字节跳动一面
2019.5.13经历了字节跳动一面啊,希望啊,不要把我扔掉,虽然我的确在数据结构和算法那里值得扔掉。。。。。。
记录下问题吧。
1自我介绍
(一)自我介绍
您好,我叫,来自。。。。,目前本科,大三年级,专业是计算机。
先和您介绍下我大学的经历吧。
1我的学习成绩还不错;
2大学期间我曾参加过一些开发类的比赛,比如说微信小程序开发,我负责后端开发工作;
3我也曾和多位前端合作过,一起做项目参加比赛,也是负责后端开发,主要就是根据想好要做什么,共同商量需求,开发接口,写接口文档,数据库设计;
再和您说下我的实习经历吧
1。。。实习,也是做后端,项目主语言是node,自学node, 给服务压测,
前端离职,又有新需求,我就负责在原有代码上改改改,前后端分离,项目调研
2说下你的两个项目吧
中帐+ai广告后台,总结的不是很好,有些逻辑混乱
中帐----一个node服务,这个服务用于数据透传,子系统和ssp系统之间的数据透传。。。。。。。子系统请求我的接口,我的接口携带子系统数据去请求ssp接口,再把响应数据返回给ssp
ai广告后台:一个互动广告管理系统,主要是web后台服务
3看了你用到了nginx,那你说一下正向代理,反向代理的区别吧
分享关于在服务器代理中正向代理与反向代理的区别,在实际运用中两者都有很大的用处,但是往往很多人并不是特别清楚他们之前的区别,先通过几张图片进行分析。
正向代理:
正向代理通过上面的图理解其实就是用户想从服务器拿资源数据,但是只能通过proxy服务器才能拿到,所以用户A只能去访问proxy服务器然后通过proxy服务器去服务器B拿数据,这种情况用户是明确知道你要访问的是谁,在我们生活中最典型的案例就是““了,也是通过访问代理服务器最后访问外网的。
反向代理:
反向代理其实就是客户端去访问服务器时,他并不知道会访问哪一台,感觉就是客户端访问了Proxy一样,而实则就是当proxy关口拿到用户请求的时候会转发到代理服务器中的随机(算法)某一台。而在用户看来,他只是访问了Proxy服务器而已,典型的例子就是负载均衡了。
即:正向代理就是代理为客户的代理,正向代理代理的是客户
反向代理就是代理为服务器的代理,反向代理代理的是服务器
4你说你项目中用到了redis是吧,你说说具体哪里用了redis,怎么用的,redis都有哪些结构,zset底层数据结构,如果内存满了,在向redis里插入数据,怎么解决(1增大memorary 2采用淘汰策略 )
【http://www.redis.cn/topics/lru-cache.html】
若果内存满了,就使用lru/random回收淘汰策略,或者将热数据存储到外存中。。。。
我们知道,redis设置配置文件的maxmemory参数,可以控制其最大可用内存大小(字节)。
那么当所需内存,超过maxmemory怎么办?
这个时候就该配置文件中的maxmemory-policy出场了。
其默认值是noeviction。
下面我将列出当可用内存不足时,删除redis键具有的淘汰规则。
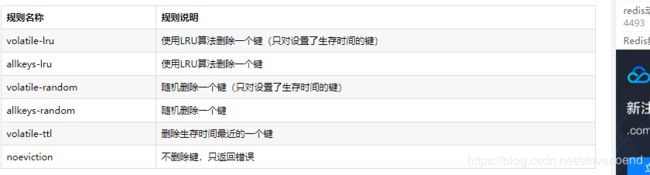
LRU算法,least RecentlyUsed,最近最少使用算法。也就是说默认删除最近最少使用的键。
但是一定要注意一点!redis中并不会准确的删除所有键中最近最少使用的键,而是随机抽取3个键,删除这三个键中最近最少使用的键。
那么3这个数字也是可以设置的,对应位置是配置文件中的maxmeory-samples.
ai互动广告gate端用了redis,用到了hash结构,你具体说下你怎么拿到的可用的broker的ip和port?
如果broker挂掉了,而此时redis却没有来的及更新,此时android端拿到了挂掉的ip,那你说怎么解决?
我给出的解决方案是:1心跳检测频率加快 2android端重新请求gate,当他发现拿到的ip和port是失效的时,
面试官问我,还有什么解决方案吗,我没想出来
zset数据结构:跳表+压缩双向链表(skiplist+ziplist)
一、描述
redis其中一个数据结构为zset(sorted set-有序集合),其主要作用用于排行榜实现,你可以获取排名第几到第几的数据
二、数据结构
sorted set-有序集合在redis中有两种实现
1.ziplist,压缩双向链表,相关链接
2.skiplist,跳表实现
三、skiplist数据结构

score:分值,用于排序
backward:是第一层的前一个数据,即span=1
level[]:每一个层所代表的节点node
forward:该层级的下一个节点
span:到达该层级的下一个节点,实际跨越了多少个节点,也是方便用于zrange等排行榜查询的用处
四、注意点
4.1 插入数据
1.在插入数据的时候,通过level[]快速跳过不需要比较的节点,快速定位节点位置
2.在插入新的节点的时候,level[]的层级由随机决定该层级的高度
3.然后更新每一次受到影响的span,span代表该层节点到达下一节点应该要跨越的节点数量
4.2 查询排行榜,如zrange
1.先根据start,通过level[]和每一次的rank来快速定位第一层的起始位置
2.然后再根据end,来将结果输出给用户
五、参数控制
redis配置文件中用来控制zset到底是使用ziplist(压缩双向链表)还是skiplist(跳表)的参数:
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
zset-max-ziplist-entries zset使用ziplist存储的时候,最大限制存储entries的个数
zset-max-ziplist-value zset使用ziplist存储的时候,每个节点最大存储字节数
违反上述两个限制条件,均会导致zset将ziplist的数据结构切换为skiplist数据结构
而zset使用ziplist的原因,主要是出于在零散数据量少的时候,节省内容的占用
5mysql你有用到吗,你说下你有建索引吗,你说下你会在哪里建索引,你说下索引的数据结构吧,你知道为什么b+树搜索就快吗,
https://www.cnblogs.com/aspirant/p/9214485.html
我只解答出在经常查询的字段上建索引,在查询的字段上建立索引,面试官问我还有吗?
主键、外键、where、group by、order by、选择性高的列,数据量大的表,进行连接的表,
1. 表的主键、外键必须有索引
2. 数据量超过300的表应该有索引
3. 经常与其他表进行连接的表,在连接字段上应该建立索引
4. 经常出现在where字句中的字段,特别是大表的字段,应该建立索引
5. 索引应该建在选择型高的字段上
6. 索引应该建在小字段上,对于大的文本字段甚至超长字段,不要建索引
7. 复合索引的建立需要进行仔细分析,尽量考虑使用单字段索引代替:
① 正确选择复合索引中的主列字段,一般是选择性较好的字段
② 复合索引的杰哥字段是否经常同时以AND方式出现在where子句中?单字段查询是否极少甚至没有?如果是,则可以建立复合索引;否则考虑单字段索引;
③ 如果复合索引中包含的字段经常单独出现在Where子句中,则分解为多个单字段索引;
④ 如果复合索引所包含的字段超过3个,那么仔细考虑其必要性,考虑减少复合的字段;
⑤ 如果既有单字段索引,又有这几个字段上的复合索引,一般可以删除复合索引;
8. 频繁进行数据操作的表,不要建立太多的索引;
6进程和线程的区别?进程之间的通信方式?
我说了信号量,面试官问我还有吗。。。。
https://blog.csdn.net/wm12345645/article/details/82381407
信号量+管道+共享内存+消息队列
7说下https建立连接的过程?
我不会。。。。
思考问题的顺序
学技术时,总是会问什么?这里也不例外,https为什么会存在,它有什么优点,又有什么缺点?为什么网站有的用http,有的用https?如果不能很好的回答,就往下看吧。
http通信存在的问题
容易被监听
http通信都是明文,数据在客户端与服务器通信过程中,任何一点都可能被劫持。比如,发送了银行卡号和密码,hacker劫取到数据,就能看到卡号和密码,这是很危险的
被伪装
http通信时,无法保证通行双方是合法的,通信方可能是伪装的。比如你请求www.taobao.com,你怎么知道返回的数据就是来自淘宝,中间人可能返回数据伪装成淘宝。
被篡改
hacker中间篡改数据后,接收方并不知道数据已经被更改
共享密钥加密和公开密钥加密
后续内容的需要,这里插播一段共享密钥加密和公开密钥加密
共享密钥加密
共享密钥的加密密钥和解密密钥是相同的,所以又称为对称密钥
公开密钥加密
加密算法是公开的,密钥是保密的。公开密钥分为私有密钥和公有密钥,公有密钥是公开的,任何人(客户端)都可以获取,客户端使用公有密钥加密数据,服务端用私有密钥解密数据。
异同
共享密钥加密与公开密钥加密相比,加解密处理速度快,但公开密钥更适应互联网下使用
https解决的问题
https很好的解决了http的三个缺点(被监听、被篡改、被伪装),https不是一种新的协议,它是http+SSL(TLS)的结合体,SSL是一种独立协议,所以其它协议比如smtp等也可以跟ssl结合。https改变了通信方式,它由以前的http—–>tcp,改为http——>SSL—–>tcp;https采用了共享密钥加密+公开密钥加密的方式
防监听
数据是加密的,所以监听得到的数据是密文,hacker看不懂。
防伪装
伪装分为客户端伪装和服务器伪装,通信双方携带证书,证书相当于身份证,有证书就认为合法,没有证书就认为非法,证书由第三方颁布,很难伪造
防篡改
https对数据做了摘要,篡改数据会被感知到。hacker即使从中改了数据也白搭。
https连接过程
服务器端需要认证的通信过程
客户端发送请求到服务器端
服务器端返回证书和公开密钥,公开密钥作为证书的一部分而存在
客户端验证证书和公开密钥的有效性,如果有效,则生成共享密钥并使用公开密钥加密发送到服务器端
服务器端使用私有密钥解密数据,并使用收到的共享密钥加密数据,发送到客户端
客户端使用共享密钥解密数据
SSL加密建立………
客户端认证的通信的过程
客户端需要认证的过程跟服务器端需要认证的过程基本相同,并且少了最开始的两步。这种情况都是证书存储在客户端,并且应用场景比较少,一般金融才使用,比如支付宝、银行客户端都需要安装证书
后续的问题
怎样保证公开密钥的有效性
你也许会想到,怎么保证客户端收到的公开密钥是合法的,不是伪造的,证书很好的完成了这个任务。证书由权威的第三方机构颁发,并且对公开密钥做了签名。
https的缺点
https保证了通信的安全,但带来了加密解密消耗计算机cpu资源的问题 ,不过,有专门的https加解密硬件服务器
各大互联网公司,百度、淘宝、支付宝、知乎都使用https协议,为什么?
支付宝涉及到金融,所以出于安全考虑采用https这个,可以理解,为什么百度、知乎等也采用这种方式?为了防止运营商劫持!http通信时,运营商在数据中插入各种广告,用户看到后,怒火发到互联网公司,其实这些坏事都是运营商(移动、联通、电信)干的,用了https,运营商就没法插播广告篡改数据了。
以上内容,来自个人对《图解HTTP》一书中https通信部分的理解,加上知乎牛人解答的理解,汇总而成
9算法靠你一下,说下思路,
手写一个二分查找函数,我由于很久没有刷题了,写了半天。。。。之后面试官人比较好,让我说了一下实现思路
有序的序列,每次都是以序列的中间位置的数来与待查找的关键字进行比较,每次缩小一半的查找范围,直到匹配成功。
一个情景:将表中间位置记录的关键字与查找关键字比较,如果两者相等,则查找成功;否则利用中间位置记录将表分成前、后两个子表,如果中间位置记录的关键字大于查找关键字,则进一步查找前一子表,否则进一步查找后一子表。重复以上过程,直到找到满足条件的记录,使查找成功,或直到子表不存在为止,此时查找不成功。
求1-n所有数的总共含有1的个数,我说了下思路,字符串连接,硬生生遍历,,显然不是最优解。。。
https://www.cnblogs.com/churi/p/3961527.html
N为正整数,计算从1到N的所有整数中包含数字1的个数。比如,N=10,从1,2...10,包含有2个数字1。
相信很多人都能立刻得出以下的解法:
for(n:N)
{
判断n包含1的个数;
累加计数器;
}
这是最直接的解法,但遗憾的是,时间复杂程度为O(N*logN)。因为还需要循环判断当前的n的各位数,该判断的时间复杂程度为O(logN)。
接下来就应该思考效率更高的解法了。说实话,这道题让我想起另外一道简单的算法题:
N为正整数,计算从1到N的整数和。
很多人都采用了循环求解。然后利用初等数学知识就知道S=N*(N+1)/2,所以用O(1)的时间就可以处理。
再回到本道题目,同理应该去寻找到结果R与N之间的映射关系。
分析如下:
假设N表示为a[n]a[n-1]...a[1],其中a[i](1<=i<=n)表示N的各位数上的数字。
c[i]表示从整数1到整数a[i]...a[1]中包含数字1的个数。
x[i]表示从整数1到10^i - 1中包含数字1的个数,例如,x[1]表示从1到9的个数,结果为1;x[2]表示从1到99的个数,结果为20;
当a[1]=0时,c[1] = 0;
当a[1]=1时,c[1] = 1;
当a[1]>1时,c[1] = 1;
当a[2]=1时,c[2] = a[1] +1+ c[1] + x[1];
当a[2]>1时,c[2] = a[2]*x[1]+c[1]+10;
当a[3]=1时,c[3] = a[2]*a[1] +1+ c[2] + x[2];
当a[3]>1时,c[3] = a[3]*x[2]+c[2]+10^2;
......
以此类推
当a[i]=1时,c[i] = a[i-1]*...*a[1] +1+ c[i-1]+x[i-1];
当a[i]>1时,c[i] = a[i]x[i-1]+c[i-1]+10^(i-1);
实现的代码如下:
-
public static int search(int _n) -
{ -
int N = _n/10; -
int a1 = _n%10,a2; -
int x = 1; -
int ten = 10; -
int c = a1 == 0?0:1; -
while(N > 0) -
{ -
a2 = N%10; -
if(a2 == 0); -
else if(a2 == 1)c = a1 + 1 + x + c; -
else c = a2*x + c + ten; -
a1 = 10*a1 + a2; -
N /=10; -
x = 10*x + ten; -
ten *= 10; -
} -
return c; -
}
判断链表是否有环。。。。。
对于这个问题我们可以采用“快慢指针”的方法。就是有两个指针fast和slow,开始的时候两个指针都指向链表头head,然后在每一步
操作中slow向前走一步即:slow = slow->next,而fast每一步向前两步即:fast = fast->next->next。
由于fast要比slow移动的快,如果有环,fast一定会先进入环,而slow后进入环。当两个指针都进入环之后,经过一定步的操作之后二者一定能够在环上相遇,并且此时slow还没有绕环一圈,也就是说一定是在slow走完第一圈之前相遇。证明可以看下图:

当slow刚进入环时每个指针可能处于上面的情况,接下来slow和fast分别向前走即:
[cpp] view plaincopyprint?
- if (slow != NULL && fast->next != NULL)
- {
- slow = slow -> next ;
- fast = fast -> next -> next ;
- }
也就是说,slow每次向前走一步,fast向前追了两步,因此每一步操作后fast到slow的距离缩短了1步,这样继续下去就会使得
两者之间的距离逐渐缩小:...、5、4、3、2、1、0 -> 相遇。又因为在同一个环中fast和slow之间的距离不会大于换的长度,因此
到二者相遇的时候slow一定还没有走完一周(或者正好走完以后,这种情况出现在开始的时候fast和slow都在环的入口处)。
下面给出问题1的完整代码:
[cpp] view plaincopyprint?
- typedef struct node{
- char data ;
- node * next ;
- }Node;
- bool exitLoop(Node *head)
- {
- Node *fast, *slow ;
- slow = fast = head ;
- while (slow != NULL && fast -> next != NULL)
- {
- slow = slow -> next ;
- fast = fast -> next -> next ;
- if (slow == fast)
- return true ;
- }
- return false ;
- }
10最后面试官比较善良,让我等通知,其实我知道没戏。。。。
谢谢善良的面试官,我发誓会把今天的东西都弄懂的。。。。。。
我知道自己有多菜,却生硬的面试了宇宙第一条,来日方长,我能行,虽然此次这么简单的题,都被我面的这么水,但我知道以后该怎么办了