GAN学习笔记(1):GAN综述
GAN学习笔记(1):GAN综述
生成式对抗模型GAN (Generativeadversarial networks) 是Goodfellow等[1]在 2014年提出的一种生成式模型,目前已经成为人工智能学界一个热门的研究方向,著名学者Yann Lecun甚至将其称为“过去十年间机器学习领域最让人激动的点子"。GAN的基本思想源自博弈论的二人零和博弈,由一个生成器和一个判别器构成,通过对抗学习的方式来训练,目的是估测数据样本的潜在分布并生成新的数据样本。在图像和视觉计算、语音和语言处理、信息安全、棋类比赛等领域,GAN正在被广泛研究,具有巨大的应用前景。
1 GAN的理论和实现模型
1.1 GAN的基本原理
GAN在结构上受博弈论中的二人零和博弈 (即二人的利益之和为零,一方的所得正是另一方的所失)的启发,它设定参与游戏双方分别为一个生成器 (Generator)和一个判别器 (Discriminator),生成器的目的是尽量去学习和捕捉真实数据样本的潜在分布,并生成新的数据样本;判别器是一个二分类器,目的是尽量正确判别输入数据是来自真实数据还是来自生成器,为了取得游戏胜利,这两个游戏参与者需要不断优化,各自提高自己的生成能力和判别能力,这个学习优化过程就是一个极小极大博弈(Minimax game)问题,目的是寻找二者之间的一个纳什均衡,使生成器估测到数据样本的分布。GAN的计算流程与结构如图1所示。


图1 GAN的计算流程与结构
任意可微分的函数都可以用来表示GAN的生成器和判别器,即生成器和判别器均可以采用目前研究火热的深度神经网络。若用可微分函数D和G来分别表示判别器和生成器,它们的输入分别为真实数据x和随机变量z。G(z)则为由G生成的尽量服从真实数据分布pdata的样本。如果判别器的输入来自真实数据,标注为1,如果输入样本为G(z),标注为0。D的目标是实现对数据来源的正确二分类判别:真(来源于真实数据x的分布)或者伪(来源于生成器的伪数据G(z)),而G的目标是使自己生成的伪数据G(z)在D上的表现D(G(z))和真实数据x在D上的表现D(x)一致,这两个相互对抗并迭代优化的过程使得D和G的性能不断提升,当最终D的判别能力提升到一定程度,并且无法正确判别数据来源时,可以认为这个生成器G已经学到了真实数据的分布[2]。
1.2 GAN的数学模型
GAN 的优化问题是一个极小极大化问题GAN的目标函数可以描述如下:
![]()
现证明如下。
首先,了解一个统计学概念KL divergence,即KL散度,在概率论或信息论中,KL散度又称相对熵(relative entropy),信息散度(informationdivergence),信息增益(information gain),是描述两个概率分布P和Q差异的一种方法,其越小,表示两种概率分布越接近。它是非对称的,这意味着D(P||Q) ≠ D(Q||P)。特别的,在信息论中,D(P||Q)表示当用概率分布Q来拟合真实分布P时,产生的信息损耗,其中P表示真实分布,Q表示P的拟合分布。
对于离散的概率分布,定义如下:

对于连续的概率分布,定义如下:
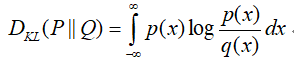
定义
![]()
则最优模型

首先看![]() ,即生成最优判别器得过程:
,即生成最优判别器得过程:

若上式取最大值,对给定的x积分项需最大,在数据给定,G给定的前提下,Pdata(x)与PG(x)都可以看作是常数,我们可以分别用a,b来表示他们,则:

得极大值点为:
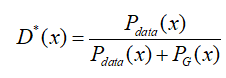
此即为判别器的最优解,即在给定G的前提下,能够使得V(D)取得最大值的D,由此可知, GAN 估计的是两个概率分布密度的比值,这也是和其他基于下界优化或者马尔科夫链方法的关键不同之处。将D代回原来的V(G,D),得到如下的结果:

由上式可知,取![]() 即为使两个KL散度最大,即使PG(x)与Pdata(x)的差异最大,而取
即为使两个KL散度最大,即使PG(x)与Pdata(x)的差异最大,而取![]() ,即使PG(x)与Pdata(x)的差异最小,从而形成对抗博弈效果,实现GAN原理。
,即使PG(x)与Pdata(x)的差异最小,从而形成对抗博弈效果,实现GAN原理。
实际训练时可以采用交替优化的方法:先固定生成器G,优化判别器D,使得D的判别准确率最大化;然后固定判别器D,优化生成器G,使得D的判别准确率最小化。当且仅当pdata = pG时达到全局最优解。训练GAN时,同一轮参数更新中,一般对D的参数更新k次再对 G的参数更新1次。
2 GAN的优点与缺陷
GAN是一种以半监督方式训练分类器的方法,可以帮助解决带标签训练集样本少的问题,模型训练时不需要对隐变量做推断, G的参数更新不是直接来自数据样本,而是来自D的反向传播。理论上,只要是可微分函数都可以用于构建D和G(虽然在实践中,很难使用增强学习去训练有离散输出的生成器),从而能够与深度神经网络结合做深度生成式模型。
从实际结果来看,GAN看起来能产生更好的生成样:相比完全明显的信念网络(NADE, Pixel RNN, WaveNet等),GAN因为不需要在采样序列生成不同的数据能更快的产生样本;相比依赖于蒙特卡洛估计和对数配分函数的玻尔兹曼,GAN不需要蒙特卡洛估计训练网络,更简单(蒙特卡洛方法在高维空间中效果不好,玻尔兹曼机从来没有拓展到像ImgeNet任务中,而GAN在ImageNet上训练后可以学习去画一些以假乱真的狗);相比于变分自编码器, GAN没有引入任何决定性偏置( deterministicbias)是渐进一致的,变分方法引入了决定性偏置是有偏差的,他们优化的是对数似然的下界,而不是似然度本身,从而导致VAE生成的实例比GAN更模糊;相比非线性ICA(NICE, Real NVE等),GAN不要求生成器输入的潜在变量有任何特定的维度或者要求生成器是可逆的;相比深度玻尔兹曼机和GSNs, GAN没有变分下界,也没有棘手的配分函数,样本是一次生成的,而不是重复的应用马尔科夫链来生成[3] [4]。
GAN虽然解决了生成式模型的一些问题,并且对其他方法的发展具有一定的启发意义,但是 GAN并不完美,它在解决已有问题的同时也引入了一些新的问题。 GAN 最突出的优点同时也是它最大的问题根源。GAN采用对抗学习的准则,理论上还不能判断模型的收敛性和均衡点的存在性。训练过程需要保证两个对抗网络的平衡和同步,否则难以得到很好的训练效果。而实际过程中两个对抗网络的同步不易把控,训练过程可能不稳定。同时,GAN很难学习生成如文本的离散数据,相比玻尔兹曼机,GAN只能一次产生所有像素,难以根据一个像素值猜测另一个像素值(虽然可以用BiGAN来修正这个特性,它能像玻尔兹曼机一样去使用Gibb采样来猜测缺失值)。而作为以神经网络为基础的生成式模型, GAN也存在神经网络类模型的一般性缺陷,即可解释性差,生成模型的分布 PG(x)没有显式的表达。最后GAN生成的样本虽然具有多样性,但是存在崩溃模式 (Collapse mode)现象,可能生成多样的,但对于人类来说差异不大的样本[3] [4]。
3 GAN的衍生模型
自Goodfellow等于2014年提出GAN以来,各种基于GAN的衍生模型被提出,以改进模型结构,进一步进行理论扩展及应用。以下重点介绍其中有代表性的几种。
3.1 WGAN
GAN在基于梯度下降训练时存在梯度消失的问题,因为当真实样本和生成样本之间具有极小重叠甚至没有重叠时,其目标函数的Jensen-Shannon散度是一个常数(JS散度是一个对称化的KL散度),导致优化目标不连续。为了解决训练梯度消失问题,Arjovsky等提出了 Wasserstein GAN (WGAN)[5]。WGAN用Earth-Mover代替Jensen-Shannon散度来度量真实样本和生成样本分布之间的距离,相比KL散度、JS散度,Earth-Mover距离是平滑的,即便两个分布没有重叠,仍能反映它们的远近,从而提供有意义的梯度。WGAN用一个批评函数f来对应GAN的判别器,而且批评函数f需要建立在Lipschitz连续性假设上。WGAN开创性的做到了以下几点[6]:
(1)彻底解决GAN训练不稳定的问题,不再需要小心平衡生成器和判别器的训练程度
(2)基本解决了崩溃模式现象,确保了生成样本的多样性
(3)训练过程中有一个像交叉熵、准确率这样的数值来指示训练的进程,这个数值越小代表GAN训练得越好,代表生成器产生的图像质量越高。(如图2所示)
(4)实现不需要精心设计的网络架构,最简单的多层全连接网络就可以做到
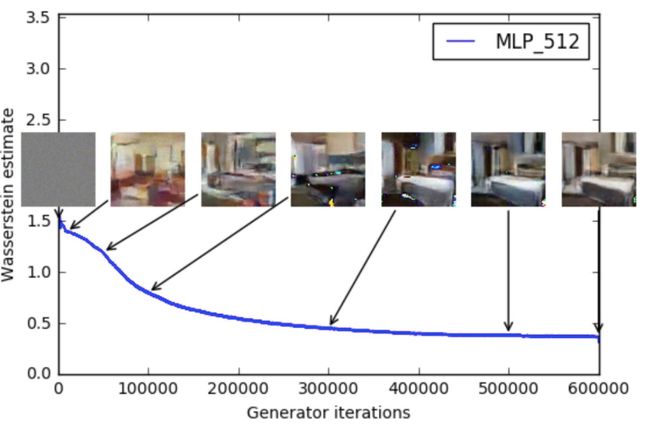
图2 WGAN效果判别图
3.2 DCGAN
2016年,Radford等人发表了一篇名为《Unsupervised Representation Learning with DeepConvolutional Generative Adversarial Networks》的论文[7],文中提出了GAN架构的升级版,把有监督学习的CNN与无监督学习的GAN整合到一起提出了DCGAN(深度卷积生成式对抗网),生成器和判别器分别学到对输入图像层次化的表示。
DCGAN的主要贡献是[8][9]:
(1) 为CNN的网络拓扑结构设置了一系列的限制来使得它可以稳定的训练。
(2) 使用DCGAN从大量的无标记数据(图像、语音)学习到有用的特征,相当于利用无标记数据初始化DCGAN生成器和判别器的参数,用于如图像分类的有监督场景,得到比较好的效果来验证生成的图像特征表示的表达能力。
(3) 对GAN学习到的filter进行了定性的分析,尝试理解和可视化GAN是如何工作的。
(4) 展示了生成的特征表示的向量计算特性。
DCGAN一共做了一下几点改造[8][9]:
(1)去掉了G网络和D网络中的pooling layer。
(2)在G网络和D网络中都使用Batch Normalization
(3)去掉全连接的隐藏层
(4)在G网络中除最后一层使用RELU,最后一层使用Tanh
(5)在D网络中每一层使用LeakyRELU。
虽然缺乏理论的支撑只是从工程的角度调出的不错的效果,DCGAN架构比较稳定,开创了图像生成的先河,是首批证明向量运算可以作为从生成器中学习的固有属性表征的论文,它和Word2Vec中的向量技巧类似,只不过是适用于图像的。图3为DCGAN生成器网络结构,四个堆叠的卷积操作来构成生成器G,没有采用全连接层。

图3 DCGAN生成器网络结构
3.3 CGAN
2014年Mirza等[10]提出条件生成式对抗网络CGAN尝试在生成器G和判别器端加入额外的条件信息(additionalinformation)来指导GAN两个模型的训练,从而解决图像标注、图像分类和图像生成过程中,存在的输出图像的标签较多,有成千上万类别和对于一个输入,合适输出标签的类别多两类问题。
如图4所示,CGAN直接把额外的信息y添加到生成器G和判别器D的目标函数中,与输入Z和X中构成条件概率,训练方式几乎不变,但是从GAN的无监督变成了有监督。

图4 CGAN判别器及生成器结构图
用于指导G和D训练的额外信息可以是各种类型(multi-modal)的数据,以图像分类为例,可以是label标签,也可以是关于图像类别或其他信息的text文本描述。
3.4 InfoGAN
GAN能够学得有效的语义特征,但是输入噪声变量z的特定变量维数和特定语义之间的关系不明确,2016年Xi Che[11]等提出一种信息理论与GAN相结合的生成式对抗网络InfoGAN,获取输入的隐层变量和具体语义之间的互信息,采用无监督的方式学习到输入样本X的可解释且有意义的表示。
InfoGAN引入了信息论中的互信息(mutualinformation)概念,来表征两个数据的相关程度。具体实现如图5,生成器G的输入分为两部分z和c,这里z和GAN的输入一致,而c被称为隐码,这个隐码用于表征结构化隐层随机变量和具体特定语义之间的隐含关系。GAN设定了pG(x)= pG(x|c),而实际上c与G的输出具有较强的相关性。用G(z,c)来表示生成器的输出,作者提出利用互信息I(c;G(z,c))来表征两个数据的相关程度,用目标函数
![]()
来建模求解,这里由于后验概率p(c|x)不能直接获取,需要引入变分分布来近似后验的下界来求得最优解。

图5 InfoGAN的计算流程与结构
3.5 SeqGAN
GAN的输出为连续实数分布而无法产生离散空间的分布:GAN的生成器G需要利用从判别器D得到的梯度进行训练,G和D都需要完全可微,当处理离散变量时会出现不能为G提供训练的梯度的情况,同时GAN只可以对已经生成的完整序列进行打分,而对一部分生成的序列,难以判断现在生成的一部分的质量和之后生成整个序列的质量[9]。为解决上述问题,将GAN成功运用到自然语言处理邻域,2016年Yu等[12]借鉴强化学习中reward思想,提出了一种能够生成离散序列的生成式模型SeqGAN,如图6所示,他们用RNN实现生成器G,用CNN实现判别器D,用D的输出判别概率通过增强学习来更新G。增强学习中的奖励通过D来计算,对于后面可能的行为采用了蒙特卡洛搜索实现,计算D的输出平均作为奖励值反馈。实验表明SeqGAN在语音、诗词和音乐生成方面可以超过传统方法。
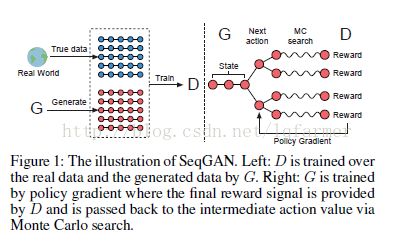
图6 SeqGAN结构示意图
4 GAN的应用方向
作为一个具有“无限"生成能力的模型,GAN的直接应用就是建模,生成与真实数据分布一致的数据样本,例如可以生成图像、视频等。GAN可以用于解决一些传统的机器学习中所面临的标注数据不足时的学习问题,例如无监督学习、半监督学习、多视角、多任务学习等。最近有一些工作已经将进行成功应用在强化学习中,来提高强化学习的学习效率,GAN还可以用于语音和语言处理,例如生成对话、由文本生成图像、自然语句和音乐等。因此GAN有着非常广泛的应用[2]。
4.1 图像和视觉领域
从目前的文献来看,GAN在图像上的应用主要用于图像修改包括:单图像超分辨率、交互式图像生成、图像编辑、图像到图像的翻译等。
4.1.1 单图像超分辨率
GAN能够生成与真实数据分布一致的图像。一个典型应用来自Twitter公司, Ledig等[13]提出利用GAN来将一个低清模糊图像变换为具有丰富细节的高清图像。作者用 VGG 网络作为判别器,用参数化的残差网络表示生成器,其算法思路如图7所示,实验结果如图8所示,可以看到GAN生成了细节丰富的图像。

图7 Twitter图像超分辨率算法示意图

图8 Twitter图像超分辨率效果
4.1.2 交互式图像生成
Adobe公司构建了一套图像编辑操作[14],如图9,能使得经过这些操作以后,图像依旧在“真实图像流形”上,因此编辑后的图像更接近真实图像。
具体来说,iGAN的流程包括以下几个步骤:
1. 将原始图像投影到低维的隐向量空间
2. 将隐向量作为输入,利用GAN重构图像
3. 利用画笔工具对重构的图像进行修改(颜色、形状等)
4. 将等量的结构、色彩等修改应用到原始图像上。
值得一提的是,作者提出G需为保距映射的限制,这使得整个过程的大部分操作可以转换为求解优化问题,整个修改过程近乎实时。

图9 Adobe图像编辑
4.1.3 图像到图像的翻译
如图10,“图像到图像的翻译”是指将一种类型的图像转换为另一种类型的图像,比如:将草图具象化、根据卫星图生成地图等[15]。

图10 图像到图像的翻译
4.2 自然语言处理领域
GAN在自然语言处理上的应用可以分为两类:生成文本、根据文本生成图像。其中,生成文本包括两种:根据隐向量(噪声)生成一段文本;对话生成。
4.2.1 对话生成
Li J等2017年发表的Adversarial Learning for Neural Dialogue Generation[16]显示了GAN在对话生成领域的应用。实验效果如图11。可以看出,生成的对话具有一定的相关性,但是效果并不是很好,而且这只能做单轮对话。

如图11 Li J对话生成效果
4.2.2 文本到图像的翻译
GAN也能用于文本到图像的翻译(textto image),文本到图像的翻译指GAN的输入是一个描述图像内容的一句话,比如“一只有着粉色的胸和冠的小鸟”,那么所生成的图像内容要和这句话所描述的内容相匹配。
在ICML 2016会议上,Scott Reed等[17]人提出了基于CGAN的一种解决方案将文本编码作为generator的condition输入;对于discriminator,文本编码在特定层作为condition信息引入,以辅助判断输入图像是否满足文本描述。作者提出了两种基于GAN的算法,GAN-CLS和GAN-INT。

如图12 ScottReed文中用到的GAN架构
实验结果如图13所示,实验发现生成的图像相关性很高。


图13Scott Reed文本到图像的翻译效果
4.3 GAN与增强学习的结合
Ian Goodfellow指出,GAN很容易嵌入到增强学习(reinforcementlearning)的框架中。例如,用增强学习求解规划问题时,可以用GAN学习一个actions的条件概率分布,agent可以根据生成模型对不同的actions的响应,选择合理的action。
GAN与RL结合的典型工作有:将GAN嵌入模仿学习(imitationlearning)中[18];将GAN嵌入到策略梯度算法(policy gradient)中[19],将GAN嵌入到actor-critic算法中[20]等。
GAN与增强学习结合的相关工作多数在16年才开始出现,GAN和RL属于近年来的研究热点,两者结合预计在接下来的一两年里将得到更多研究者的青睐。
5 GAN的未来发展方向
1.针对GAN可解释性差进行改进。包括最近刚提出的InfoGANs。InfoGANs通过最大化隐变量与观测数据的互信息,来改进GAN的解释性。
2.进一步提高GAN的学习能力。包括引入“多主体的GAN”。在多主体的GAN中,有多个生成器和判别器,它们之间可以进行交流,进行知识的共享,从而提高整体的学习能力。
3.针对GAN优化不稳定性进行改进。例如使用 F散度来作为一个优化目标和手段,对GAN进行训练。
4.应用在一些更广泛的领域。包括迁移学习以及领域自适应学习。建立GAN和强化学习之间的联系,将GAN用在了逆强化学习和模拟学习上,从而能够大幅度提高强化学习的学习效率。另外还可以用在数据的压缩上以及应用在除了图像以外其他的数据模式上,比如用于自然语句的生成,还有音乐的生成[21]。
参考文献:
[1] Goodfellow I, Pouget-Abadie J, Mirza M, Xu B,WardeFarley D, Ozair S, Courville A, Bengio Y. Generative adversarial nets. In:Proceedings of the 2014 Conference on Advances in Neural Information ProcessingSystems 27. Montreal, Canada: Curran Associates, Inc., 2014. 2672¡2680
[2] 王坤峰,苟超,段艳杰,林懿伦,郑心湖,王飞跃.生成式对抗网络 GAN的研究进展与展望.自动化学报, 2017, 43(3): 321¡332
[3] Ian Goodfellow,Answer of What are the pros and cons of usinggenerative adversarial networks (a type of neural network)? Could they beapplied to things like audio waveform via RNN? Why or why not, Quora, 2016,https://www.quora.com/What-are-the-pros-and-cons-of-using-generative-adversarial-networks-a-type-of-neural-network-Could-they-be-applied-to-things-like-audio-waveform-via-RNN-Why-or-why-not
[4] 元峰,关于生成对抗网络(GAN)相比传统训练方法有什么优势的回答,知乎, 2017, https://www.zhihu.com/question/56171002?utm_medium=social&utm_source=weibo
[5] Arjovsky M, Chintala S, Bottou L. Wasserstein GAN.arXiv preprint arXiv: 1701.07875, 2017
[6] 郑华滨,令人拍案叫绝的Wasserstein GAN,知乎,2016,https://zhuanlan.zhihu.com/p/25071913
[7] Radford A, Metz L, Chintala S. UnsupervisedRepresentation Learning with Deep Convolutional Generative AdversarialNetworks[J]. Computer Science, 2015.
[8] 张雨石,深度卷积对抗生成网络(DCGAN), CSDN, 2016,http://blog.csdn.net/stdcoutzyx/article/details/53872121
[9] lqfarmer, <模型汇总_5>生成对抗网络GAN及其变体SGAN_WGAN_CGAN_DCGAN_InfoGAN_StackGAN, CSDN, 2017, http://blog.csdn.net/lqfarmer/article/details/71514254
[10] Mirza M, Osindero S.Conditional generative adversarial nets. arXiv preprint arXiv: 1411.1784, 2014
[11] Chen X, Duan Y, Houthooft R, SchulmanJ, Sutskever I, Abbeel P. InfoGAN: interpretable representation learning byinformation maximizing generative adversarial nets. In: Proceedings of the 2016Neural Information Processing Systems. Barcelona, Spain: Department ofInformation Technology IMEC, 2016. 2172¡2180
[12] Yu L T, Zhang W N, Wang J, Yu Y.SeqGAN: sequence generative adversarial nets with policy gradient. arXivpreprint arXiv: 1609.05473, 2016
[13] Ledig C, Theis L, Husz¶ar F, CaballeroJ, Cunningham A, Acosta A, Aitken A, Tejani A, Totz J, Wang Z H, Shi W Z.Photo-realistic single image super-resolution using a generative adversarialnetwork. arXiv preprint arXiv: 1609.04802, 2016
[14] Zhu J Y, KrähenbühlP, Shechtman E, et al. Generative visualmanipulation on the natural imagemanifold[C]//European Conference on ComputerVision. Springer InternationalPublishing, 2016: 597-613
[15] Isola P, Zhu J Y,Zhou T, et al. Image-to-Image Translation with Conditional AdversarialNetworks[J]. 2016.
[16] Li J W, Monroe W, Shi TL, Jean S, Ritter A, Jurafsky D. Adversarial learning for neural dialoguegeneration. arXiv preprint arXiv: 1701.06547, 2017
[17] Reed S, Akata Z, Yan XC, Logeswaran L, Lee H, Schiele B. Generative adversarial text to imagesynthesis. In: Proceedings of the 33rd International Conference on MachineLearning. New York, NY, USA: ICML, 2016
[18] HoJ, Ermon S. Generative adversarial imitationlearning[C]//Advances in NeuralInformation Processing Systems. 2016:4565-4573
[19] YuL, Zhang W, Wang J, et al. Seqgan: sequence generativeadversarial nets withpolicy gradient[J]. arXiv preprint arXiv:1609.05473,2016
[20] PfauD, Vinyals O. Connecting generative adversarialnetworks and actor-criticmethods[J]. arXiv preprint arXiv:1610.01945, 2016
[21] 亚萌,深度学习新星:GAN的基本原理、应用和走向 | 硬创公开课,雷锋网,2017,https://www.leiphone.com/news/201701/Kq6FvnjgbKK8Lh8N.html