sqlserver 聚集索引和非聚集索引实例
参考文章:sqlserver 聚集索引和非聚集索引实例
数据库:twt001
数据表:aclu
use twt001
go
create table aclu
(
A int not null,
B char(10),
C varchar(10)
)
go
insert into aclu
select 1,'B','C'
union
select 5,'B','C'
union
select 7,'B','C'
union
select 9,'B','C'
go
在aclu表上创建聚集索引
create clustered index CLU_ABC
on aclu(A)
GO
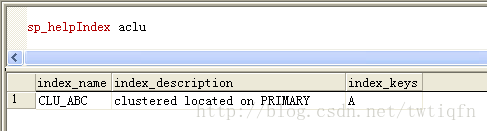
查看索引
sp_helpIndex aclu
运行如下:
再次插入数据
insert into aclu
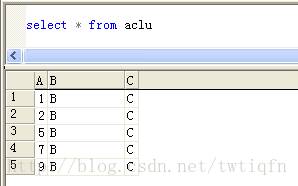
values(2,'B','C') 因为有聚集索引所以整个表的物理结构发生了变化,此时按照该索引查询的内容为:
select * from aclu WITH(index = CLU_ABC) WHERE A>1 AND A<5 
这一条记录插入到了第一条记录的后面,而不是整个表的最后:
删除索引:
Drop index aclu.CLU_ABC
查询内容物理顺序还是按照顺序的,跟上图一样。
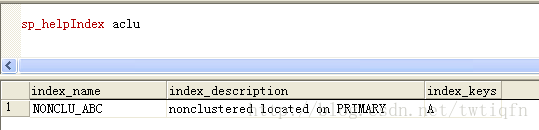
在aclu表上创建非聚集索引
create nonclustered index NONCLU_ABC
on aclu(A)
查看索引
插入数据
insert into aclu
values(4,'B','C')
此时表内容如下:
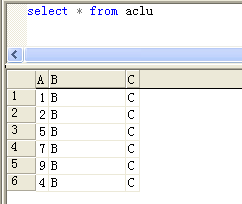
因为没有聚集索引,所以整个表的物理结构没有发生变化
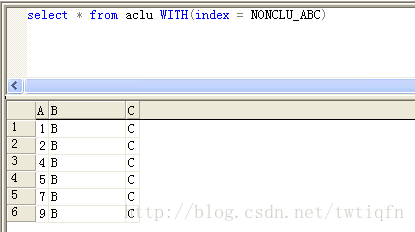
以下查询的内容为:
select * from aclu WITH(index = NONCLU_ABC)
删除索引后
Drop index aclu.NONCLU_ABC
查询内容物理顺序是按照插入的顺序