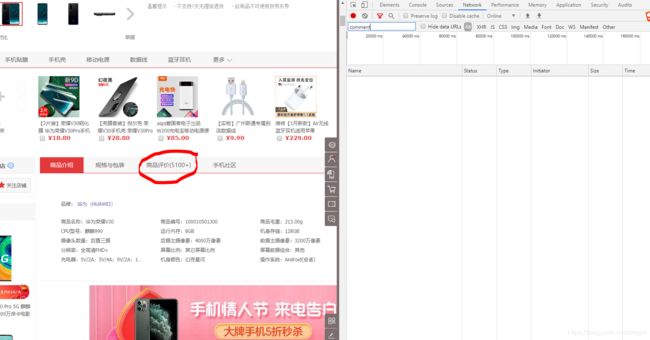
3.在京东商品页面点击"商品评价"
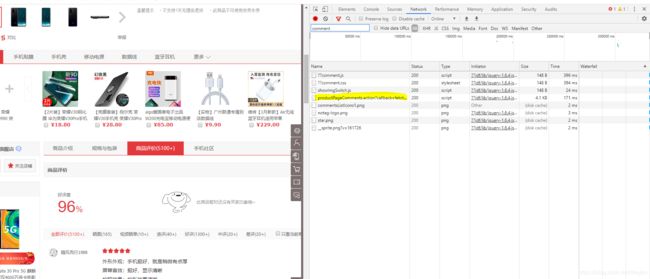
4.右边网页信息详情页(专业术语是什么不知道)就会出现以下response(黄色highlight).(因为network一栏记录的是network的活动,如果已经打开商品评价,可能需要刷新或者重新点一次才可以被记录到)
5.右击>Copy>Copy Link Address
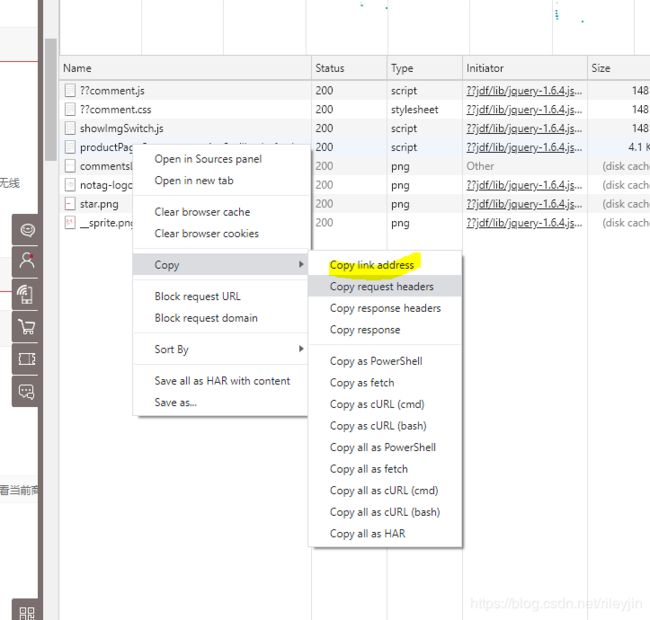
6.复制下来的链接1长这样:
https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv1&productId=100010501300&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1
这个链接中对我们有用的部分的意思是:
- productId=100010501300,具体产品的ID, 即 SKU 是100010501300
(我个人的观察"comment98vv"后面"&productID"前面的数字没用,改成什么数字最后抓取的信息都一样) - score = 0 所有评论 score = 1差评 score = 2 中评 score = 3 好评 score = 5 追评 score = 7 视频晒单
- sortType = 5 推荐排序 sortType = 6时间排序
- page = 0 第1页 京东最多只有100页
(据我的观察) - ShadowSku=0 有些情况ShadowSku可能等于SKU 经过个人测试 数值改成0对结果无影响
7.可以先测试爬取一页评论,测试的code: github 链接:https://github.com/rileyatoddler/JDComment_Spider/blob/JD-Web-Scraping-Complete-Code/test.py
import requests
url = "https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv1&productId=100010501300&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1"
headers = {
'Accept': '*/*',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36',
'Referer':"https://item.jd.com/100000177760.html#comment"}
r = requests.get(url,headers=headers)
print(r.text)
直接复制粘贴以上代码在Spyder然后run,测试其他网页请自行改动第三行url=“link”
8.run的结果长这样
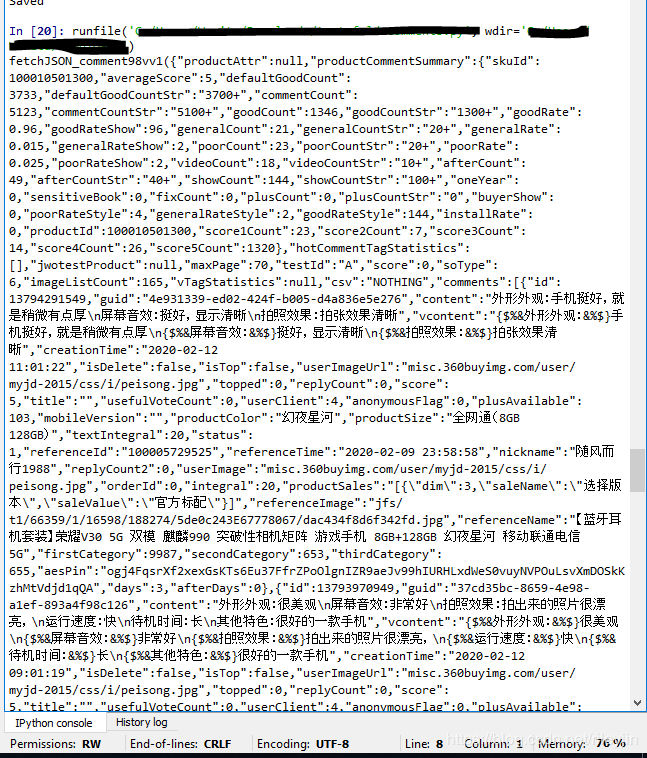
9.复制第一个中括号到最后一个中括号之间的内容,本例子中复制:
{“productAttr”:null,“productCommentSummary”:{“skuId”:100010501300,“averageScore”:5,“defaultGoodCount”:3733," …手机挺好,就是稍微有点厚\n屏幕音效:挺好,显示清晰\n拍照效果:5G",“firstCategory”:9987,“secondCategory”:653,“thirdCategory”:655,“aesPin”:“aSLiVyAQGrVBxsSdb54YWJlZPpYYKhu6EehsX741FUOdOnjHZX_93p06lSwj3DNex9gCJKdLy4LrQZ9x_3H9Fg”,“days”:28,“afterDays”:0}]}
10.粘贴到http://www.bejson.com/jsoneditoronline/ JSON解读器中,点下图中圈起来的小箭头,可得到结果
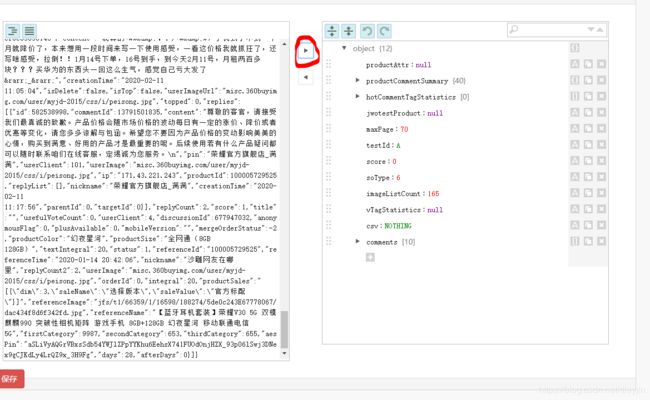
11.解读结果: maxPage:70 共有70页评论 comments[10] 本页有10条评论
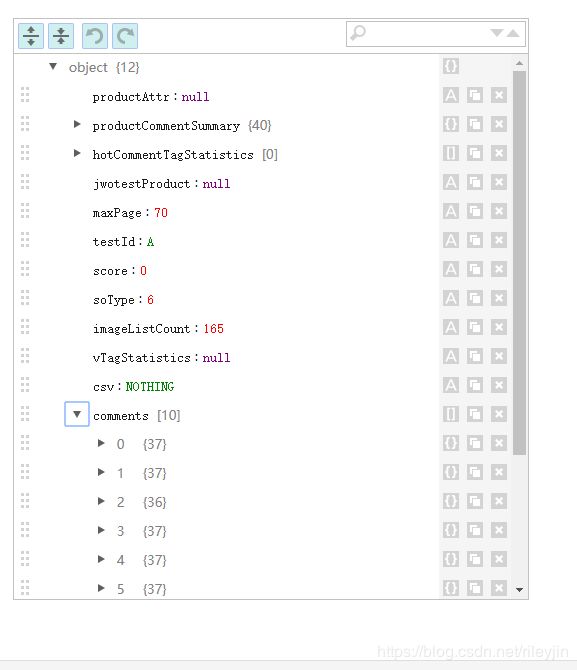
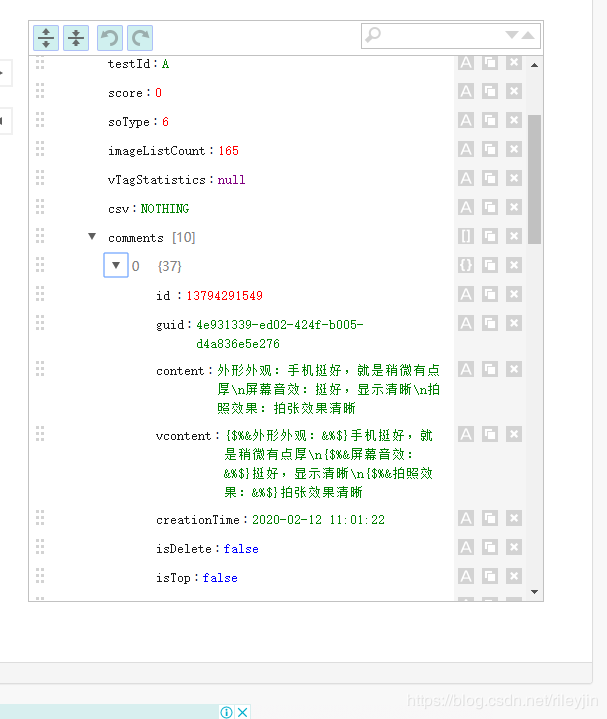
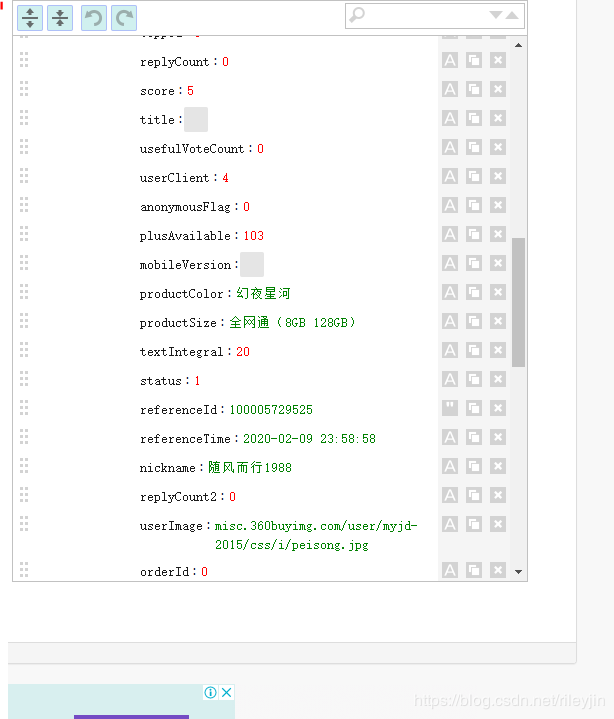
12.点开comments[10]获得评论详情.JSON data有以下有关元素:id(用户id),content(评论内容),creationTime(评价时间),replyCount(回复数),usefulVoteCount(点赞数),productColor(商品颜色),productSize(商品配置),referenceTime(购买时间),nickname(昵称),productSales(包含所选套餐信息)
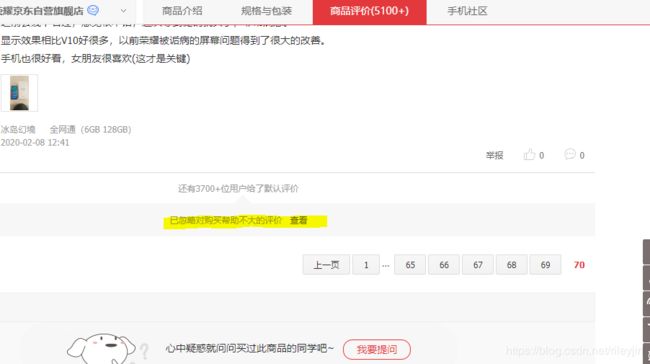
13.是不是成功做到这一步这些已经非常有成就感!(作为小白) 成功就在眼前! 回到原来的产品页面,翻到评论最后一页可以看到京东已忽略部分评价,点击查看.
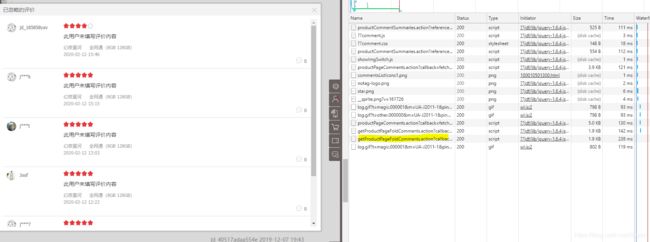
14. 可以看到有右边的网站信息详情多记录了一条response
15.如之前提到的复制链接,得到的链接2如下:
https://club.jd.com/comment/getProductPageFoldComments.action?callback=jQuery3588510&productId=100010501300&score=0&sortType=6&page=0&pageSize=5&_=1581501390602
16.修改链接1:
https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv1&productId=100010501300&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1
将其改为:
https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv1&productId=%s&score=0&sortType=5&page=%s&pageSize=10&isShadowSku=0&fold=1
(SKU改为%s,页面数改为%s,就可以用code把所有的页面和所有的产品爬下来啦!)
修改链接2:
https://club.jd.com/comment/getProductPageFoldComments.action?callback=jQuery3588510&productId=%s&score=0&sortType=6&page=%s&pageSize=5&_=1581501390602
17.完整爬虫及收集code github链接 https://github.com/rileyatoddler/JDComment_Spider/blob/JD-Web-Scraping-Complete-Code/SpiderScript.py
from fake_useragent import UserAgent
from bs4 import BeautifulSoup
import time
import numpy as np
import requests
import json
import csv
import io
def commentSave(list_comment):
file = io.open('test.csv','w',encoding="utf-8", newline = '')
writer = csv.writer(file)
writer.writerow(['ID','Nickname','Bought Time','Comment Time','Like','Reply','Phone Color','Phone Memory','Set','Rating','Content','url'])
for i in range(len(list_comment)):
writer.writerow(list_comment[i])
file.close()
print('Saved')
#get displayed comments
def getCommentData(maxPage):
sig_comment = []
global list_comment
cur_page = 0
while cur_page < maxPage:
cur_page += 1
#in default setting JD displays comments for all product color/types/packages under the same product ID(need to be checked might be case by case)
#under score = 0, all coments with rating from 1 - 5 are displayed
#link for displayed comments
url = 'https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv1&productId=%s&score=0&sortType=6&page=%s&pageSize=10&isShadowSku=0&fold=1'%(proc, cur_page)
try:
response = requests.get(url=url, headers=headers)
time.sleep(np.random.rand()*2)
jsonData = response.text
startLoc = jsonData.find('{')
#print(jsonData[::-1])//字符串逆序
jsonData = jsonData[startLoc:-2]
jsonData = json.loads(jsonData)
pageLen = len(jsonData['comments'])
print('Page Number: %s'%cur_page)
for j in range(0,pageLen):
userId = jsonData['comments'][j]['id']#ID
nickName = jsonData['comments'][j]['nickname']#nickName
boughtTime = jsonData['comments'][j]['referenceTime']#Bought Time
creationTime = jsonData['comments'][j]['creationTime']#Comment Time
voteCount = jsonData['comments'][j]['usefulVoteCount']#Like
replyCount = jsonData['comments'][j]['replyCount']#Reply
phoneColor = jsonData['comments'][j]['productColor']#Phone Color
phoneMemory = jsonData['comments'][j]['productSize']#Phone Color
phoneSet = jsonData['comments'][j]['productSales']#Phone Color
starStep = jsonData['comments'][j]['score']#Rating
content = jsonData['comments'][j]['content']#Content
sig_comment.append(userId) #follow the order of column labels
sig_comment.append(nickName)
sig_comment.append(boughtTime)
sig_comment.append(creationTime)
sig_comment.append(voteCount)
sig_comment.append(replyCount)
sig_comment.append(phoneColor)
sig_comment.append(phoneMemory)
sig_comment.append(phoneSet)
sig_comment.append(starStep)
sig_comment.append(content)
sig_comment.append(url)
list_comment.append(sig_comment)
sig_comment = []
except:
time.sleep(5)
cur_page -= 1
print('Wrong URL/Website not loading/Errors in #try, reconnecting in 5 sec')
return list_comment
#get folded comments
def getFoldCommentData(maxPage):
sig_comment = []
global list_comment
cur_page = 0
while cur_page < maxPage:
cur_page += 1
#in default setting JD displays comments for all product color/types/packages under the same product ID(need to be checked might be case by case)
#under score = 0, all coments with rating from 1 - 5 are displayed
#link for folded comments
url = 'https://club.jd.com/comment/getProductPageFoldComments.action?callback=jQuery2&productId=%s&score=0&sortType=6&page=%s&pageSize=5&_=1581492569799'%(proc,cur_page)
try:
response = requests.get(url=url, headers=headers)
time.sleep(np.random.rand()*2)
jsonData = response.text
startLoc = jsonData.find('{')
#print(jsonData[::-1])//字符串逆序
jsonData = jsonData[startLoc:-2]
jsonData = json.loads(jsonData)
pageLen = len(jsonData['comments'])
print('Page Number: %s'%cur_page)
for j in range(0,pageLen):
userId = jsonData['comments'][j]['id']#ID
nickName = jsonData['comments'][j]['nickname']#nickName
boughtTime = jsonData['comments'][j]['referenceTime']#Bought Time
creationTime = jsonData['comments'][j]['creationTime']#Comment Time
voteCount = jsonData['comments'][j]['usefulVoteCount']#Like
replyCount = jsonData['comments'][j]['replyCount']#Reply
phoneColor = jsonData['comments'][j]['productColor']#Phone Color
phoneMemory = jsonData['comments'][j]['productSize']#Phone Color
phoneSet = jsonData['comments'][j]['productSales']#Phone Color
starStep = jsonData['comments'][j]['score']#Rating
content = jsonData['comments'][j]['content']#Content
sig_comment.append(userId) #follow the order of column labels
sig_comment.append(nickName)
sig_comment.append(boughtTime)
sig_comment.append(creationTime)
sig_comment.append(voteCount)
sig_comment.append(replyCount)
sig_comment.append(phoneColor)
sig_comment.append(phoneMemory)
sig_comment.append(phoneSet)
sig_comment.append(starStep)
sig_comment.append(content)
sig_comment.append(url)
list_comment.append(sig_comment)
sig_comment = []
except:
time.sleep(5)
cur_page -= 1
print('Wrong URL/Website not loading/Errors in #try, reconnecting in 5 sec')
return list_comment
if __name__ == "__main__":
global list_comment
ua=UserAgent()
# headers={"User-Agent":ua.random}
headers = {
'Accept': '*/*',
"User-Agent":ua.random,
'Referer':"https://item.jd.com/100000177760.html#comment"
}
productid = ['100010131982','100005850089','100005850091','100010501298','100010501300']
list_comment = [[]]
sig_comment = []
for proc in productid:
#from page 0 to max page
url1 = 'https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv1&productId=%s&score=0&sortType=6&page=%s&pageSize=10&isShadowSku=0&fold=1'%(proc,0)
print(url1)
response = requests.get(url=url1, headers=headers)
jsonData = response.text
startLoc = jsonData.find('{')
jsonData = jsonData[startLoc:-2]
jsonData = json.loads(jsonData)
print("Total Pages:%s"%jsonData['maxPage'])
getCommentData(jsonData['maxPage'])
url2 = 'https://club.jd.com/comment/getProductPageFoldComments.action?callback=jQuery2&productId=%s&score=0&sortType=6&page=%s&pageSize=5&_=1581492569799'%(proc,0)
print(url2)
response = requests.get(url=url2, headers=headers)
jsonData = response.text
startLoc = jsonData.find('{')
jsonData = jsonData[startLoc:-2]
jsonData = json.loads(jsonData)
print("Total Pages:%s"%jsonData['maxPage'])
getFoldCommentData(jsonData['maxPage'])
#commentSave(list_comment)
print("Done Scraping")
commentSave(list_comment)
18.将改好的链接1和链接2分别粘贴到url1和url的位置,以及链接1粘贴到def getCommentData(maxPage) 底下的url,链接2粘贴到def getFoldCommentData(maxPage) 底下的url,在productid = [‘100010131982’,‘100005850089’,‘100005850091’,‘100010501298’,‘100010501300’]修改自己的产品SKU,提前在路径建立test.csv.
19.得出的结果test.csv直接用excel打开可能会因为有中文字符的问题,中文全部乱码,解决办法是用notepad打开再保存一次,注意检查encoding是UTF-8
20.得出的结果应该有重复数据,数据清洗可用excel或者参考原作者