Kylin安装,Kylin网页版教程学习
25 Kylin安装
参考网址:
http://kylin.apache.org/cn/docs/tutorial/web.html
http://kylin.apache.org/cn/docs23/install/
http://kylin.apache.org/25.1.环境
Kylin需要一个hadoop环境才可以运行,需要的环境:
Hadoop: 2.4+
Hive: 0.13+
HBase: 0.98+, 1.x
JDK: 1.7+25.2.安装
参考地址:http://kylin.apache.org/cn/docs23/install/
将下载的apache-kylin-2.3.1-hbase1x-bin.tar.gz上传到/home/bigdata/software,然后解压到:/home/bigdata/installed目录下。
[root@bigdata1 software]# tar -zxvf apache-kylin-2.3.1-hbase1x-bin.tar.gz -C /home/bigdata/installed配置环境变量:
export KYLIN_HOME=/home/bigdata/installed/apache-kylin-2.3.1-bin
export PATH=$PATH:$KYLIN_HOME/bin然后执行:
[root@bigdata1 apache-kylin-2.3.1-bin]# source /etc/profile启动Kylin
[root@bigdata2 bin]# cd $KYLIN_HOME
[root@bigdata1 apache-kylin-2.3.1-bin]# ./bin/kylin.sh start停止Kylin
[root@bigdata1 apache-kylin-2.3.1-bin]# ./bin/Kylin.sh stop安装完成之后,可以访问:http://bigdata1:7070/kylin

上面的用户名和密码是:ADMIN/KYLIN (必须大写)
25.2.Kylin网页版教程
http://kylin.apache.org/cn/docs23/tutorial/create_cube.html25.2.1.通过使用Sample Cube快速入门
Kylin为大家提供了一个创建一个简单Cube的脚本,这个脚本同样创建5个简单的hive tables:
1.运行${KYLIN_HOME}/bin/samples.sh,重启kylin服务器去刷新缓冲。
2.以默认用户名和密码 ADMIN/KYLIN登录Kylin的web系统,在项目下拉选中选择”learn_kylin”(左上角)
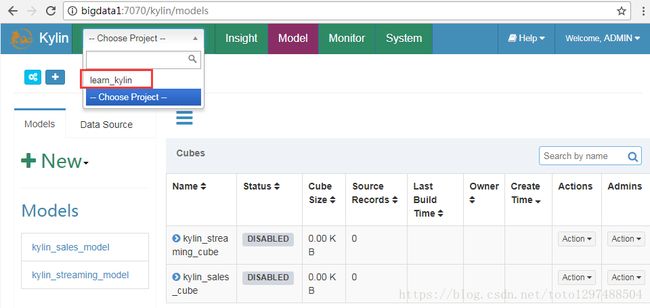
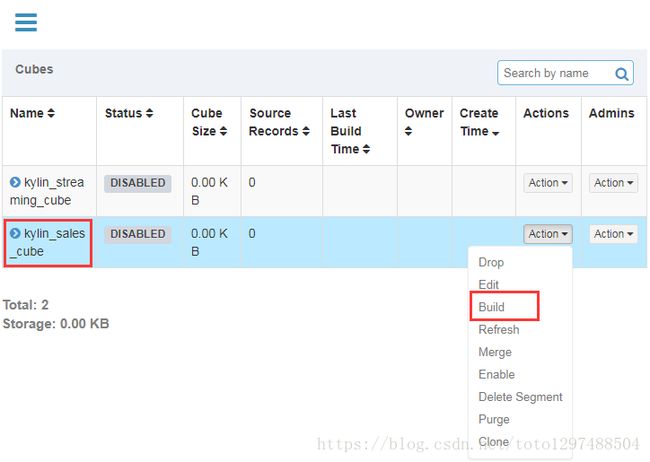
3.选择这个简单的cube “kylin_sales_cube”,点击”Actions”—>”Build”,过程中出现:
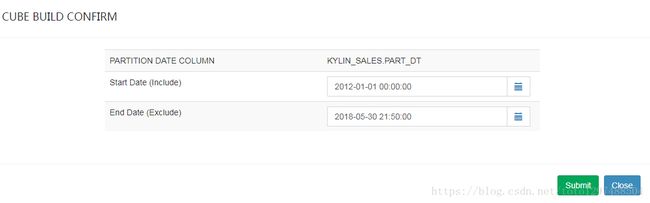
弹框中会出现一个End Date(Exclude)
4.在”Insight”的tab中执行SQL。例如:
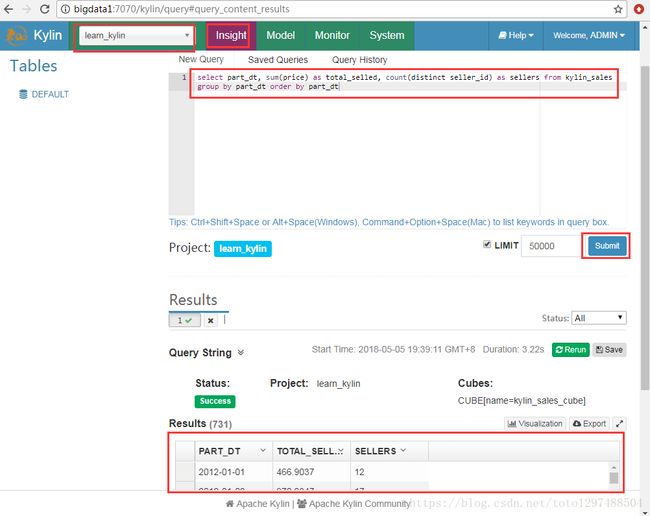
到hive验证结果:
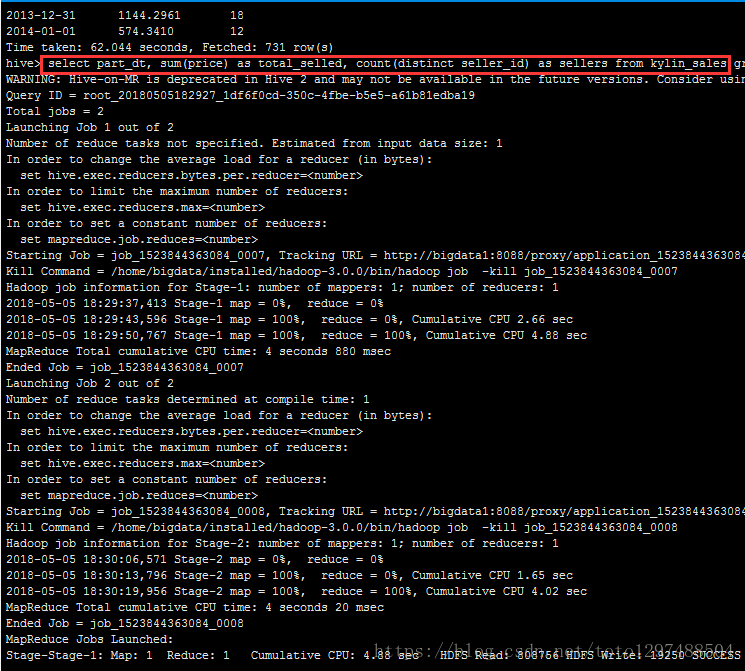
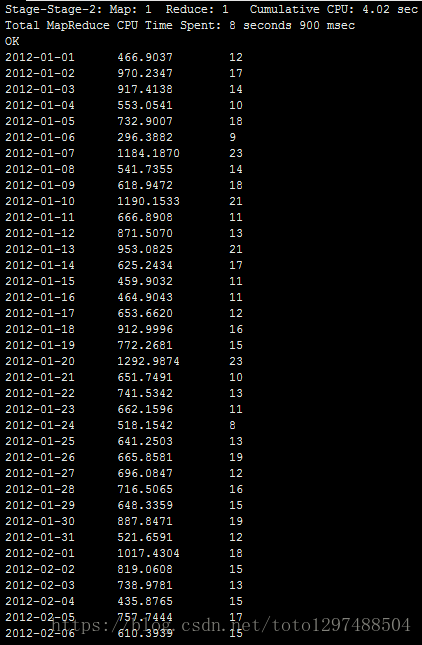
5.使用Monitor查看job运行状况
在运行过程中,可以查看Monitor中出现错误:
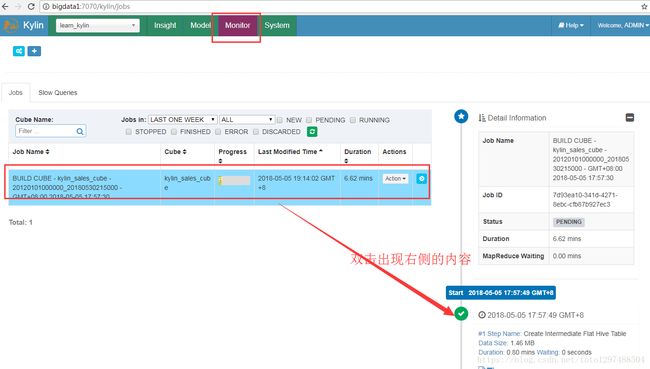
点开有下角显示的log。可以看到日志:
Exception: java.net.ConnectException: Call From bigdata1/192.168.18.140 to 0.0.0.0:10020 failed on connection exception: java.net.ConnectException: 拒绝连接; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
java.net.ConnectException: Call From bigdata1/192.168.18.140 to 0.0.0.0:10020 failed on connection exception: java.net.ConnectException: 拒绝连接; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused解决办法是启动historyserver:
$HADOOP_HOME/sbin/mr-jobhistory-daemon.sh start historyserver25.2.2.通过使用Streaming Sample Cube快速入门
1.首先设置KAFKA_HOME的环境变量。启动kylin
2.运行 KYLINHOME/bin/sample.sh,它将在learnkylin中生成表DEFAULT.KYLINSTREAMINGTABLE,模型kylinstreamingmodel,立方体kylinstreamingcube3.运行 K Y L I N H O M E / b i n / s a m p l e . s h , 它 将 在 l e a r n k y l i n 中 生 成 表 D E F A U L T . K Y L I N S T R E A M I N G T A B L E , 模 型 k y l i n s t r e a m i n g m o d e l , 立 方 体 k y l i n s t r e a m i n g c u b e 3. 运 行 {KYLIN_HOME}/bin/sample-streaming.sh,它将在本地的localhost:9092 broker创建Kafka的topic:kylin_streaming_topic.此外随机每秒生成100条消息发送到kylin_streaming_topic中。
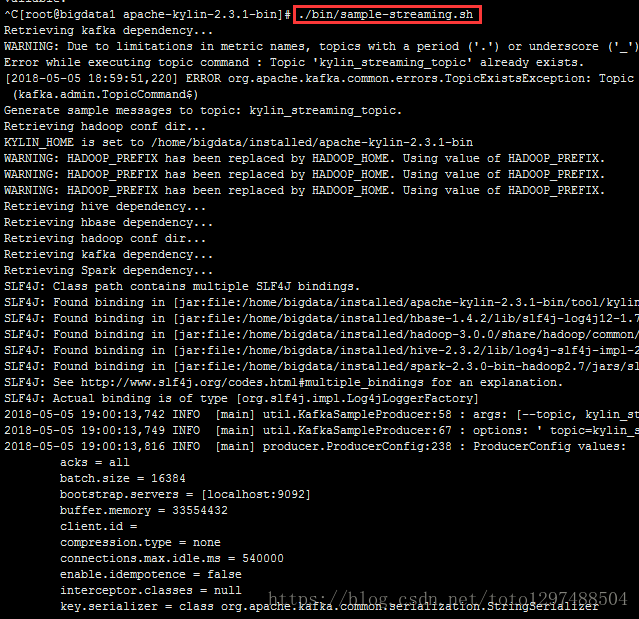
4.到Monitor的tab标签页,查看最近的一个job,查看是否是100%。
5.在Insight的tab页执行:
select count(*), HOUR_START from kylin_streaming_table group by HOUR_START
6、可以到hive中进行验证这些过程。