卷积神经网络CNN权威介绍
**本文更完整的内容请参考极客教程的深度学习专栏:https://geek-docs.com/deep-learning/cnn/cnn-introduce.html,欢迎提出您的宝贵意见。感谢。
在这篇文章中,我们:
- 激发了为什么CNN可能对某些问题更有用,例如图像分类。
- 介绍了MNIST手写数字数据集。
- 了解Conv图层,它将滤镜与图像进行卷积,以产生更有用的输出。
- 谈到Pooling图层,它可以帮助删除除了最有用的特性之外的所有东西。
- 实现了Softmax层,因此我们可以使用交叉熵损失。
在过去的几年里,卷积神经网络(CNN)引起了人们的广泛关注,尤其是因为它彻底改变了计算机视觉领域。在这篇文章中,我们将以神经网络的基本背景知识为基础,探索什么是CNNs,了解它们是如何工作的,并在Python中从头开始构建一个真正的CNNs(仅使用numpy)
卷积神经网络(CNN):全名Convolutional Neural Networks,是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),是深度学习(deep learning)的代表算法之一 。卷积神经网络具有表征学习(representation learning)能力,能够按其阶层结构对输入信息进行平移不变分类(shift-invariant classification),因此也被称为“平移不变人工神经网络(Shift-Invariant Artificial Neural Networks, SIANN)。
这篇文章假设只有神经网络的基本知识。我对神经网络的介绍涵盖了你需要知道的一切,所以你可能想先读一下。
准备好了吗?让我们go。
动机
CNN的经典用例是执行图像分类,例如查看宠物的图像并确定它是猫还是狗。这是一项看似简单的任务 – 为什么不使用普通的神经网络呢?
好问题。
原因1:图像很大
现在用于计算机视觉问题的图像通常是224×224或更大。想象一下,构建一个神经网络来处理224×224彩色图像:包括图像中的3个彩色通道(RGB),得到224×224×3 = 150,528个输入特征!在这样的网络中,一个典型的隐含层可能有1024个节点,因此我们必须为第一层单独训练150,528 x 1024 = 1.5 +亿个权重。我们的网络将是巨大的,几乎不可能训练。
我们也不需要那么多砝码。图像的好处是,我们知道像素在相邻的上下文中最有用。图像中的物体是由小的局部特征组成的,比如眼睛的圆形虹膜或一张纸的方角。第一个隐藏层中的每个节点都要查看每个像素,这不是很浪费时间吗?
原因2:Position可以改变
如果你训练一个网络来检测狗,你希望它能够检测狗,不管它出现在图像的什么地方。想象一下,训练一个网络,它能很好地处理特定的狗的图像,然后给它喂食同一图像的一个稍微移动的版本。狗不会激活相同的神经元,所以网络的反应会完全不同!
我们很快就会看到CNN如何帮助我们缓解这些问题。
数据集
在这篇文章中,我们将解决计算机视觉的“Hello,World!”:MNIST手写数字分类问题。这很简单:给定图像,将其分类为数字。

来自MNIST数据集的样本图像
MNIST数据集中的每个图像都是28×28,包含一个居中的灰度数字。
说实话,一个正常的神经网络实际上可以很好地解决这个问题。您可以将每个图像视为一个28×28 = 784维的向量,将其提供给一个784-dim的输入层,堆叠几个隐藏层,最后输出层包含10个节点,每个数字对应一个节点。
这会起作用,因为MNIST数据集包含居中的小图像,因此我们不会遇到上述大小或移位问题。但是,请记住,在本文的整个过程中,大多数现实世界中的图像分类问题并没有这么简单。
让我们进入CNN吧!
卷积
什么是卷积神经网络?
它们基本上只是使用卷积层的神经网络,也就是Conv层,它基于卷积的数学运算。Conv层由一组过滤器组成,您可以将其看作是数字的二维矩阵。这里有一个例子3×3过滤器:

一个3×3过滤器
我们可以使用一个输入图像和一个滤波器通过将滤波器与输入图像进行卷积来生成一个输出图像。这包括
将过滤器覆盖在图像的某个位置上。
在过滤器中的值与其在图像中的对应值之间执行元素级乘法。
总结所有元素产品。此总和是输出图像中目标像素的输出值。
重复所有位置。
这个4步描述有点抽象,所以让我们举个例子吧。考虑这个微小的4×4灰度图像和这个3×3滤镜:

4×4图像(左)和3×3滤镜(右)
图像中的数字表示像素强度,其中0是黑色,255是白色。我们将对输入图像和过滤器进行卷积以生成2×2输出图像:

2×2输出图像
首先,让我们将滤镜叠加在图片的左上角:

第1步:将滤镜(右)叠加在图像上方(左)
接下来,我们执行重叠图像值和过滤器值之间的元素级乘法。结果如下,从左上角开始,向右,然后向下:

第2步:执行逐元素乘法。
接下来,我们总结所有结果。这很容易:
62 – 33 = 29
最后,我们将结果放在输出图像的目标像素中。由于我们的过滤器覆盖在输入图像的左上角,因此我们的目标像素是输出图像的左上角像素:

我们做同样的事情来生成输出图像的其余部分:

这有用吗?
让我们缩小一下,在更高的层次上看这个。将图像与过滤器进行卷积会做什么?我们可以从我们一直使用的例子3×3过滤器开始,它通常被称为垂直Sobel过滤器:

垂直索贝尔过滤器
以下是垂直Sobel过滤器的示例:
与垂直Sobel过滤器卷积的图像
同样,还有一个水平Sobel过滤器:
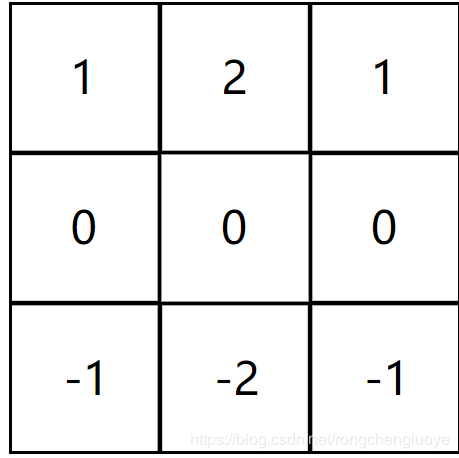
水平Sobel过滤器
与水平Sobel过滤器卷积的图像
看发生了什么?索贝尔过滤器是一种边缘检测器。垂直Sobel过滤器检测垂直边缘,水平Sobel过滤器检测水平边缘。输出图像现在很容易解释:输出图像中的亮像素(高值像素)表示在原始图像中有一个强边缘。
您能看出为什么边缘检测图像可能比原始图像更有用吗?回想一下MNIST手写数字分类问题。训练MNIST的CNN可能会寻找数字1,例如,使用边缘检测过滤器并检查图像中心附近的两个突出的垂直边缘。一般来说,卷积帮助我们寻找特定的局部图像特征(如边缘),我们可以在以后的网络中使用。
填充
还记得先用3×3过滤器对4×4输入图像进行卷积,以产生2×2输出图像吗?通常,我们希望输出图像的大小与输入图像的大小相同。为此,我们在图像周围添加零,以便我们可以在更多位置叠加过滤器。3×3滤镜需要1个像素的填充:

4×4输入与3×3过滤器卷积,使用相同的填充产生4×4输出
这称为“相同的”填充,因为输入和输出具有相同的尺寸。
Conv图层
请转到极客教程的深度学习专栏的《卷积神经网络(CNN)简介》https://geek-docs.com/deep-learning/cnn/cnn-introduce.html 继续查看后文。请多提宝贵意见,感谢。